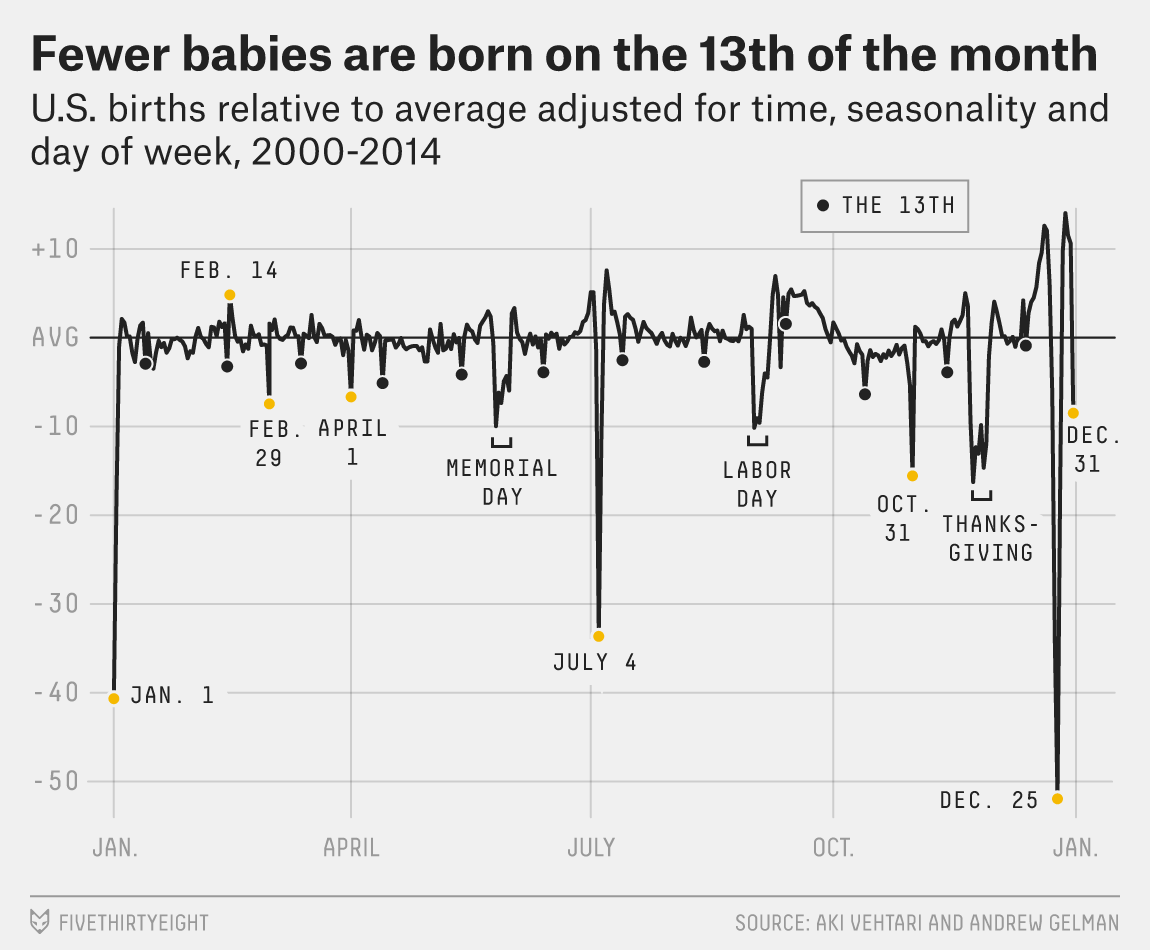
What is Machine Learning?
Data Science Africa Summer School, Addis Ababa, Ethiopia
Introduction
Data Science Africa is a bottom up initiative for capacity building in data science, machine learning and AI on the African continent

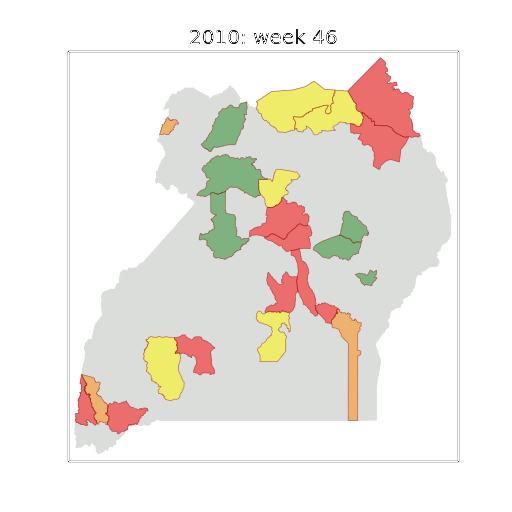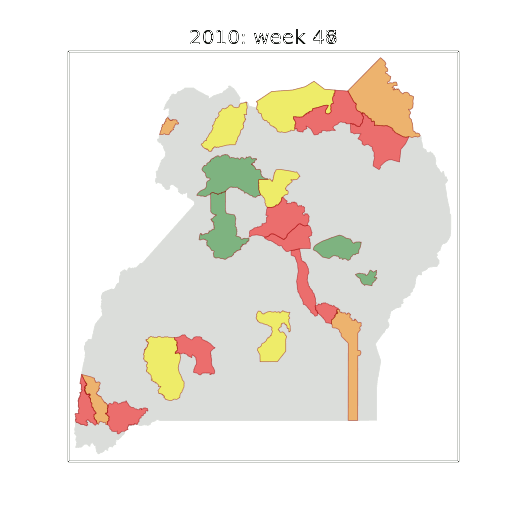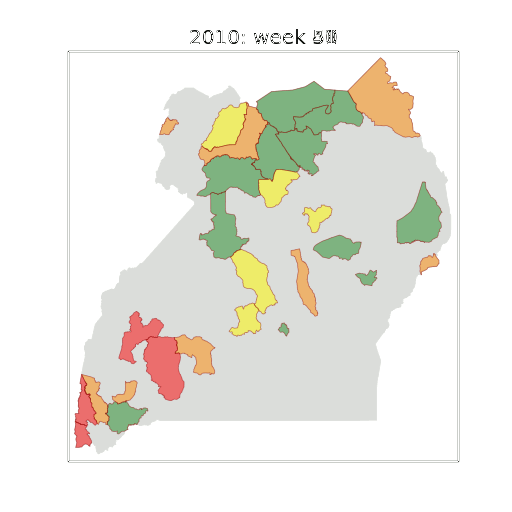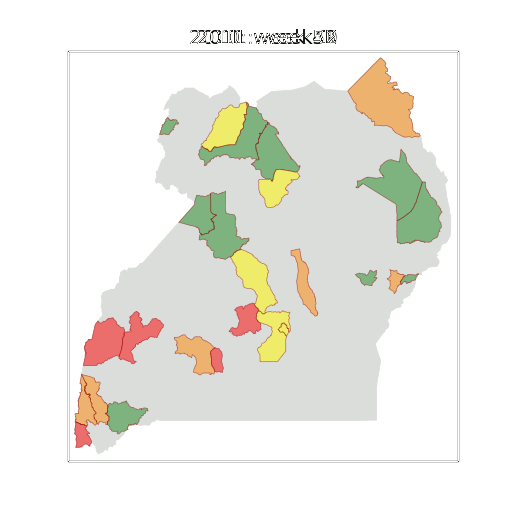
Example: Prediction of Malaria Incidence in Uganda

- Work with Ricardo Andrade Pacheco, John Quinn and Martin Mubaganzi (Makerere University, Uganda)
- See AI-DEV Group.
Malaria Prediction in Uganda
(Andrade-Pacheco et al., 2014; Mubangizi et al., 2014)
Tororo District
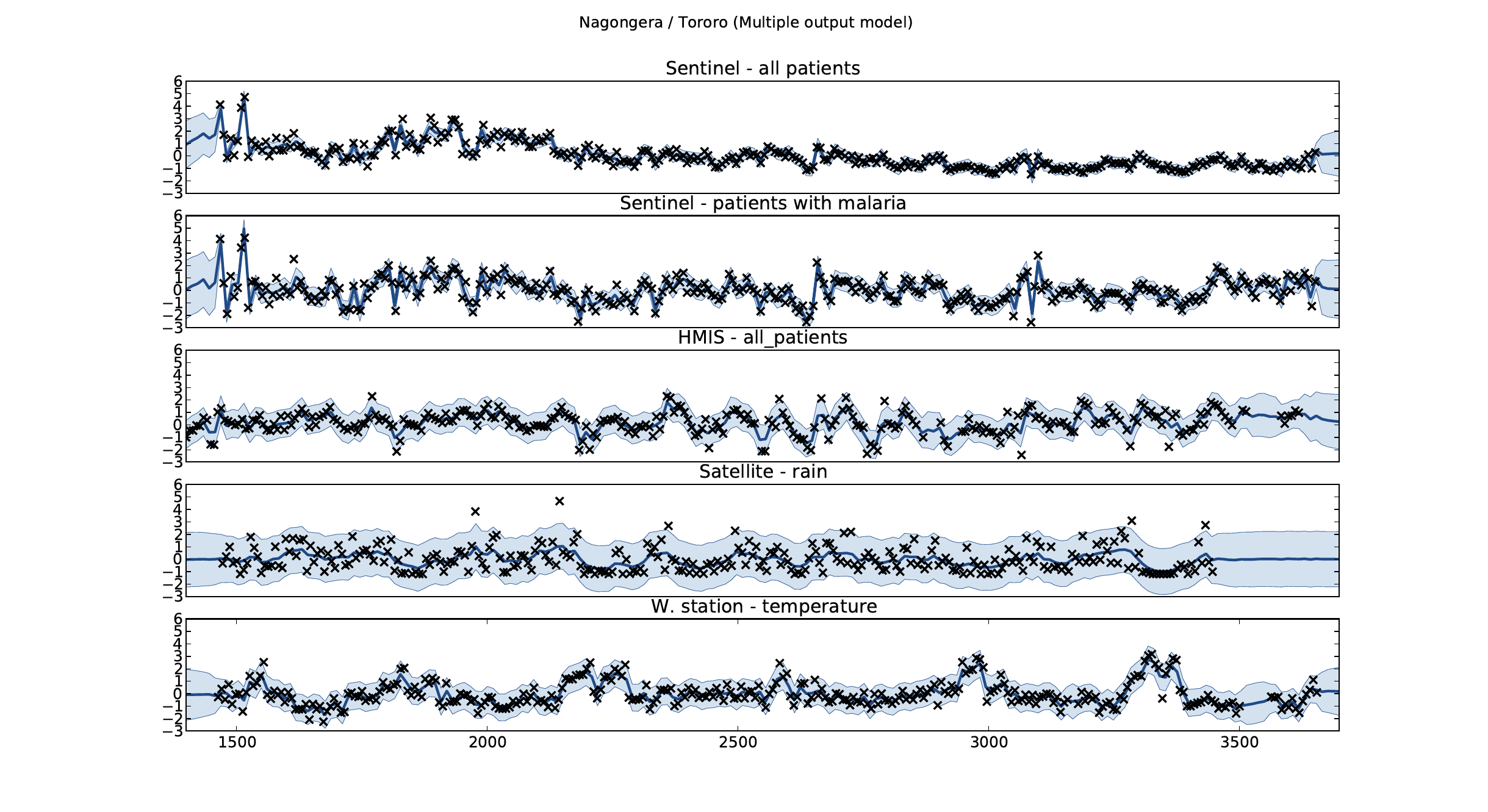
Malaria Prediction in Nagongera (Sentinel Site)
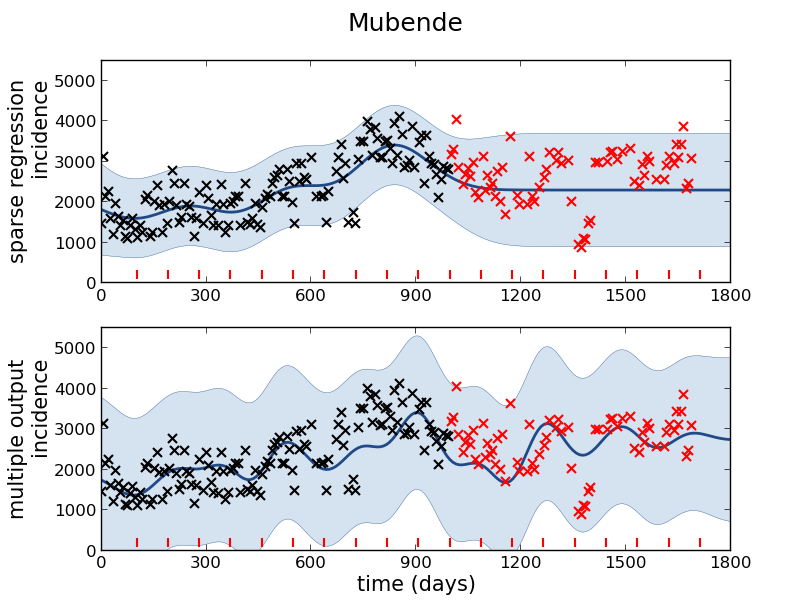
Mubende District
Malaria Prediction in Uganda
GP School at Makerere

Kabarole District
Early Warning System
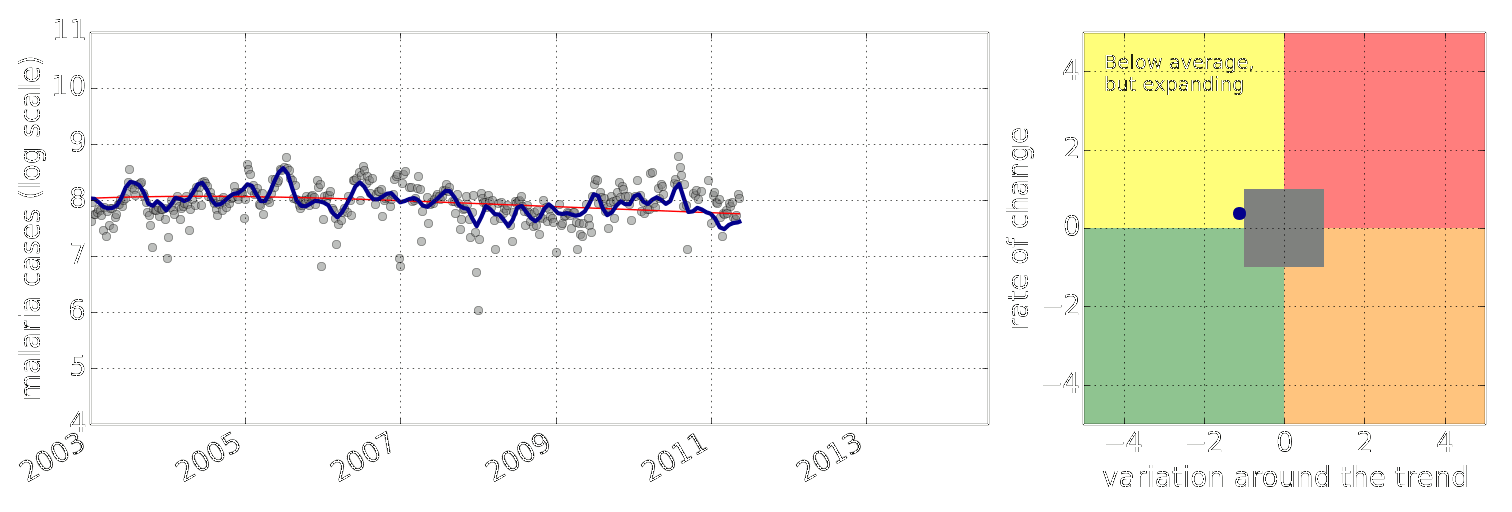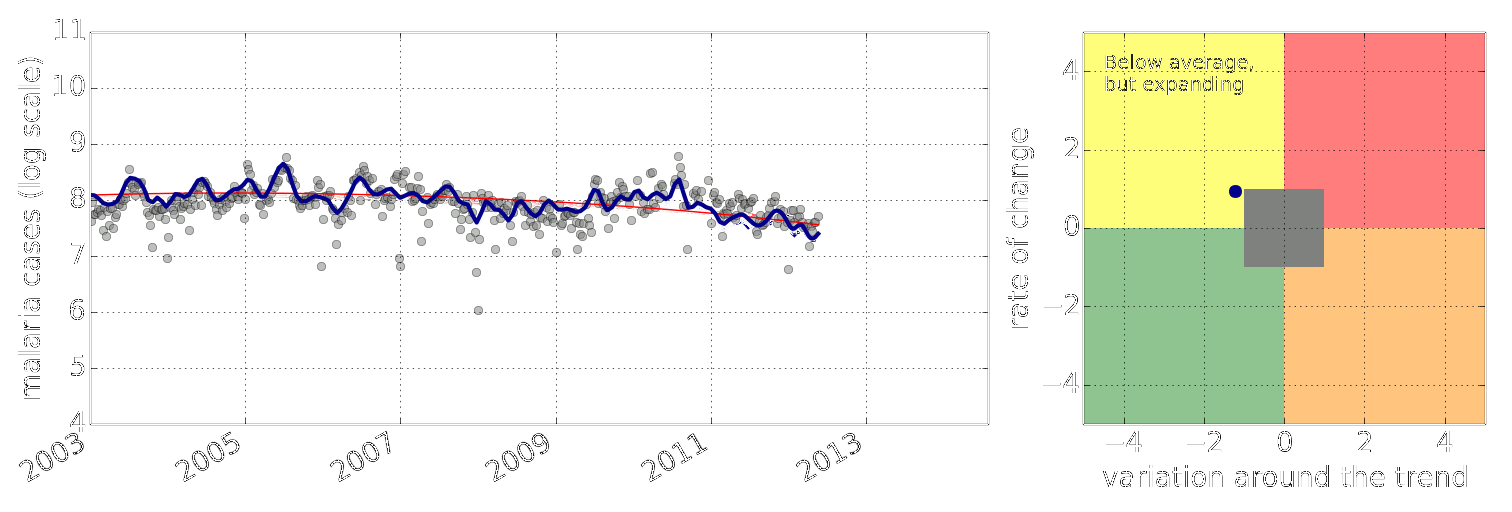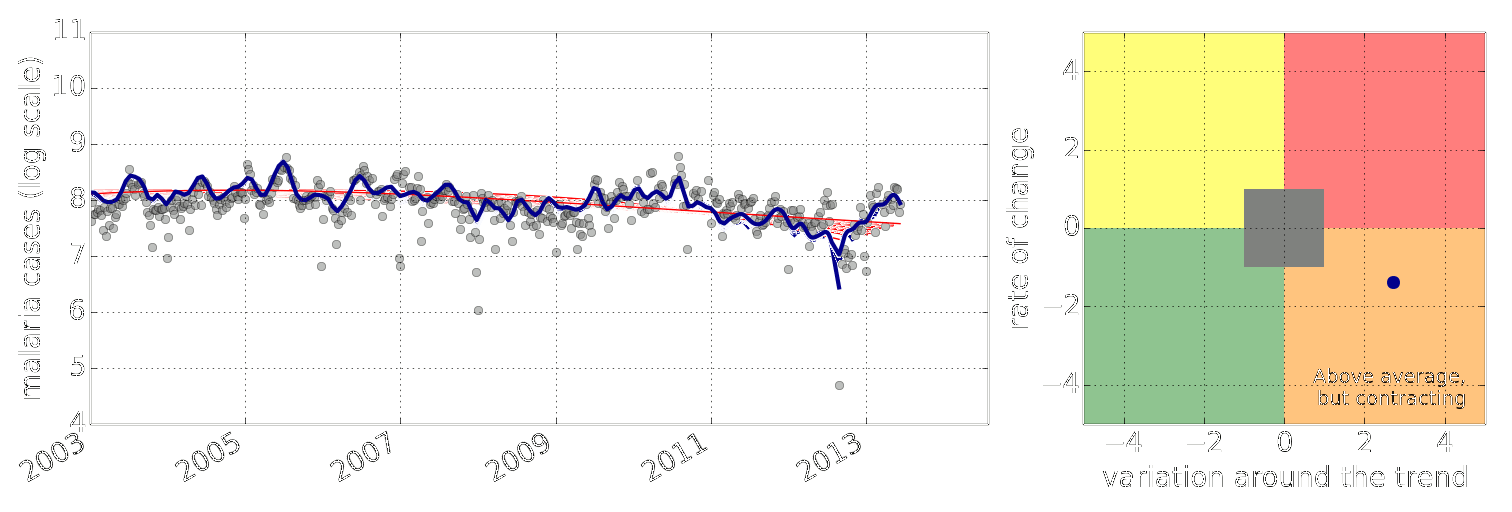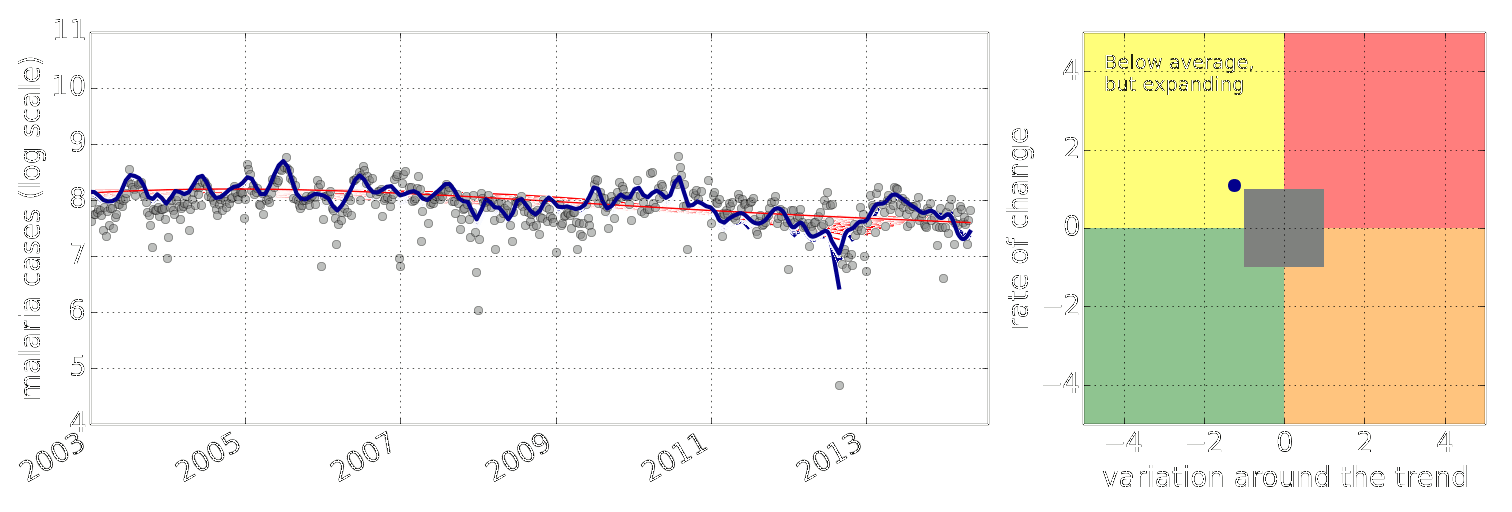
Early Warning Systems
Machine Learning
Rise of Machine Learning
- Driven by data and computation
- Fundamentally dependent on models
\[ \text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction} \]
Data Revolution
Supply Chain

Cromford


Deep Freeze

Deep Freeze

Machine Learning in Supply Chain
- Supply chain: Large Automated Decision Making Network
- Major Challenge:
- We have a mechanistic understanding of supply chain.
- Machine learning is a data driven technology.
For Africa
- Infrastructure dominated by information.
Data Driven
- Machine Learning: Replicate Processes through direct use of data.
- Aim to emulate cognitive processes through the use of data.
- Use data to provide new approaches in control and optimization that should allow for emulation of human motor skills.
Process Emulation
- Key idea: emulate the process as a mathematical function.
- Each function has a set of parameters which control its behaviour.
- Learning is the process of changing these parameters to change the shape of the function
- Choice of which class of mathematical functions we use is a vital component of our model.
Kapchorwa District
Olympic Marathon Data
|

|
Olympic Marathon Data
Polynomial Fits to Olympic Data
What does Machine Learning do?
- Automation scales by codifying processes and automating them.
- Need:
- Interconnected components
- Compatible components
- Early examples:
- cf Colt 45, Ford Model T
Codify Through Mathematical Functions
- How does machine learning work?
- Jumper (jersey/sweater) purchase with logistic regression
\[ \text{odds} = \frac{p(\text{bought})}{p(\text{not bought})} \]
\[ \log \text{odds} = \beta_0 + \beta_1 \text{age} + \beta_2 \text{latitude}.\]
Codify Through Mathematical Functions
- How does machine learning work?
- Jumper (jersey/sweater) purchase with logistic regression
\[ p(\text{bought}) = \sigmoid{\beta_0 + \beta_1 \text{age} + \beta_2 \text{latitude}}.\]
Codify Through Mathematical Functions
- How does machine learning work?
- Jumper (jersey/sweater) purchase with logistic regression
\[ p(\text{bought}) = \sigmoid{\boldsymbol{\beta}^\top \inputVector}.\]
Codify Through Mathematical Functions
- How does machine learning work?
- Jumper (jersey/sweater) purchase with logistic regression
\[ \dataScalar = \mappingFunction\left(\inputVector, \boldsymbol{\beta}\right).\]
We call \(\mappingFunction(\cdot)\) the prediction function.
Fit to Data
- Use an objective function
\[\errorFunction(\boldsymbol{\beta}, \dataMatrix, \inputMatrix)\]
- E.g. least squares \[\errorFunction(\boldsymbol{\beta}, \dataMatrix, \inputMatrix) = \sum_{i=1}^\numData \left(\dataScalar_i - \mappingFunction(\inputVector_i, \boldsymbol{\beta})\right)^2.\]
Two Components
- Prediction function, \(\mappingFunction(\cdot)\)
- Objective function, \(\errorFunction(\cdot)\)
\[\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction}\]
From Model to Decision

|
\[\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction}\] |
Artificial Intelligence and Data Science
- AI aims to equip computers with human capabilities
- Image understanding
- Computer vision
- Speech recognition
- Natural language understanding
- Machine translation
Supervised Learning for AI
- Dominant approach today:
- Generate large labelled data set from humans.
- Use supervised learning to emulate that data.
- E.g. ImageNet Russakovsky et al. (2015)
- Significant advances due to deep learning
- E.g. Alexa, Amazon Go
Data Science
- Arises from happenstance data.
- Differs from statistics in that the question comes after data collection.
Neural Networks and Prediction Functions
- adaptive non-linear function models inspired by simple neuron models (McCulloch and Pitts, 1943)
- have become popular because of their ability to model data.
- can be composed to form highly complex functions
- start by focussing on one hidden layer
Prediction Function of One Hidden Layer
\[ \mappingFunction(\inputVector) = \left.\mappingVector^{(2)}\right.^\top \activationVector(\mappingMatrix_{1}, \inputVector) \]
\(\mappingFunction(\cdot)\) is a scalar function with vector inputs,
\(\activationVector(\cdot)\) is a vector function with vector inputs.
dimensionality of the vector function is known as the number of hidden units, or the number of neurons.
elements of \(\activationVector(\cdot)\) are the activation function of the neural network
elements of \(\mappingMatrix_{1}\) are the parameters of the activation functions.
Relations with Classical Statistics
In statistics activation functions are known as basis functions.
would think of this as a linear model: not linear predictions, linear in the parameters
\(\mappingVector_{1}\) are static parameters.
Adaptive Basis Functions
- In machine learning we optimize \(\mappingMatrix_{1}\) as well as \(\mappingMatrix_{2}\) (which would normally be denoted in statistics by \(\boldsymbol{\beta}\)).
Machine Learning
- observe a system in practice
- emulate its behavior with mathematics.
- Design challenge: where to put mathematical function.
- Where it’s placed leads to different ML domains.
Types of Machine Learning
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Types of Machine Learning
- Supervised learning
Unsupervised learningReinforcement learning
Supervised Learning
Supervised Learning
- Widley deployed
- Particularly in classification.
- Input is e.g. image
- Output is class label (e.g. dog or cat).
Introduction to Classification
Classification
- Wake word classification (Global Pulse Project).
Breakthrough in 2012 with ImageNet result of Alex Krizhevsky, Ilya Sutskever and Geoff Hinton
- We are given a data set containing ‘inputs’, \(\inputMatrix\) and ‘targets’, \(\dataVector\).
- Each data point consists of an input vector \(\inputVector_i\) and a class label, \(\dataScalar_i\).
- For binary classification assume \(\dataScalar_i\) should be either \(1\) (yes) or \(-1\) (no).
Input vector can be thought of as features.
Discrete Probability
- Algorithms based on prediction function and objective function.
- For regression the codomain of the functions, \(f(\inputMatrix)\) was the real numbers or sometimes real vectors.
- In classification we are given an input vector, \(\inputVector\), and an associated label, \(\dataScalar\) which either takes the value \(-1\) or \(1\).
Classification
- Inputs, \(\inputVector\), mapped to a label, \(\dataScalar\), through a function \(\mappingFunction(\cdot)\) dependent on parameters, \(\weightVector\), \[ \dataScalar = \mappingFunction(\inputVector; \weightVector). \]
- \(\mappingFunction(\cdot)\) is known as the prediction function.
Classification Examples
- Classifiying hand written digits from binary images (automatic zip code reading)
- Detecting faces in images (e.g. digital cameras).
- Who a detected face belongs to (e.g. Facebook, DeepFace)
- Classifying type of cancer given gene expression data.
- Categorization of document types (different types of news article on the internet)
Perceptron
Simple classification with the perceptron algorithm.
Logistic Regression and GLMs
- Modelling entire density allows any question to be answered (also missing data).
- Comes at the possible expense of strong assumptions about data generation distribution.
- In regression we model probability of \(\dataScalar_i |\inputVector_i\) directly.
- Allows less flexibility in the question, but more flexibility in the model assumptions.
- Can do this not just for regression, but classification.
- Framework is known as generalized linear models.
Log Odds
- model the log-odds with the basis functions.
- odds are defined as the ratio of the probability of a positive outcome, to the probability of a negative outcome.
- Probability is between zero and one, odds are: \[ \frac{\pi}{1-\pi} \]
- Odds are between \(0\) and \(\infty\).
- Logarithm of odds maps them to \(-\infty\) to \(\infty\).
Logit Link Function
- The Logit function, \[g^{-1}(\pi_i) = \log\frac{\pi_i}{1-\pi_i}.\] This function is known as a link function.
- For a standard regression we take, \[f(\inputVector_i) = \mappingVector^\top \basisVector(\inputVector_i),\]
- For classification we perform a logistic regression. \[\log \frac{\pi_i}{1-\pi_i} = \mappingVector^\top \basisVector(\inputVector_i)\]
Inverse Link Function
We have defined the link function as taking the form \(g^{-1}(\cdot)\) implying that the inverse link function is given by \(g(\cdot)\). Since we have defined, \[ g^{-1}(\pi(\inputVector)) = \mappingVector^\top\basisVector(\inputVector) \] we can write \(\pi\) in terms of the inverse link function, \(g(\cdot)\) as \[ \pi(\inputVector) = g(\mappingVector^\top\basisVector(\inputVector)). \]
Logistic function
- Logistic (or sigmoid) squashes real line to between 0 & 1. Sometimes also called a ‘squashing function’.
Basis Function
Prediction Function
- Can now write \(\pi\) as a function of the input and the parameter vector as, \[\pi(\inputVector,\mappingVector) = \frac{1}{1+ \exp\left(-\mappingVector^\top \basisVector(\inputVector)\right)}.\]
- Compute the output of a standard linear basis function composition (\(\mappingVector^\top \basisVector(\inputVector)\), as we did for linear regression)
- Apply the inverse link function, \(g(\mappingVector^\top \basisVector(\inputVector))\).
- Use this value in a Bernoulli distribution to form the likelihood.
Bernoulli Reminder
From last time \[P(\dataScalar_i|\mappingVector, \inputVector) = \pi_i^{\dataScalar_i} (1-\pi_i)^{1-\dataScalar_i}\]
Trick for switching betwen probabilities
Maximum Likelihood
- Conditional independence of data: \[P(\dataVector|\mappingVector, \inputMatrix) = \prod_{i=1}^\numData P(\dataScalar_i|\mappingVector, \inputVector_i). \]
Log Likelihood
\[\begin{align*} \log P(\dataVector|\mappingVector, \inputMatrix) = & \sum_{i=1}^\numData \log P(\dataScalar_i|\mappingVector, \inputVector_i) \\ = &\sum_{i=1}^\numData \dataScalar_i \log \pi_i \\ & + \sum_{i=1}^\numData (1-\dataScalar_i)\log (1-\pi_i) \end{align*}\]
Objective Function
- Probability of positive outcome for the \(i\)th data point \[\pi_i = g\left(\mappingVector^\top \basisVector(\inputVector_i)\right),\] where \(g(\cdot)\) is the inverse link function
- Objective function of the form \[\begin{align*} E(\mappingVector) = & - \sum_{i=1}^\numData \dataScalar_i \log g\left(\mappingVector^\top \basisVector(\inputVector_i)\right) \\& - \sum_{i=1}^\numData(1-\dataScalar_i)\log \left(1-g\left(\mappingVector^\top \basisVector(\inputVector_i)\right)\right). \end{align*}\]
Minimize Objective
- Grdient wrt \(\pi(\inputVector;\mappingVector)\) \[\begin{align*} \frac{\text{d}E(\mappingVector)}{\text{d}\mappingVector} = & -\sum_{i=1}^\numData \frac{\dataScalar_i}{g\left(\mappingVector^\top \basisVector(\inputVector)\right)}\frac{\text{d}g(\mappingFunction_i)}{\text{d}\mappingFunction_i} \basisVector(\inputVector_i) \\ & + \sum_{i=1}^\numData \frac{1-\dataScalar_i}{1-g\left(\mappingVector^\top \basisVector(\inputVector)\right)}\frac{\text{d}g(\mappingFunction_i)}{\text{d}\mappingFunction_i} \basisVector(\inputVector_i) \end{align*}\]
Link Function Gradient
- Also need gradient of inverse link function wrt parameters. \[\begin{align*} g(\mappingFunction_i) &= \frac{1}{1+\exp(-\mappingFunction_i)}\\ &=(1+\exp(-\mappingFunction_i))^{-1} \end{align*}\] and the gradient can be computed as \[\begin{align*} \frac{\text{d}g(\mappingFunction_i)}{\text{d} \mappingFunction_i} & = \exp(-\mappingFunction_i)(1+\exp(-\mappingFunction_i))^{-2}\\ & = \frac{1}{1+\exp(-\mappingFunction_i)} \frac{\exp(-\mappingFunction_i)}{1+\exp(-\mappingFunction_i)} \\ & = g(\mappingFunction_i) (1-g(\mappingFunction_i)) \end{align*}\]
Objective Gradient
\[\begin{align*} \frac{\text{d}E(\mappingVector)}{\text{d}\mappingVector} = & -\sum_{i=1}^\numData \dataScalar_i\left(1-g\left(\mappingVector^\top \basisVector(\inputVector)\right)\right) \basisVector(\inputVector_i) \\ & + \sum_{i=1}^\numData (1-\dataScalar_i)\left(g\left(\mappingVector^\top \basisVector(\inputVector)\right)\right) \basisVector(\inputVector_i). \end{align*}\]
Optimization of the Function
- Can’t find a stationary point of the objective function analytically.
- Optimization has to proceed by numerical methods.
- Similarly to matrix factorization, for large data stochastic gradient descent (Robbins Munro (Robbins and Monro, 1951) optimization procedure) works well.
Batch Gradient Descent
Stochastic Gradient Descent
Regression
- Classification is discrete output.
- Regression is a continuous output.
Regression Examples
- Predict a real value, \(\dataScalar_i\) given some inputs \(\inputVector_i\).
- Predict quality of meat given spectral measurements (Tecator data).
- Radiocarbon dating, the C14 calibration curve: predict age given quantity of C14 isotope.
- Predict quality of different Go or Backgammon moves given expert rated training data.
Supervised Learning Challenges
- choosing which features, \(\inputVector\), are relevant in the prediction
- defining the appropriate class of function, \(\mappingFunction(\cdot)\).
- selecting the right parameters, \(\weightVector\).
Feature Selection
- Olympic prediction example only using year to predict pace.
- What else could we use?
- Can use feature selection algorithms
Applications
- rank search results, what adverts to show, newsfeed ranking
- Features: number of likes, image present, friendship relationship
Class of Function, \(\mappingFunction(\cdot)\)
- Mapping characteristic between \(\inputVector\) and \(\dataScalar\)?
- smooth (similar inputs lead to similar outputs).
- linear function.
- In forecasting, periodic
Gelman Book

|
|
Gelman et al. (2013)
Class of Function: Neural Networks
- ImageNet: convolutional neural network
- Convolutional neural network introduces invariances
Class of Function: Invariances
- An invariance is a transformation of the input
- e.g. a cat remains a cat regardless of location (translation), size (scale) or upside-down (rotation and reflection).
Deep Learning
Deep Learning
These are interpretable models: vital for disease modeling etc.
Modern machine learning methods are less interpretable
Example: face recognition
DeepFace
Outline of the DeepFace architecture. A front-end of a single convolution-pooling-convolution filtering on the rectified input, followed by three locally-connected layers and two fully-connected layers. Color illustrates feature maps produced at each layer. The net includes more than 120 million parameters, where more than 95% come from the local and fully connected.

Source: DeepFace (Taigman et al., 2014)
Deep Learning as Pinball

Encoding Knowledge
- Encode invariance is encoding knowledge
- Unspecified invariances must be learned
- Learning may require a lot more data.
- Less data efficient
Choosing Prediction Function
- Any function e.g. polynomials for olympic data \[ \mappingFunction(\inputScalar) = \weightScalar_0 + \weightScalar_1 \inputScalar+ \weightScalar_2 \inputScalar^2 + \weightScalar_3 \inputScalar^3 + \weightScalar_4 \inputScalar^4. \]
Parameter Estimation: Objective Functions
- After choosing features and function class we need parameters.
- Estimate \(\weightVector\) by specifying an objective function.
Labels and Squared Error
- Label comes from supervisor or annotator.
- For regression squared error, \[ \errorFunction(\weightVector) = \sum_{i=1}^\numData (\dataScalar_i - \mappingFunction(\inputVector_i))^2 \]
Data Provision
- Given \(\numData\) inputs, \(\inputVector_1\), \(\inputVector_2\), \(\inputVector_3\), \(\dots\), \(\inputVector_\numData\)
- And labels \(\dataScalar_1\), \(\dataScalar_2\), \(\dataScalar_3\), \(\dots\), \(\dataScalar_\numData\).
- Sometimes label is cheap e.g. Newsfeed ranking
- Often it is very expensive.
- Manual labour
Annotation
- Human annotators
- E.g. in ImageNet annotated using Amazon’s Mechanical Turk. (AI?)
- Without humans no AI.
- Not real intelligence, emulated
Annotation
- Some tasks easier to annotate than others.
- Sometimes annotation requires an experiment (Tecator data)
Annotation
- Even for easy tasks there will be problems.
- E.g. humans extrapolate the context of an image.
- Quality of ML is very sensitive to data.
- Investing in processes and tools is vital.
Misrepresentation and Bias
- Bias can appear in the model and the data
- Data needs to be carefully collected
- E.g. face detectors trained on Europeans tested in Africa.
Generalization and Overfitting
- How does the model perform on previously unseen data?
Validation and Model Selection
- Selecting model at the validation step
Difficult Trap
- Vital that you avoid test data in training.
- Validation data is different from test data.
Hold Out Validation on Olympic Marathon Data
Overfitting
- Increase number of basis functions we obtain a better ‘fit’ to the data.
- How will the model perform on previously unseen data?
- Let’s consider predicting the future.
Future Prediction: Extrapolation
Extrapolation
- Here we are training beyond where the model has learnt.
- This is known as extrapolation.
- Extrapolation is predicting into the future here, but could be:
- Predicting back to the unseen past (pre 1892)
- Spatial prediction (e.g. Cholera rates outside Manchester given rates inside Manchester).
Interpolation
- Predicting the wining time for 1946 Olympics is interpolation.
- This is because we have times from 1936 and 1948.
- If we want a model for interpolation how can we test it?
- One trick is to sample the validation set from throughout the data set.
Future Prediction: Interpolation
Choice of Validation Set
- The choice of validation set should reflect how you will use the model in practice.
- For extrapolation into the future we tried validating with data from the future.
- For interpolation we chose validation set from data.
- For different validation sets we could get different results.
Bias Variance Decomposition
Expected test error for different variations of the training data sampled from, \(\Pr(\dataVector, \dataScalar)\) \[\mathbb{E}\left[ \left(\dataScalar - \mappingFunction^*(\dataVector)\right)^2 \right]\] Decompose as \[\mathbb{E}\left[ \left(\dataScalar - \mappingFunction(\dataVector)\right)^2 \right] = \text{bias}\left[\mappingFunction^*(\dataVector)\right]^2 + \text{variance}\left[\mappingFunction^*(\dataVector)\right] +\sigma^2\]
Bias
- Given by \[\text{bias}\left[\mappingFunction^*(\dataVector)\right] = \mathbb{E}\left[\mappingFunction^*(\dataVector)\right] * \mappingFunction(\dataVector)\]
- Error due to bias comes from a model that’s too simple.
Variance
- Given by \[\text{variance}\left[\mappingFunction^*(\dataVector)\right] = \mathbb{E}\left[\left(\mappingFunction^*(\dataVector) - \mathbb{E}\left[\mappingFunction^*(\dataVector)\right]\right)^2\right]\]
- Slight variations in the training set cause changes in the prediction. Error due to variance is error in the model due to an overly complex model.
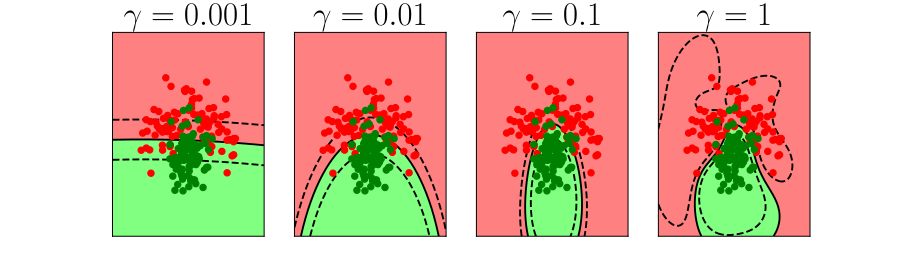
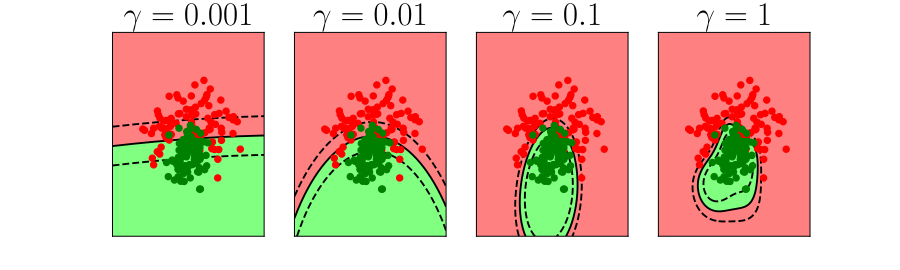
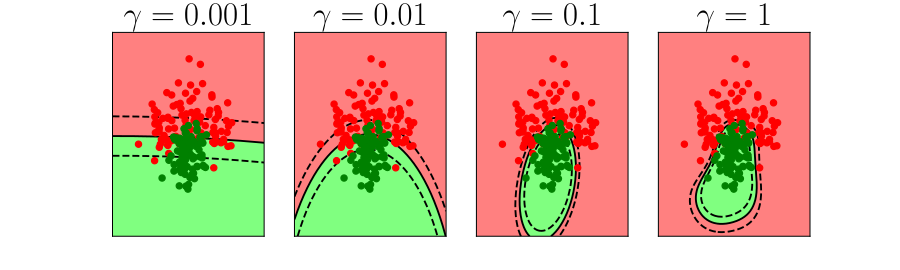
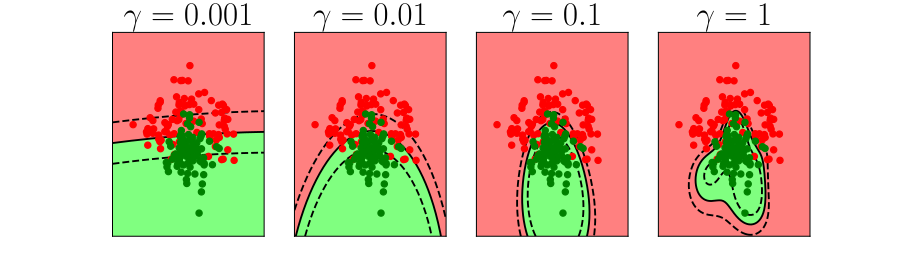
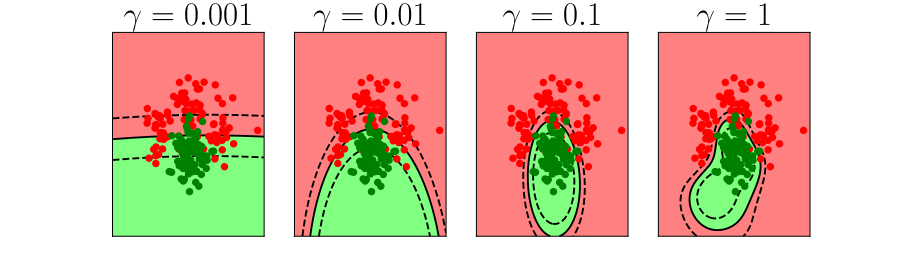
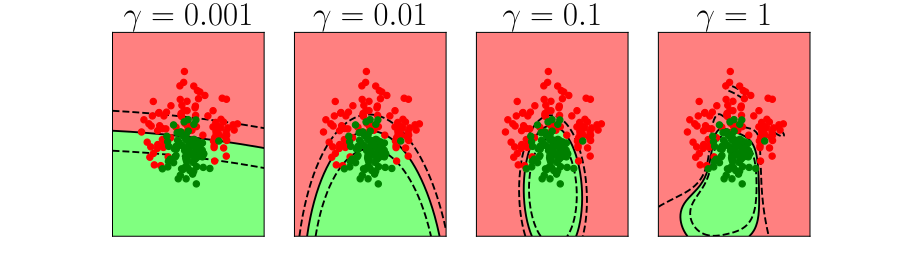
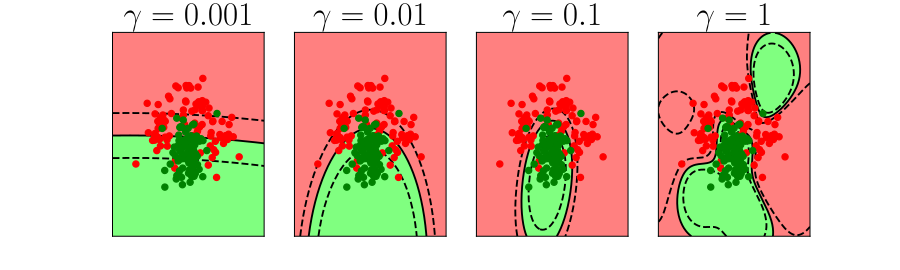
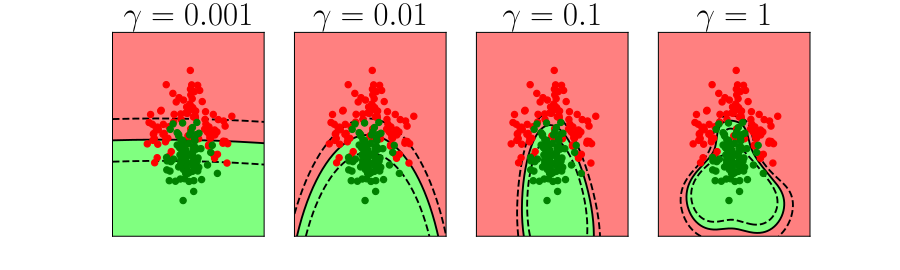
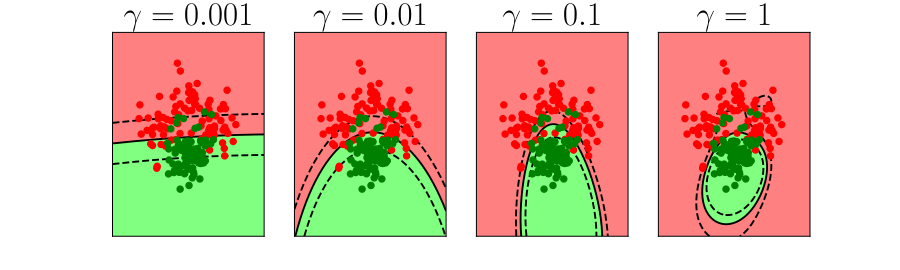
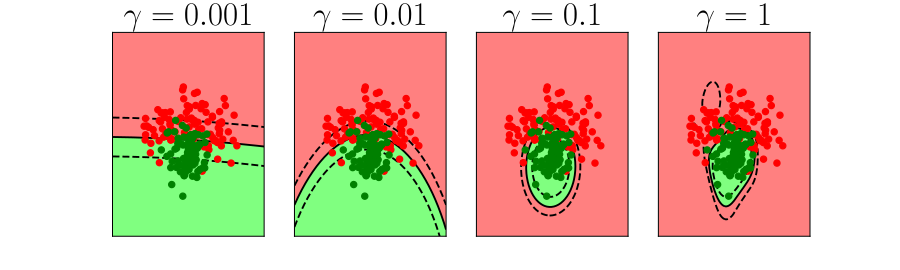
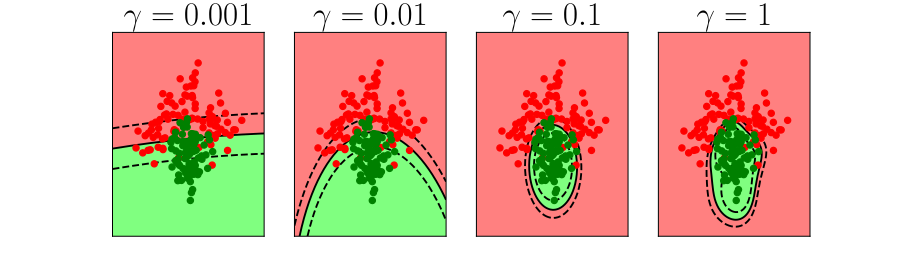
Overfitting
Alex Ihler on Polynomials and Overfitting
Olympic Data with Bayesian Polynomials
Hold Out Validation
5-fold Cross Validation
Thanks!
- twitter: @lawrennd
- podcast: The Talking Machines
Guardian article on How African can benefit from the data revolution
References
Andrade-Pacheco, R., Mubangizi, M., Quinn, J., Lawrence, N.D., 2014. Consistent mapping of government malaria records across a changing territory delimitation. Malaria Journal 13. https://doi.org/10.1186/1475-2875-13-S1-P5
Gelman, A., Carlin, J.B., Stern, H.S., Rubin, D.B., 2013. Bayesian data analysis, 3rd ed. Chapman; Hall.
McCulloch, W.S., Pitts, W., 1943. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics 5, 115–133.
Mubangizi, M., Andrade-Pacheco, R., Smith, M.T., Quinn, J., Lawrence, N.D., 2014. Malaria surveillance with multiple data sources using Gaussian process models, in: 1st International Conference on the Use of Mobile ICT in Africa.
Robbins, H., Monro, S., 1951. A stochastic approximation method. Annals of Mathematical Statistics 22, 400–407.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L., 2015. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV) 115, 211–252. https://doi.org/10.1007/s11263-015-0816-y
Taigman, Y., Yang, M., Ranzato, M., Wolf, L., 2014. DeepFace: Closing the gap to human-level performance in face verification, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2014.220