Automated decision making within the computer based only on the data.
A requirement to better understand our own subjective biases to ensure that the human to computer interface formulates the correct conclusions from the data.
Particularly important where treatments are being prescribed.
But what is a treatment in the modern era: interventions could be far more subtle.
Societal Effects
Shift in dynamic from the direct pathway between human and data to indirect pathway between human and data via the computer
This change of dynamics gives us the modern and emerging domain of data science
Challenges
Paradoxes of the Data Society
Quantifying the Value of Data
Privacy, loss of control, marginalization
Breadth vs Depth Paradox
Able to quantify to a greater and greater degree the actions of individuals
But less able to characterize society
As we measure more, we understand less
What?
Perhaps greater preponderance of data is making society itself more complex
Therefore traditional approaches to measurement are failing
Curate’s egg of a society: it is only ‘measured in parts’
Wood or Tree
Can either see a wood or a tree.
Examples
Election polls (UK 2015 elections, EU referendum, US 2016 elections)
Clinical trials vs personalized medicine: Obtaining statistical power where interventions are subtle. e.g. social media
Also need
More classical statistics!
Like the ‘paperless office’
A better characterization of human (see later)
Larger studies (100,000 genome)
Combined with complex models: algorithmic challenges
Quantifying the Value of Data
There’s a sea of data, but most of it is undrinkable
We require data-desalination before it can be consumed!
Data
90% of our time is spent on validation and integration (Leo Anthony Celi)
“The Dirty Work We Don’t Want to Think About” (Eric Xing)
“Voodoo to get it decompressed” (Francisco Giminez?)
In health care clinicians collect the data and often control the direction of research through guardianship of data.
Value
How do we measure value in the data economy?
How do we encourage data workers: curation and management
Incentivization for sharing and production.
Quantifying the value in the contribution of each actor.
Credit Allocation
Direct work on data generates an enormous amount of ‘value’ in the data economy but this is unaccounted in the economy
We have a dataset in which the inputs, \(\mathbf{X}\), are public. The outputs, \(\mathbf{y}\), we want to keep private.
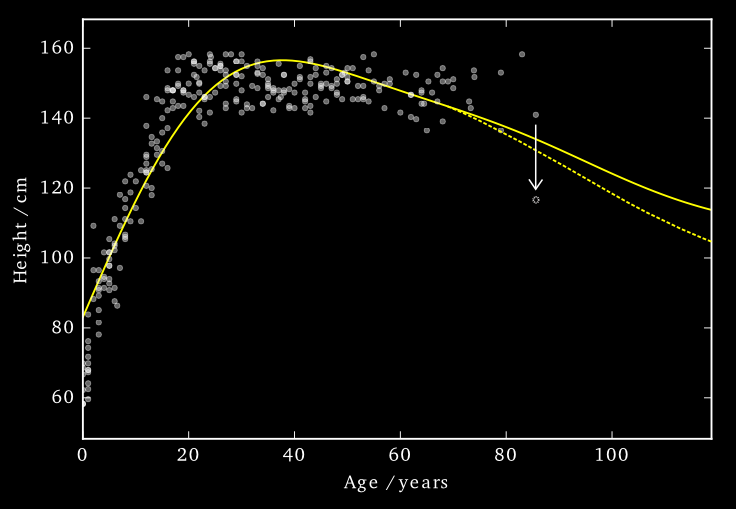
Data consists of the heights and weights of 287 women from a census of the !Kung
Data consists of the heights and weights of 287 women from a census of the !Kung
Vectors and Functions
Hall et al. (2013) showed that one can ensure that a version of \(f\), function \(\tilde{f}\) is \((\varepsilon, \delta)\)-differentially private by adding a scaled sample from a GP prior.
3 pages of maths ahead!
Applied to Gaussian Processes
We applied this method to the GP posterior.
The covariance of the posterior only depends on the inputs, \(X\). So we can compute this without applying DP.
The mean function, \(f_D(\mathbf{x_*})\), does depend on \(\mathbf{y}\). \[f_D(\mathbf{x_*}) = \mathbf{k}(x_*, \mathbf{X})
\mathbf{K}^{-1} \mathbf{y}\]
where \(\boldsymbol{\alpha} - \boldsymbol{\alpha}^\prime = \mathbf{K}^{-1} \left(\mathbf{y} - \mathbf{y}^\prime \right)\)
We constrain the kernel: \(-1\leq k(\cdot,\cdot) \leq 1\) and we only allow one element of \(\mathbf{y}\) and \(\mathbf{y}'\) to differ (by at most \(d\)).
So only one column of \(\mathbf{K}^{-1}\) will be involved in the change of mean (which we are summing over).
The distance above can then be shown to be no greater than \(d\;||\mathbf{K}^{-1}||_\infty\)
Applied to Gaussian Processes
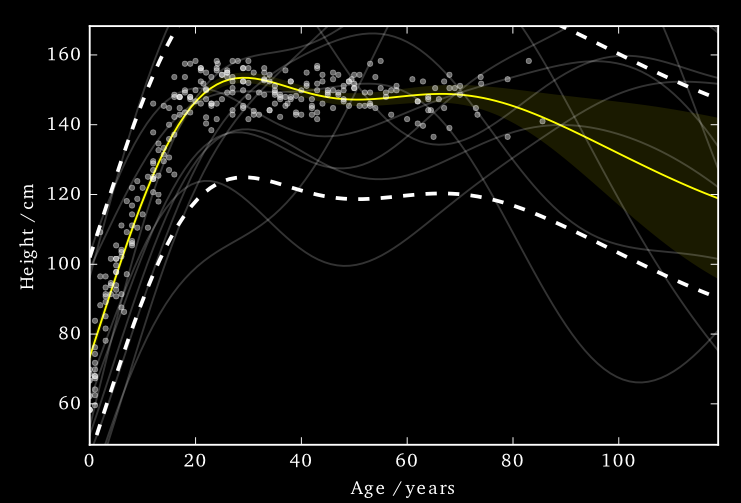
This ‘works’ in that it allows DP predictions…but to avoid too much noise, the value of \(\varepsilon\) is too large (here it is 100)
EQ kernel, \(\ell = 25\) years, \(\Delta=100\)cm
Inducing Inputs
Using sparse methods (i.e. inducing inputs) can help reduce the sensitivity a little. We’ll see more on this later.
Cloaking
So far we’ve made the whole posterior mean function private…
…what if we just concentrate on making particular predictions private?
Effect of perturbation
Standard approach: sample the noise is from the GP’s prior.
Not necessarily the most ‘efficient’ covariance to use.
Cloaking
Left: Function change. Right: test point change
Cloaking
Left: Function change. Right: test point change
Cloaking
Left: Function change. Right: test point change
Cloaking
Left: Function change. Right: test point change
Cloaking
Left: Function change. Right: test point change
Cloaking
Left: Function change. Right: test point change
DP Vectors
Hall et al. (2013) also presented a bound on vectors.
Find a bound (\(\Delta\)) on the scale of the output change, in term of its Mahalanobis distance (wrt the added noise covariance).
Intuitively we want to construct \(\mathbf{M}\) so that it has greatest covariance in those directions most affected by changes in training points, so that it will be most able to mask those changes.










 lengthscale in degrees, values above, journey duration (in seconds)
lengthscale in degrees, values above, journey duration (in seconds)


