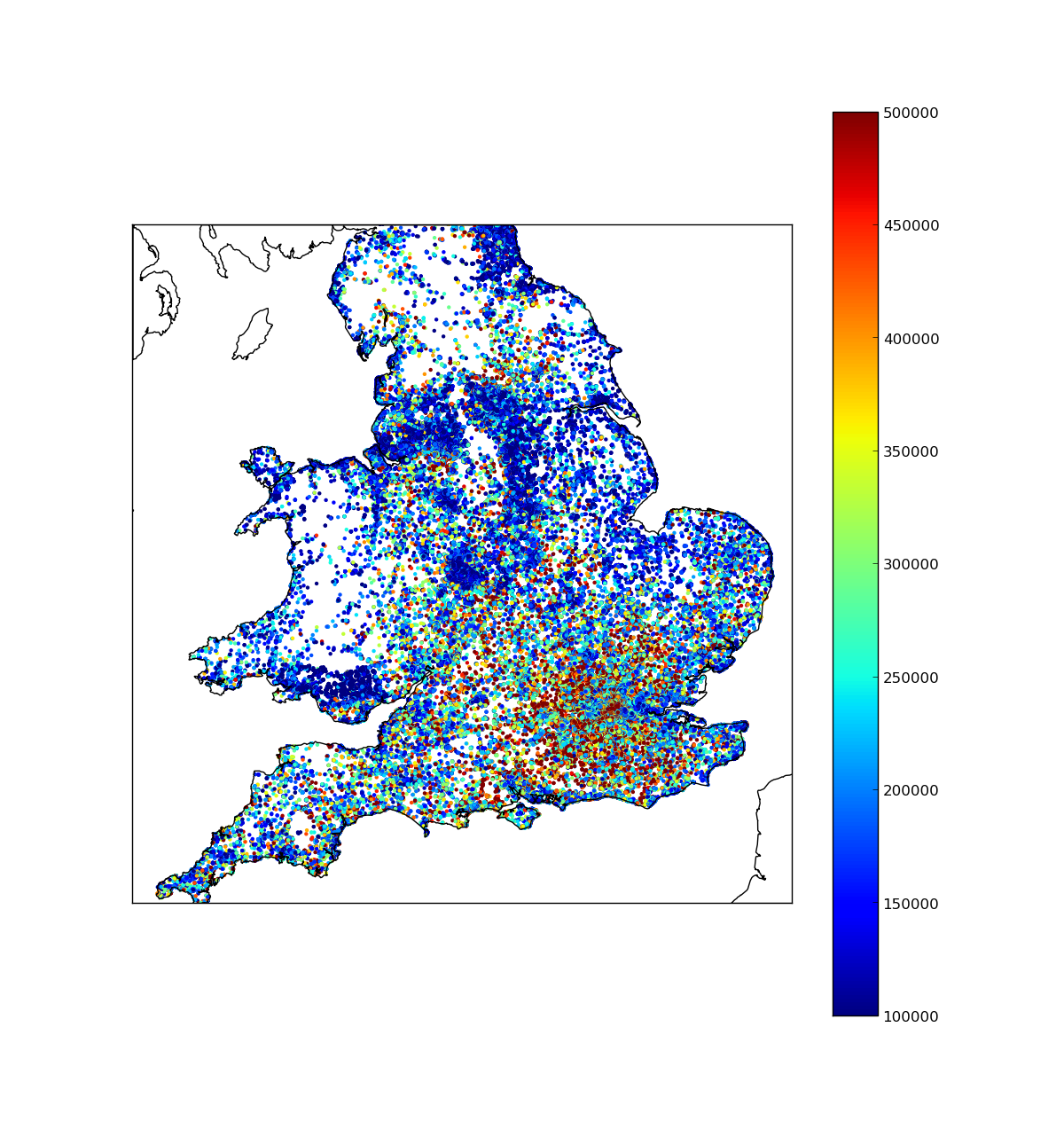
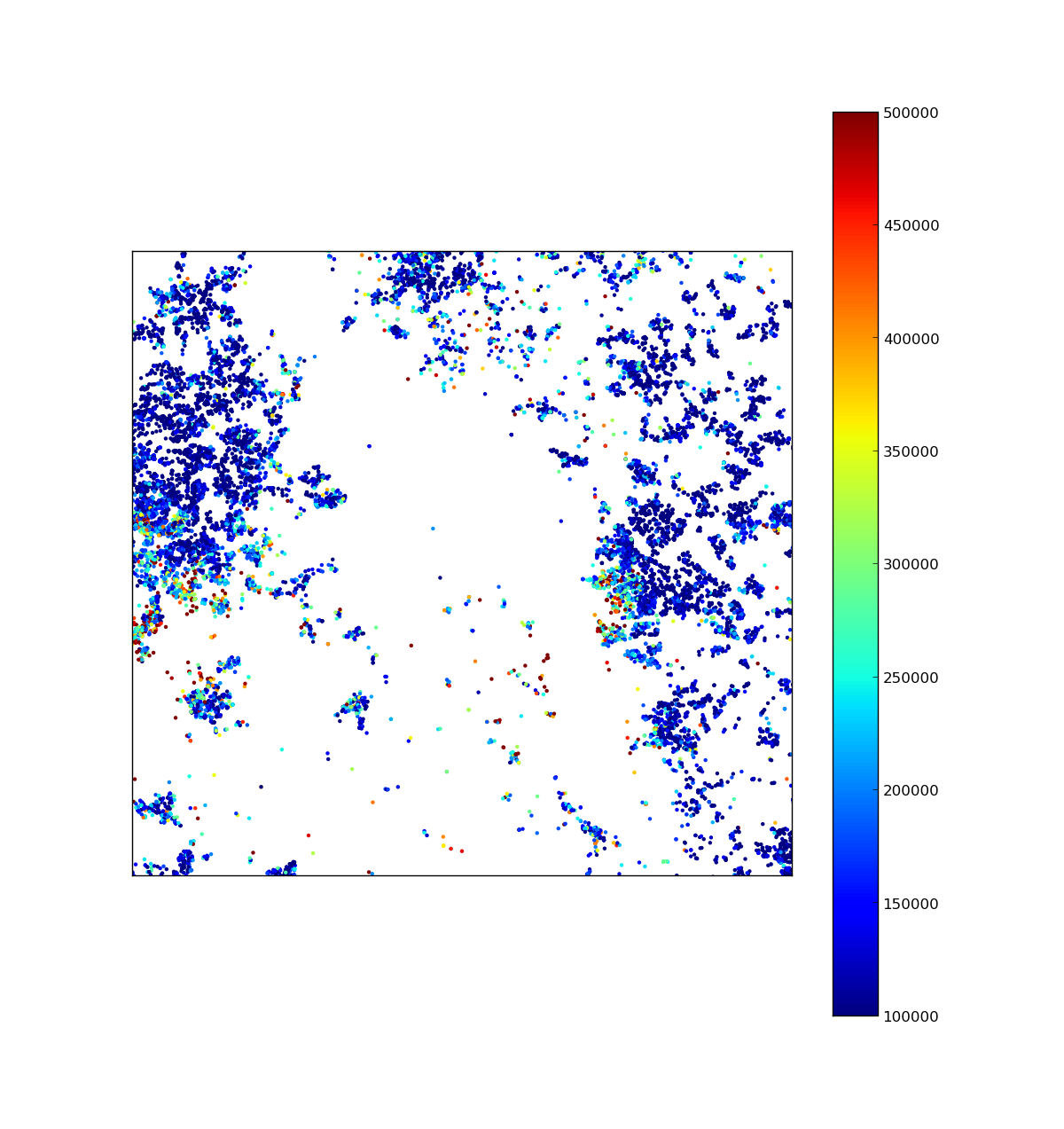
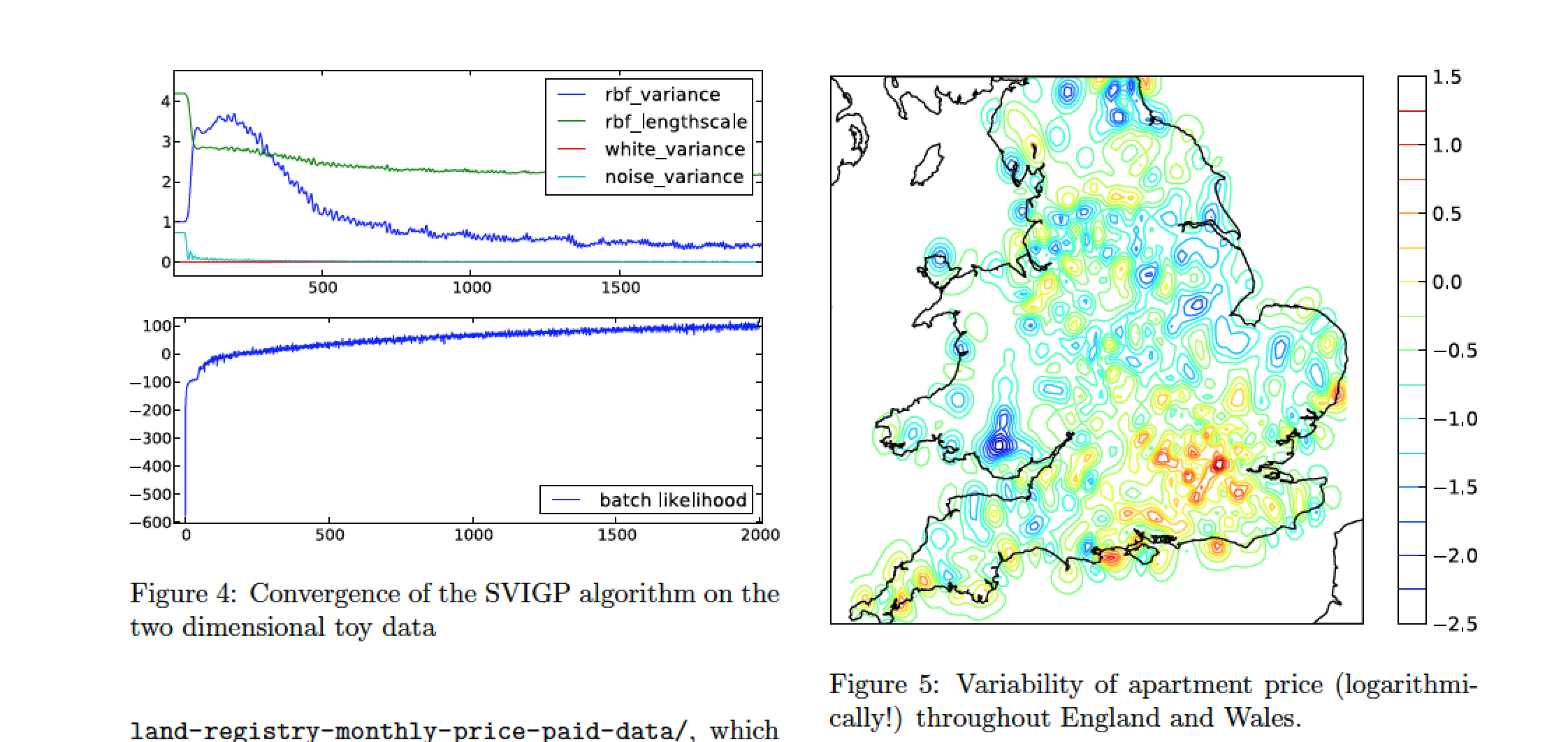
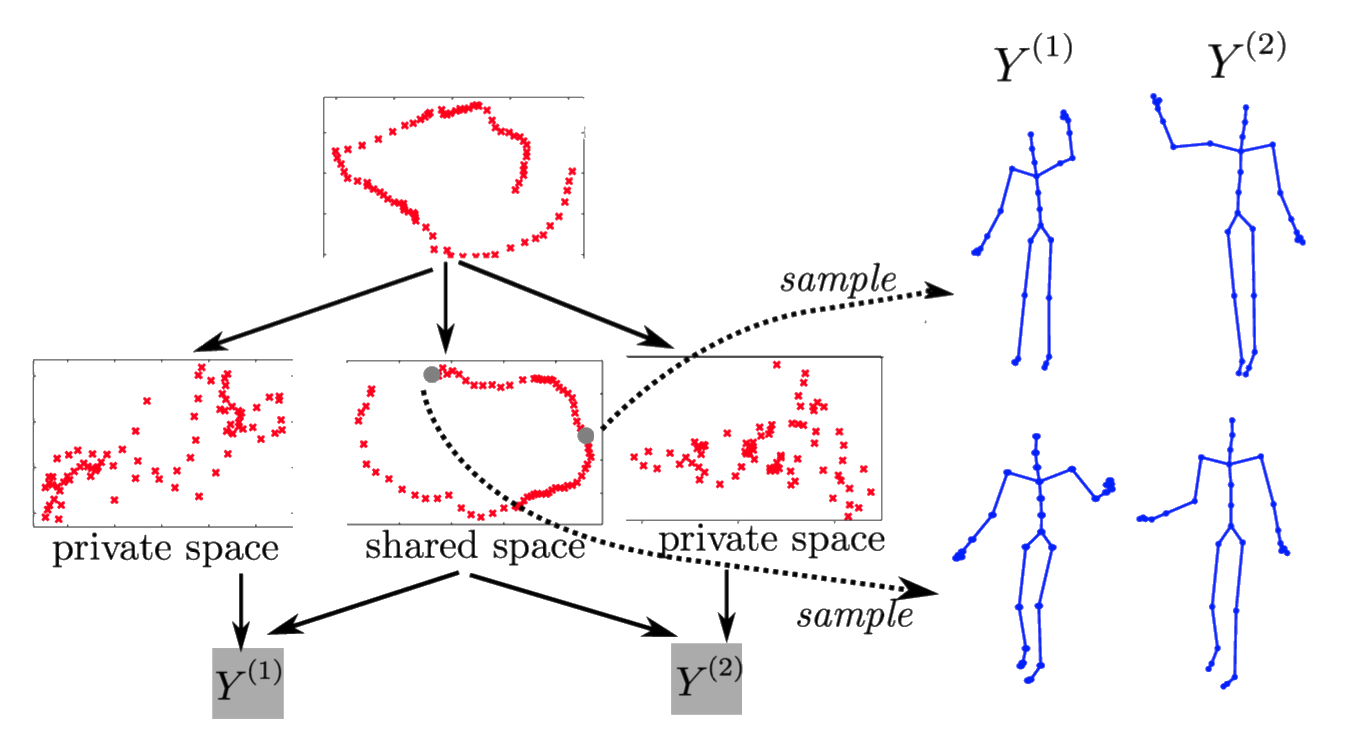
Alaa, A.M., van der Schaar, M., 2017. Deep multi-task Gaussian processes for survival analysis with competing risks, in: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (Eds.), Advances in Neural Information Processing Systems 30. Curran Associates, Inc., pp. 2326–2334.
Álvarez, M.A., Luengo, D., Titsias, M.K., Lawrence, N.D., 2010. Efficient multioutput Gaussian processes through variational inducing kernels, in:. pp. 25–32.
Bui, T.D., Yan, J., Turner, R.E., 2017. A unifying framework for Gaussian process pseudo-point approximations using power expectation propagation. Journal of Machine Learning Research 18, 1–72.
Dai, Z., Damianou, A., Hensman, J., Lawrence, N.D., 2014. Gaussian process models with parallelization and GPU acceleration.
Damianou, A., 2015. Deep Gaussian processes and variational propagation of uncertainty (PhD thesis). University of Sheffield.
Della Gatta, G., Bansal, M., Ambesi-Impiombato, A., Antonini, D., Missero, C., Bernardo, D. di, 2008. Direct targets of the trp63 transcription factor revealed by a combination of gene expression profiling and reverse engineering. Genome Research 18, 939–948. https://doi.org/10.1101/gr.073601.107
Dunlop, M.M., Girolami, M.A., Stuart, A.M., Teckentrup, A.L., n.d. How deep are deep Gaussian processes? Journal of Machine Learning Research 19, 1–46.
Duvenaud, D., Rippel, O., Adams, R., Ghahramani, Z., 2014. Avoiding pathologies in very deep networks, in:.
Gal, Y., Wilk, M. van der, Rasmussen, C.E., n.d. Distributed variational inference in sparse Gaussian process regression and latent variable models, in:.
Hensman, J., Fusi, N., Lawrence, N.D., n.d. Gaussian processes for big data, in:.
Hinton, G.E., Osindero, S., 2006. A fast learning algorithm for deep belief nets. Neural Computation 18, 2006.
Hoffman, M., Blei, D.M., Wang, C., Paisley, J., 2012. Stochastic variational inference, arXiv preprint arXiv:1206.7051.
Kalaitzis, A.A., Lawrence, N.D., 2011. A simple approach to ranking differentially expressed gene expression time courses through Gaussian process regression. BMC Bioinformatics 12. https://doi.org/10.1186/1471-2105-12-180
Lawrence, N.D., n.d. Learning for larger datasets with the Gaussian process latent variable model, in:. pp. 243–250.
MacKay, D.J.C., n.d. Introduction to Gaussian processes, in:. pp. 133–166.
Mattos, C.L.C., Dai, Z., Damianou, A.C., Forth, J., Barreto, G.A., Lawrence, N.D., 2015. Recurrent gaussian processes. CoRR abs/1511.06644.
Quiñonero Candela, J., Rasmussen, C.E., 2005. A unifying view of sparse approximate Gaussian process regression. Journal of Machine Learning Research 6, 1939–1959.
Ranganath, R., Perotte, A., Elhadad, N., Blei, D., 2016. Deep survival analysis, in: Doshi-Velez, F., Fackler, J., Kale, D., Wallace, B., Wiens, J. (Eds.), Proceedings of the 1st Machine Learning for Healthcare Conference, Proceedings of Machine Learning Research. PMLR, Children’s Hospital LA, Los Angeles, CA, USA, pp. 101–114.
Salakhutdinov, R., Murray, I., n.d. On the quantitative analysis of deep belief networks, in:. pp. 872–879.
Salimbeni, H., Deisenroth, M., 2017. Doubly stochastic variational inference for deep Gaussian processes, in: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (Eds.), Advances in Neural Information Processing Systems 30. Curran Associates, Inc., pp. 4591–4602.
Saul, A.D., 2016. Gaussian process based approaches for survival analysis (PhD thesis). University of Sheffield.
Schulam, P., Saria, S., 2017. Counterfactual Gaussian processes for reliable decision-making and what-if reasoning, in: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (Eds.), Advances in Neural Information Processing Systems 30. Curran Associates, Inc., pp. 1696–1706.
Seeger, M.W., Hetzel, A., Dai, Z., Lawrence, N.D., 2017. Auto-differentiating linear algebra. CoRR abs/1710.08717.
Snelson, E., Ghahramani, Z., n.d. Sparse Gaussian processes using pseudo-inputs, in:.
Taigman, Y., Yang, M., Ranzato, M., Wolf, L., 2014. DeepFace: Closing the gap to human-level performance in face verification, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2014.220
Titsias, M.K., n.d. Variational learning of inducing variables in sparse Gaussian processes, in:. pp. 567–574.
Wu, A., Roy, N.G., Keeley, S., Pillow, J.W., 2017. Gaussian process based nonlinear latent structure discovery in multivariate spike train data, in: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (Eds.), Advances in Neural Information Processing Systems 30. Curran Associates, Inc., pp. 3499–3508.
 \(=f\Bigg(\)
\(=f\Bigg(\)