AI needs to serve people, science, and society
Abstract
Artificial intelligence offers great promise, but we must ensure it does not deepen inequalities. Today we are setting out our vision for AI@Cam, a new flagship mission at the University of Cambridge.
Henry Ford’s Faster Horse


Figure: A 1925 Ford Model T built at Henry Ford’s Highland Park Plant in Dearborn, Michigan. This example now resides in Australia, owned by the founder of FordModelT.net. From https://commons.wikimedia.org/wiki/File:1925_Ford_Model_T_touring.jpg
It’s said that Henry Ford’s customers wanted a “a faster horse”. If Henry Ford was selling us artificial intelligence today, what would the customer call for, “a smarter human”? That’s certainly the picture of machine intelligence we find in science fiction narratives, but the reality of what we’ve developed is much more mundane.
Car engines produce prodigious power from petrol. Machine intelligences deliver decisions derived from data. In both cases the scale of consumption enables a speed of operation that is far beyond the capabilities of their natural counterparts. Unfettered energy consumption has consequences in the form of climate change. Does unbridled data consumption also have consequences for us?
If we devolve decision making to machines, we depend on those machines to accommodate our needs. If we don’t understand how those machines operate, we lose control over our destiny. Our mistake has been to see machine intelligence as a reflection of our intelligence. We cannot understand the smarter human without understanding the human. To understand the machine, we need to better understand ourselves.
In Greek mythology, Panacea was the goddess of the universal remedy. One consequence of the pervasive potential of AI is that it is positioned, like Panacea, as the purveyor of a universal solution. Whether it is overcoming industry’s productivity challenges, or as a salve for strained public sector services, or a remedy for pressing global challenges in sustainable development, AI is presented as an elixir to resolve society’s problems.
In practice, translation of AI technology into practical benefit is not simple. Moreover, a growing body of evidence shows that risks and benefits from AI innovations are unevenly distributed across society.
When carelessly deployed, AI risks exacerbating existing social and economic inequalities.
Revolution
Arguably the information revolution we are experiencing is unprecedented in history. But changes in the way we share information have a long history. Over 5,000 years ago in the city of Uruk, on the banks of the Euphrates, communities which relied on the water to irrigate their corps developed an approach to recording transactions in clay. Eventually the system of recording system became sophisticated enough that their oral histories could be recorded in the form of the first epic: Gilgamesh.
See Lawrence (2024) cuneiform p. 337, 360, 390.

Figure: Chicago Stone, side 2, recording sale of a number of fields, probably from Isin, Early Dynastic Period, c. 2600 BC, black basalt
It was initially developed for people as a record of who owed what to whom, expanding individuals’ capacity to remember. But over a five hundred year period writing evolved to become a tool for literature as well. More pithily put, writing was invented by accountants not poets (see e.g. this piece by Tim Harford).
In some respects today’s revolution is different, because it involves also the creation of stories as well as their curation. But in some fundamental ways we can see what we have produced as another tool for us in the information revolution.
Coin Pusher
Disruption of society is like a coin pusher, it’s those who are already on the edge who are most likely to be effected by disruption.

Figure: A coin pusher is a game where coins are dropped into th etop of the machine, and they disrupt those on the existing steps. With any coin drop, many coins move, but it is those on the edge, who are often only indirectly effected, but also most traumatically effected by the change.
One danger of the current hype around ChatGPT is that we are overly focussing on the fact that it seems to have significant effect on professional jobs, people are naturally asking the question “what does it do for my role?”. No doubt, there will be disruption, but the coin pusher hypothesis suggests that that disruption will likely involve movement on the same step. However it is those on the edge already, who are often not working directly in the information economy, who often have less of a voice in the policy conversation who are likely to be most disrupted.
Royal Society Report

Figure: The Royal Society report on Machine Learning was released on 25th April 2017
A useful reference for state of the art in machine learning is the UK Royal Society Report, Machine Learning: Power and Promise of Computers that Learn by Example.
See Lawrence (2024) Royal Society; machine learning review and p. 25, 321, 395.
Public Research

Figure: The Royal Society comissioned public research from Mori as part of the machine learning review.
As is often the cas when members of the public are well convened, they offered sensible opinions about the utility and challenges of machine learning methods.

Figure: One of the questions focussed on machine learning applications.
A range of different scenaios were captured by this qualitative work.

Figure: The public were broadly supportive of a range of application areas.

Figure: But they failed to see the point in AI’s that could produce poetry.
The one scenario where the public were unable to perceive any advantage in machine learning was an example from art, the creation of poetry. This was felt to be a fundamentally human activity that machines could only emulate at best.
Mercutio
It’s ironic that despite the public focus on transport, health, cities, crime and their confusion as to why we might want AI to do art, one area where significant progress has been made is on AIs that can create literature.
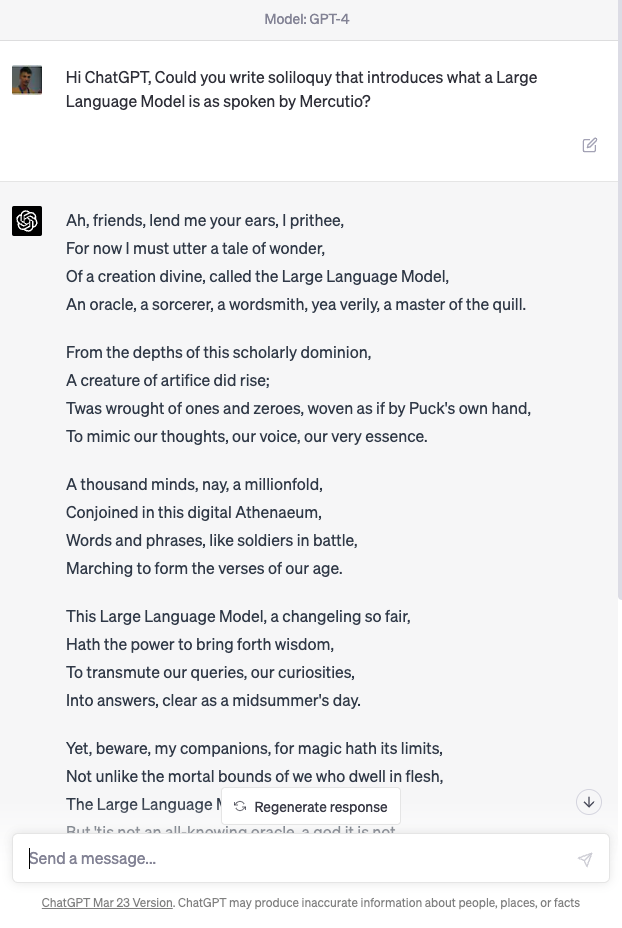
Figure: Despite the public’s desire to see challenges in health, finance, transport, crime solved by machine learning and their skepticism around poetry, one of the problems we have solved seems to be poetry.
User: Hi ChatGPT, Could you write soliloquy that introduces what a Large Language Model is as spoken by Mercutio?
Machine: Ah, friends, lend me your ears, I prithee, For now I must utter a tale of wonder, Of a creation divine, called the Large Language Model, An oracle, a sorcerer, a wordsmith, yea verily, a master of the quill.
From the depths of this scholarly dominion, A creature of artifice did rise; Twas wrought of ones and zeroes, woven as if by Puck’s own hand, To mimic our thoughts, our voice, our very essence.
A thousand minds, nay, a millionfold, Conjoined in this digital Athenaeum, Words and phrases, like soldiers in battle, Marching to form the verses of our age.
This Large Language Model, a changeling so fair, Hath the power to bring forth wisdom, To transmute our queries, our curiosities, Into answers, clear as a midsummer’s day.
Yet, beware, my companions, for magic hath its limits, Not unlike the mortal bounds of we who dwell in flesh, The Large Language Model hath its strengths, But ’tis not an all-knowing oracle, a god it is not.
As Mercutio, your humble servant, doth stand before thee, I marvel at the art and science that hath brought forth this wondrous creation, This Large Language Model, a testament to man’s yearning, To comprehend the world and make meaning of the great tapestry of existence.
In faith, dear friends, let us embrace the magic and beauty of this digital bard, And mayhaps, by its grace, we shall glean some wisdom, As we wander together, hand in hand, Through this boundless realm of knowledge and wonder.
ChatGPT transcript, 14th April 2023.
A Question of Trust
In Baroness Onora O’Neill’s Reeith Lectures from 2002, she raises the challenge of trust. There are many aspects to her arcuments, but one of the key points she makes is that we cannot trust without the notion of duty. O’Neill is bemoaning the substitution of duty with process. The idea is that processes and transparency are supposed to hold us to account by measuring outcomes. But these processes themselves overwhelm decision makers and undermine their professional duty to deliver the right outcome.

Figure: A Question of Trust by Onora O’Neil which examines the nature of trust and its role in society.
Again Univesities are to treat each applicant fairly on the basis of ability and promise, but they are supposed also to admit a socially more representative intake.
There’s no guarantee that the process meets the target.
Onora O’Neill A Question of Trust: Called to Account Reith Lectures 2002 O’Neill (2002)]
O’Neill is speaking in 2002, in the early days of the internet and before social media. Much of her thoughts are even more relevant for today than they were when she spoke. This is because the increased availability of information and machine driven decision-making makes the mistaken premise, that process is an adequate substitute for duty, more apparently plausible. But this undermines what O’Neill calls “intelligent accountability”, which is not accounting by the numbers, but through professional education and institutional safeguards.
See Lawrence (2024) O’Neill, Baroness Onora: ‘A question of trust’ lecture series (2002) p. 352, 363.
The Open Society and its Enemies

Figure: The Open Society and Its Enemies by Karl Popper views liberal democracies as a collection of “piecemeal social engineers” who strive towards better outcomes.
Popper opened the preface to his book (Popper, 1945) with the following words:
If in this book harsh words are spoken about some of the greatest among the intellectual leaders of mankind, my motive is not, I hope, to belittle them. It springs rather from my conviction that, if our civilization is to survive, we must break with the habit of deference to great men. Great men may make great mistakes; and as the book tries to show, some of the greatest leaders of the past supported the perennial attack on freedom and reason.
He had written the book against the background of the second world war, his decision to write it taken on the day the Nazis invaded Austria in March 1938. His book is a reaction to totalitarianism.
For Popper, the ideas of “great men” become totalitarian when imposed on society. He advocates for direct liberal democracy as the only form of government that can allow for institutional change without bloodshed. The open society is one characterized by institutions and individuals that can engage in the practical pursuit of solutions to social and political problems. The institutions are also underpinned by individuals: lawyers, accountants, civil administrators and many more. To Popper it is these “piecemeal social engineers” who offer pragmatic solutions to our society’s political and social challenges.
See Lawrence (2024) Popper, Karl The Open Society and its Enemies p. 371–374.
The Atomic Human

Innovating to serve science and society requires a pipeline of interventions. As well as advances in the technical capabilities of AI technologies, engineering knowhow is required to safely deploy and monitor those solutions in practice. Regulatory frameworks need to adapt to ensure trustworthy use of these technologies. Aligning technology development with public interests demands effective stakeholder engagement to bring diverse voices and expertise into technology design.
Building this pipeline requires coordination across research, engineering, policy and practice. It also requires action to address the digital divides that influence who benefits from AI advances. These include digital divides within the socioeconomic strata that need to be overcome – AI must not exacerbate existing equalities or create new ones. In addressing these challenges, we can be hindered by divides that exist between traditional academic disciplines. We need to develop common understanding of the problems and a shared knowledge of possible solutions.
Embodiment Factors
| bits/min | billions | 2,000 |
|
billion calculations/s |
~100 | a billion |
| embodiment | 20 minutes | 5 billion years |
Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, it is a matter of thousands of millions of years. See also “Living Together: Mind and Machine Intelligence” Lawrence (2017)
There is a fundamental limit placed on our intelligence based on our ability to communicate. Claude Shannon founded the field of information theory. The clever part of this theory is it allows us to separate our measurement of information from what the information pertains to.1
Shannon measured information in bits. One bit of information is the amount of information I pass to you when I give you the result of a coin toss. Shannon was also interested in the amount of information in the English language. He estimated that on average a word in the English language contains 12 bits of information.
Given typical speaking rates, that gives us an estimate of our ability to communicate of around 100 bits per second (Reed and Durlach, 1998). Computers on the other hand can communicate much more rapidly. Current wired network speeds are around a billion bits per second, ten million times faster.
When it comes to compute though, our best estimates indicate our computers are slower. A typical modern computer can process make around 100 billion floating-point operations per second, each floating-point operation involves a 64 bit number. So the computer is processing around 6,400 billion bits per second.
It’s difficult to get similar estimates for humans, but by some estimates the amount of compute we would require to simulate a human brain is equivalent to that in the UK’s fastest computer (Ananthanarayanan et al., 2009), the MET office machine in Exeter, which in 2018 ranked as the 11th fastest computer in the world. That machine simulates the world’s weather each morning, and then simulates the world’s climate in the afternoon. It is a 16-petaflop machine, processing around 1,000 trillion bits per second.
See Lawrence (2024) embodiment factor p. 13, 29, 35, 79, 87, 105, 197, 216-217, 249, 269, 353, 369.
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
Computer Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Similarly, we find it difficult to comprehend how computers are making decisions. Because they do so with more data than we can possibly imagine.
In many respects, this is not a problem, it’s a good thing. Computers and us are good at different things. But when we interact with a computer, when it acts in a different way to us, we need to remember why.
Just as the first step to getting along with other humans is understanding other humans, so it needs to be with getting along with our computers.
Embodiment factors explain why, at the same time, computers are so impressive in simulating our weather, but so poor at predicting our moods. Our complexity is greater than that of our weather, and each of us is tuned to read and respond to one another.
Their intelligence is different. It is based on very large quantities of data that we cannot absorb. Our computers don’t have a complex internal model of who we are. They don’t understand the human condition. They are not tuned to respond to us as we are to each other.
Embodiment factors encapsulate a profound thing about the nature of humans. Our locked in intelligence means that we are striving to communicate, so we put a lot of thought into what we’re communicating with. And if we’re communicating with something complex, we naturally anthropomorphize them.
We give our dogs, our cats, and our cars human motivations. We do the same with our computers. We anthropomorphize them. We assume that they have the same objectives as us and the same constraints. They don’t.
This means, that when we worry about artificial intelligence, we worry about the wrong things. We fear computers that behave like more powerful versions of ourselves that will struggle to outcompete us.
In reality, the challenge is that our computers cannot be human enough. They cannot understand us with the depth we understand one another. They drop below our cognitive radar and operate outside our mental models.
The real danger is that computers don’t anthropomorphize. They’ll make decisions in isolation from us without our supervision because they can’t communicate truly and deeply with us.
HAM
The Human-Analogue Machine or HAM therefore provides a route through which we could better understand our world through improving the way we interact with machines.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
The HAM can provide an interface between the digital computer and the human allowing humans to work closely with computers regardless of their understandin gf the more technical parts of software engineering.
Figure: The HAM now sits between us and the traditional digital computer.
Of course this route provides new routes for manipulation, new ways in which the machine can undermine our autonomy or exploit our cognitive foibles. The major challenge we face is steering between these worlds where we gain the advantage of the computer’s bandwidth without undermining our culture and individual autonomy.
See Lawrence (2024) human-analogue machine (HAMs) p. 343-347, 359-359, 365-368.
Making AI equitable
ai@cam is a flagship University mission that seeks to address these challenges. It recognises that development of safe and effective AI-enabled innovations requires this mix of expertise from across research domains, businesses, policy-makers, civill society, and from affected communities. ai@cam is setting out a vision for AI-enabled innovation that benefits science, citizens and society.
This vision will be achieved through leveraging the University’s vibrant interdisciplinary research community. AI@Cam will form partnerships between researchers, practitioners, and affected communities that embed equity and inclusion. It will develop new platforms for innovation and knowledge transfer. It will deliver innovative interdisciplinary teaching and learning for students, researchers, and professionals. It will build strong connections between the University and national AI priorities.
The University operates as both an engine of AI-enabled innovation and steward of those innovations.
AI is not a universal remedy. It is a set of tools, techniques and practices that correctly deployed can be leveraged to deliver societal benefit and mitigate social harm.
In that sense AI@Cam’s mission is close in spirit to that of Panacea’s elder sister Hygeia. It is focussed on building and maintaining the hygiene of a robust and equitable AI research ecosystem.
ai@cam
ai@cam is a new flagship University mission that seeks to address these challenges. It recognises that development of safe and effective AI-enabled innovations requires this mix of expertise from across research domains, businesses, policy-makers, civill society, and from affected communities. AI@Cam is setting out a vision for AI-enabled innovation that benefits science, citizens and society.
This vision will be achieved through leveraging the University’s vibrant interdisciplinary research community. AI@Cam will form partnerships between researchers, practitioners, and affected communities that embed equity and inclusion. It will develop new platforms for innovation and knowledge transfer. It will deliver innovative interdisciplinary teaching and learning for students, researchers, and professionals. It will build strong connections between the University and national AI priorities.
The University operates as both an engine of AI-enabled innovation and steward of those innovations.
AI is not a universal remedy. It is a set of tools, techniques and practices that correctly deployed can be leveraged to deliver societal benefit and mitigate social harm.
In that sense AI@Cam’s mission is close in spirit to that of Panacea’s elder sister Hygeia. It is focussed on building and maintaining the hygiene of a robust and equitable AI research ecosystem.

Finally, we are working across the University to empower the diversity ofexpertise and capability we have to focus on these broad societal problems. We will recently launched AI@Cam with a vision document that outlines these challenges for the University.
The initiative was funded in November 2022 where a £5M investment from the University was secured.
Progress so far:
- Developing the vision
- Engaged over 100 members of the University community across 30 departments/institutes, start-ups, and large businesses.
- Supported 6 new funding bids
- Five A-Ideas interdisciplinary projects
- 44 Pioneer computing projects
Thanks!
For more information on these subjects and more you might want to check the following resources.
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com
References
The Great AI Fallacy
There is a lot of variation in the use of the term artificial intelligence. I’m sometimes asked to define it, but depending on whether you’re speaking to a member of the public, a fellow machine learning researcher, or someone from the business community, the sense of the term differs.
However, underlying its use I’ve detected one disturbing trend. A trend I’m beginining to think of as “The Great AI Fallacy”.
The fallacy is associated with an implicit promise that is embedded in many statements about Artificial Intelligence. Artificial Intelligence, as it currently exists, is merely a form of automated decision making. The implicit promise of Artificial Intelligence is that it will be the first wave of automation where the machine adapts to the human, rather than the human adapting to the machine.
How else can we explain the suspension of sensible business judgment that is accompanying the hype surrounding AI?
This fallacy is particularly pernicious because there are serious benefits to society in deploying this new wave of data-driven automated decision making. But the AI Fallacy is causing us to suspend our calibrated skepticism that is needed to deploy these systems safely and efficiently.
The problem is compounded because many of the techniques that we’re speaking of were originally developed in academic laboratories in isolation from real-world deployment.

Figure: We seem to have fallen for a perspective on AI that suggests it will adapt to our schedule, rather in the manner of a 1930s manservant.
The Accelerate Programme
Figure: The Accelerate Programme for Scientific Discovery covers research, education and training, engagement. Our aim is to bring about a step change in scientific discovery through AI. http://acceleratescience.github.io
We’re now in a new phase of the development of computing, with rapid advances in machine learning. But we see some of the same issues – researchers across disciplines hope to make use of machine learning, but need access to skills and tools to do so, while the field machine learning itself will need to develop new methods to tackle some complex, ‘real world’ problems.
It is with these challenges in mind that the Computer Lab has started the Accelerate Programme for Scientific Discovery. This new Programme is seeking to support researchers across the University to develop the skills they need to be able to use machine learning and AI in their research.
To do this, the Programme is developing three areas of activity:
- Research: we’re developing a research agenda that develops and applies cutting edge machine learning methods to scientific challenges, with three Accelerate Research fellows working directly on issues relating to computational biology, psychiatry, and string theory. While we’re concentrating on STEM subjects for now, in the longer term our ambition is to build links with the social sciences and humanities.
Progress so far includes:
Recruited a core research team working on the application of AI in mental health, bioinformatics, healthcare, string theory, and complex systems.
Created a research agenda and roadmap for the development of AI in science.
Funded 9 interdisciplinary projects:
Antimicrobial resistance in farming
Quantifying Design Trade-offs in Electricity-generation-focused Tokamaks using AI
Automated preclinical drug discovery in vivo using pose estimation
Causal Methods for Environmental Science Workshop
Automatic tree mapping in Cambridge
Acoustic monitoring for biodiversity conservation
AI, mathematics and string theory
Theoretical, Scientific, and Philosophical Perspectives on Biological Understanding in the age of Artificial Intelligence
AI in pathology: optimising a classifier for digital images of duodenal biopsies
Teaching and learning: building on the teaching activities already delivered through University courses, we’re creating a pipeline of learning opportunities to help PhD students and postdocs better understand how to use data science and machine learning in their work.
Progress so far includes:
Teaching and learning
Brought over 250 participants from over 30 departments through tailored data science and machine learning for science training (Data Science Residency and Machine Learning Academy);
Convened workshops with over 80 researchers across the University on the development of data pipelines for science;
Delivered University courses to over 100 students in Advanced Data Science and Machine Learning and the Physical World.
Online training course in Python and Pandas accessed by over 380 researchers.
Engagement: we hope that Accelerate will help build a community of researchers working across the University at the interface on machine learning and the sciences, helping to share best practice and new methods, and support each other in advancing their research. Over the coming years, we’ll be running a variety of events and activities in support of this.
Progress so far includes:
Launched a Machine Learning Engineering Clinic that has supported over 40 projects across the University with MLE troubleshooting and advice;
Hosted and participated in events reaching over 300 people in Cambridge;
Led international workshops at Dagstuhl and Oberwolfach, convening over 60 leading researchers;
Engaged over 70 researchers through outreach sessions and workshops with the School of Clinical Medicine, the Faculty of Education, Cambridge Digital Humanities and the School of Biological Sciences.
Personal Data Trusts
The machine learning solutions we are dependent on to drive automated decision making are dependent on data. But with regard to personal data there are important issues of privacy. Data sharing brings benefits, but also exposes our digital selves. From the use of social media data for targeted advertising to influence us, to the use of genetic data to identify criminals, or natural family members. Control of our virtual selves maps on to control of our actual selves.
The feudal system that is implied by current data protection legislation has significant power asymmetries at its heart, in that the data controller has a duty of care over the data subject, but the data subject may only discover failings in that duty of care when it’s too late. Data controllers also may have conflicting motivations, and often their primary motivation is not towards the data-subject, but that is a consideration in their wider agenda.
Personal Data Trusts (Delacroix and Lawrence, 2018; Edwards, 2004; Lawrence, 2016) are a potential solution to this problem. Inspired by land societies that formed in the 19th century to bring democratic representation to the growing middle classes. A land society was a mutual organization where resources were pooled for the common good.
A Personal Data Trust would be a legal entity where the trustees’ responsibility was entirely to the members of the trust. So the motivation of the data-controllers is aligned only with the data-subjects. How data is handled would be subject to the terms under which the trust was convened. The success of an individual trust would be contingent on it satisfying its members with appropriate balancing of individual privacy with the benefits of data sharing.
Formation of Data Trusts became the number one recommendation of the Hall-Presenti report on AI, but unfortunately, the term was confounded with more general approaches to data sharing that don’t necessarily involve fiduciary responsibilities or personal data rights. It seems clear that we need to better characterize the data sharing landscape as well as propose mechanisms for tackling specific issues in data sharing.
It feels important to have a diversity of approaches, and yet it feels important that any individual trust would be large enough to be taken seriously in representing the views of its members in wider negotiations.
{kind=link}

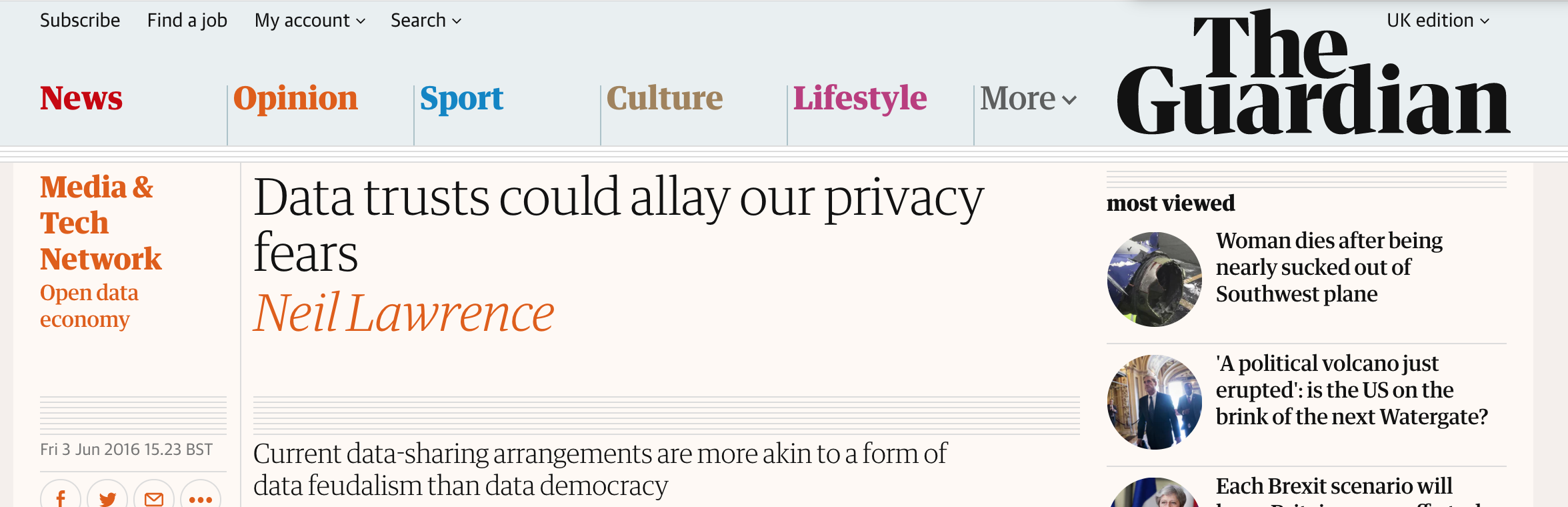
Figure: Data Trusts were the first recommendation of the Hall-Presenti Report. More recently the nature of different data intermediaries was clarified in a report on https://www.adalovelaceinstitute.org/report/legal-mechanisms-data-stewardship/ from the Ada Lovelace Institute.
See Guardian article on Digital Oligarchies and Guardian article on Information Feudalism.
Data Trusts Initiative
The Data Trusts Initiative, funded by the Patrick J. McGovern Foundation is supporting three pilot projects that consider how bottom-up empowerment can redress the imbalance associated with the digital oligarchy.

Figure: The Data Trusts Initiative (http://datatrusts.uk) hosts blog posts helping build understanding of data trusts and supports research and pilot projects.
Progress So Far
In its first 18 months of operation, the Initiative has:
Convened over 200 leading data ethics researchers and practitioners;
Funded 7 new research projects tackling knowledge gaps in data trust theory and practice;
Supported 3 real-world data trust pilot projects establishing new data stewardship mechanisms.