The NIPS Experiment
Just back from NIPS where it was really great to see the results of all the work everyone put in. I really enjoyed the program and thought the quality of all presented work was really strong. Both Corinna and I were particularly impressed by the work that put in by oral presenters to make their work accessible to such a large and diverse audience.
We also released some of the figures from the NIPS experiment, and there was a lot of discussion at the conference about what the result meant.
As we announced at the conference the consistency figure was 25.9%. I just wanted to confirm that in the spirit of openness that we’ve pursued across the entire conference process Corinna and I will provide a full write up of our analysis and conclusions in due course!
Some of the comment in the existing debate is missing out some of the background information we’ve tried to generate, so I just wanted to write a post that summarises that information to highlight its availability.
Scicast Question
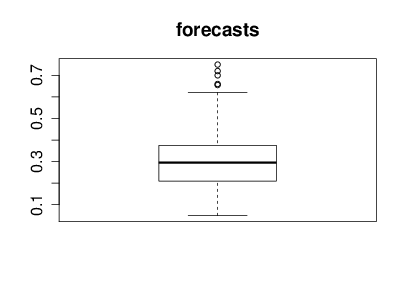
With the help of Nicolo Fusi, Charles Twardy and the entire Scicast team we launched a Scicast question a week before the results were revealed. The comment thread for that question already had an amount of interesting comment before the conference. Just for informational purposes before we began reviewing Corinna forecast this figure would be 25% and I forecast it would be 20%. The box plot summary of predictions from Scicast is below.
Comment at the Conference
There was also an amount of debate at the conference about what the results mean, a few attempts to answer this question (based only on the inconsistency score and the expected accept rate for the conference) are available here in this little Facebook discussion and on this blog post.
Background Information on the Process
Just to emphasise previous posts on this year’s conference see below:
- NIPS Decision Time
- Reviewer Calibration for NIPS
- Reviewer Recruitment and Experience
- Paper Allocation for NIPS
Software on Github
And finally there is a large amount of code available on a github site for allowing our processes to be recreated. A lot of it is tidied up, but the last sections on the analysis are not yet done because it was always my intention to finish those when the experimental results are fully released.