Machine Learning Systems Design
Re-work Deep Learning Summit
Artificial vs Natural Systems
- Consider natural intelligence, or natural systems
- Contrast between an artificial system and an natural system.
- The key difference between the two is that artificial systems are designed whereas natural systems are evolved.
Natural Systems are Evolved
Survival of the fittest
?
Natural Systems are Evolved
Survival of the fittest
Herbet Spencer, 1864
Natural Systems are Evolved
Non-survival of the non-fit
Mistake we Make
- Equate fitness for objective function.
- Assume static environment and known objective.
.
Technical Consequence
- Classical systems design assumes decomposability.
- Data-driven systems interfere with decomponsability.
Bits and Atoms
- The gap between the game and reality.
- The need for extrapolation over interpolation.
Ride Allocation Prediction
Machine Learning Systems Design
Fragility of AI Systems
- They are componentwise built from ML Capabilities.
- Each capability is independently constructed and verified.
- Pedestrian detection
- Road line detection
- Important for verification purposes.
The Software Crisis
The major cause of the software crisis is that the machines have become several orders of magnitude more powerful! To put it quite bluntly: as long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a mild problem, and now we have gigantic computers, programming has become an equally gigantic problem.
Edsger Dijkstra (1930-2002), The Humble Programmer
The Data Crisis
The major cause of the data crisis is that machines have become more interconnected than ever before. Data access is therefore cheap, but data quality is often poor. What we need is cheap high-quality data. That implies that we develop processes for improving and verifying data quality that are efficient.
There would seem to be two ways for improving efficiency. Firstly, we should not duplicate work. Secondly, where possible we should automate work.
Me
Computer Science Paradigm Shift
- Von Neuman Architecture:
- Code and data integrated in memory
- Today:
- Code and data separated for security
Computer Science Paradigm Shift
- Machine learning:
- Software is data
- Machine learning is a high level breach of the code/data separation.
Peppercorns
- A new name for system failures which aren’t bugs.
- Difference between finding a fly in your soup vs a peppercorn in your soup.
Peppercorns
Emulation
Emulation
Emulation
Emulation
Emulation
Emulation




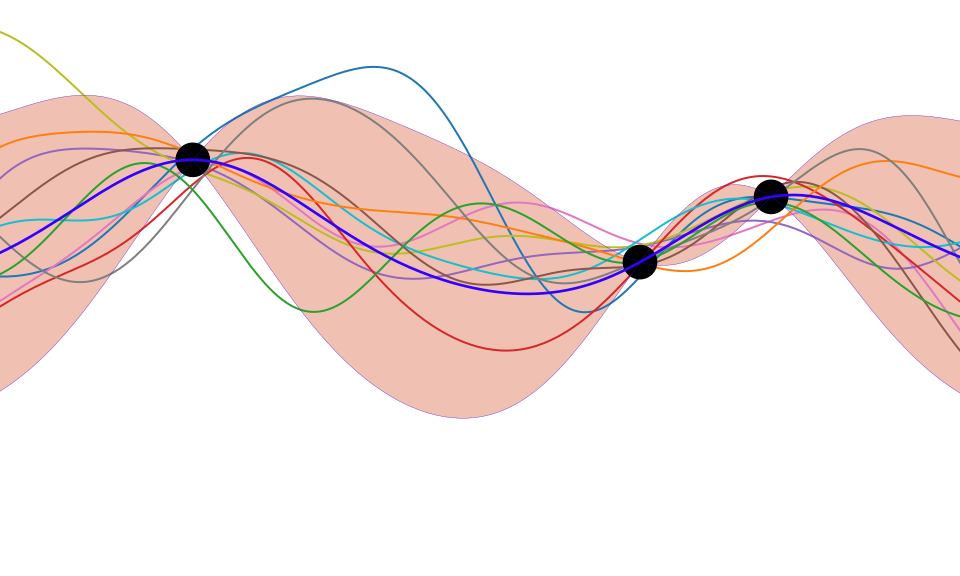
Deep Emulation
Deep Emulation
Deep Emulation
Emulation
Conclusion
- AI is fundamentally ML System Design
- We are not ready to deploy automation in uncontrolled environments.
- Until we can monitoring and update will be key.
Thanks!
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
Blog post on Natural and Artificial Intelligence
Blog post on Decision Making and Diversity
Blog post on Natural vs Artifical Intelligence