AI Challenges and Opportunities
Abstract
As AI technologies reshape the business landscape, leaders face questions about balancing automation with individual judgment, information flows, and organisational decision-making. This talk builds on the ideas in Atomic Human to explore the practical implications of AI for businesses through the lens of information topography, decision-making structures, and human-AI collaboration. Drawing from real-world examples and insights from the book we’ll explore how businesses can strategically implement AI while maintaining human agency, intelligent accountability, and organisational effectiveness.
Henry Ford’s Faster Horse


Figure: A 1925 Ford Model T built at Henry Ford’s Highland Park Plant in Dearborn, Michigan. This example now resides in Australia, owned by the founder of FordModelT.net. From https://commons.wikimedia.org/wiki/File:1925_Ford_Model_T_touring.jpg
It’s said that Henry Ford’s customers wanted a “a faster horse”. If Henry Ford was selling us artificial intelligence today, what would the customer call for, “a smarter human”? That’s certainly the picture of machine intelligence we find in science fiction narratives, but the reality of what we’ve developed is much more mundane.
Car engines produce prodigious power from petrol. Machine intelligences deliver decisions derived from data. In both cases the scale of consumption enables a speed of operation that is far beyond the capabilities of their natural counterparts. Unfettered energy consumption has consequences in the form of climate change. Does unbridled data consumption also have consequences for us?
If we devolve decision making to machines, we depend on those machines to accommodate our needs. If we don’t understand how those machines operate, we lose control over our destiny. Our mistake has been to see machine intelligence as a reflection of our intelligence. We cannot understand the smarter human without understanding the human. To understand the machine, we need to better understand ourselves.
The Atomic Human
Figure: The Atomic Eye, by slicing away aspects of the human that we used to believe to be unique to us, but are now the preserve of the machine, we learn something about what it means to be human.
The development of what some are calling intelligence in machines, raises questions around what machine intelligence means for our intelligence. The idea of the atomic human is derived from Democritus’s atomism.
In the fifth century bce the Greek philosopher Democritus posed a question about our physical universe. He imagined cutting physical matter into pieces in a repeated process: cutting a piece, then taking one of the cut pieces and cutting it again so that each time it becomes smaller and smaller. Democritus believed this process had to stop somewhere, that we would be left with an indivisible piece. The Greek word for indivisible is atom, and so this theory was called atomism.
The Atomic Human considers the same question, but in a different domain, asking: As the machine slices away portions of human capabilities, are we left with a kernel of humanity, an indivisible piece that can no longer be divided into parts? Or does the human disappear altogether? If we are left with something, then that uncuttable piece, a form of atomic human, would tell us something about our human spirit.
See Lawrence (2024) atomic human, the p. 13.
The Diving Bell and the Butterfly

Figure: The Diving Bell and the Buttefly is the autobiography of Jean Dominique Bauby.
The Diving Bell and the Butterfly is the autobiography of Jean Dominique Bauby. Jean Dominique, the editor of French Elle magazine, suffered a major stroke at the age of 43 in 1995. The stroke paralyzed him and rendered him speechless. He was only able to blink his left eyelid, he became a sufferer of locked in syndrome.
See Lawrence (2024) Le Scaphandre et le papillon (The Diving Bell and the Butterfly) p. 10–12.
O M D P C F B V
H G J Q Z Y X K W
Figure: The ordering of the letters that Bauby used for writing his autobiography.
How could he do that? Well, first, they set up a mechanism where he could scan across letters and blink at the letter he wanted to use. In this way, he was able to write each letter.
It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
Imagine doing all that thinking, but so little speaking, having all those thoughts and so little ability to communicate.
One challenge for the atomic human is that we are all in that situation. While not as extreme as for Bauby, when we compare ourselves to the machine, we all have a locked-in intelligence.
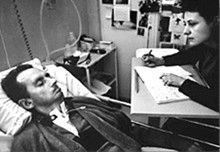
Figure: Jean Dominique Bauby was the Editor in Chief of the French Elle Magazine, he suffered a stroke that destroyed his brainstem, leaving him only capable of moving one eye. Jean Dominique became a victim of locked in syndrome.
Incredibly, Jean Dominique wrote his book after he became locked in. It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
The idea behind embodiment factors is that we are all in that situation. While not as extreme as for Bauby, we all have somewhat of a locked in intelligence.
See Lawrence (2024) Bauby, Jean Dominique p. 9–11, 18, 90, 99-101, 133, 186, 212–218, 234, 240, 251–257, 318, 368–369.
Bauby and Shannon
|
|

|
Figure: Claude Shannon developed information theory which allows us to quantify how much Bauby can communicate. This allows us to compare how locked in he is to us.
See Lawrence (2024) Shannon, Claude p. 10, 30, 61, 74, 98, 126, 134, 140, 143, 149, 260, 264, 269, 277, 315, 358, 363.
Embodiment Factors
|
|
|||
| bits/min | billions | 2000 | 6 |
|
billion calculations/s |
~100 | a billion | a billion |
| embodiment | 20 minutes | 5 billion years | 15 trillion years |
Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Jean Dominique Bauby suffered from locked-in syndrome. The embodiment factors show that relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, whether locked in or not, it is a matter of many millions of years.
Let me explain what I mean. Claude Shannon introduced a mathematical concept of information for the purposes of understanding telephone exchanges.
Information has many meanings, but mathematically, Shannon defined a bit of information to be the amount of information you get from tossing a coin.
If I toss a coin, and look at it, I know the answer. You don’t. But if I now tell you the answer I communicate to you 1 bit of information. Shannon defined this as the fundamental unit of information.
If I toss the coin twice, and tell you the result of both tosses, I give you two bits of information. Information is additive.
Shannon also estimated the average information associated with the English language. He estimated that the average information in any word is 12 bits, equivalent to twelve coin tosses.
So every two minutes Bauby was able to communicate 12 bits, or six bits per minute.
This is the information transfer rate he was limited to, the rate at which he could communicate.
Compare this to me, talking now. The average speaker for TEDX speaks around 160 words per minute. That’s 320 times faster than Bauby or around a 2000 bits per minute. 2000 coin tosses per minute.
But, just think how much thought Bauby was putting into every sentence. Imagine how carefully chosen each of his words was. Because he was communication constrained he could put more thought into each of his words. Into thinking about his audience.
So, his intelligence became locked in. He thinks as fast as any of us, but can communicate slower. Like the tree falling in the woods with no one there to hear it, his intelligence is embedded inside him.
Two thousand coin tosses per minute sounds pretty impressive, but this talk is not just about us, it’s about our computers, and the type of intelligence we are creating within them.
So how does two thousand compare to our digital companions? When computers talk to each other, they do so with billions of coin tosses per minute.
Let’s imagine for a moment, that instead of talking about communication of information, we are actually talking about money. Bauby would have 6 dollars. I would have 2000 dollars, and my computer has billions of dollars.
The internet has interconnected computers and equipped them with extremely high transfer rates.
However, by our very best estimates, computers actually think slower than us.
How can that be? You might ask, computers calculate much faster than me. That’s true, but underlying your conscious thoughts there are a lot of calculations going on.
Each thought involves many thousands, millions or billions of calculations. How many exactly, we don’t know yet, because we don’t know how the brain turns calculations into thoughts.
Our best estimates suggest that to simulate your brain a computer would have to be as large as the UK Met Office machine here in Exeter. That’s a 250 million pound machine, the fastest in the UK. It can do 16 billion billon calculations per second.
It simulates the weather across the word every day, that’s how much power we think we need to simulate our brains.
So, in terms of our computational power we are extraordinary, but in terms of our ability to explain ourselves, just like Bauby, we are locked in.
For a typical computer, to communicate everything it computes in one second, it would only take it a couple of minutes. For us to do the same would take 15 billion years.
If intelligence is fundamentally about processing and sharing of information. This gives us a fundamental constraint on human intelligence that dictates its nature.
I call this ratio between the time it takes to compute something, and the time it takes to say it, the embodiment factor (Lawrence, 2017). Because it reflects how embodied our cognition is.
If it takes you two minutes to say the thing you have thought in a second, then you are a computer. If it takes you 15 billion years, then you are a human.
Bandwidth Constrained Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Embodiment factors imply that, in our communication between humans, what is not said is, perhaps, more important than what is said. To communicate with each other we need to have a model of who each of us are.
To aid this, in society, we are required to perform roles. Whether as a parent, a teacher, an employee or a boss. Each of these roles requires that we conform to certain standards of behaviour to facilitate communication between ourselves.
Control of self is vitally important to these communications.
The high availability of data available to humans undermines human-to-human communication channels by providing new routes to undermining our control of self.
The consequences between this mismatch of power and delivery are to be seen all around us. Because, just as driving an F1 car with bicycle wheels would be a fine art, so is the process of communication between humans.
If I have a thought and I wish to communicate it, I first need to have a model of what you think. I should think before I speak. When I speak, you may react. You have a model of who I am and what I was trying to say, and why I chose to say what I said. Now we begin this dance, where we are each trying to better understand each other and what we are saying. When it works, it is beautiful, but when mis-deployed, just like a badly driven F1 car, there is a horrible crash, an argument.

Figure: This is the drawing Dan was inspired to create for Chapter 1. It captures the fundamentally narcissistic nature of our (societal) obsession with our intelligence.
See blog post on Dan Andrews image of our reflective obsession with AI.. See also (Vallor, 2024).
Computer Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Similarly, we find it difficult to comprehend how computers are making decisions. Because they do so with more data than we can possibly imagine.
In many respects, this is not a problem, it’s a good thing. Computers and us are good at different things. But when we interact with a computer, when it acts in a different way to us, we need to remember why.
Just as the first step to getting along with other humans is understanding other humans, so it needs to be with getting along with our computers.
Embodiment factors explain why, at the same time, computers are so impressive in simulating our weather, but so poor at predicting our moods. Our complexity is greater than that of our weather, and each of us is tuned to read and respond to one another.
Their intelligence is different. It is based on very large quantities of data that we cannot absorb. Our computers don’t have a complex internal model of who we are. They don’t understand the human condition. They are not tuned to respond to us as we are to each other.
Embodiment factors encapsulate a profound thing about the nature of humans. Our locked in intelligence means that we are striving to communicate, so we put a lot of thought into what we’re communicating with. And if we’re communicating with something complex, we naturally anthropomorphize them.
We give our dogs, our cats, and our cars human motivations. We do the same with our computers. We anthropomorphize them. We assume that they have the same objectives as us and the same constraints. They don’t.
This means, that when we worry about artificial intelligence, we worry about the wrong things. We fear computers that behave like more powerful versions of ourselves that will struggle to outcompete us.
In reality, the challenge is that our computers cannot be human enough. They cannot understand us with the depth we understand one another. They drop below our cognitive radar and operate outside our mental models.
The real danger is that computers don’t anthropomorphize. They’ll make decisions in isolation from us without our supervision because they can’t communicate truly and deeply with us.
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
Maintaining Human Judgment in Critical Decisions
The Horizon Scandal
In the UK we saw these effects play out in the Horizon scandal: the accounting system of the national postal service was computerized by Fujitsu and first installed in 1999, but neither the Post Office nor Fujitsu were able to control the system they had deployed. When it went wrong individual sub postmasters were blamed for the systems’ errors. Over the next two decades they were prosecuted and jailed leaving lives ruined in the wake of the machine’s mistakes.
{kind=link}
See Lawrence (2024) Horizon scandal p. 371.
The Horizon scandal dramatically demonstrates what happens when human judgment is subordinated to algorithmic outputs. Organizations must build structures that maintain human judgment in critical decisions.
Revolution
Arguably the information revolution we are experiencing is unprecedented in history. But changes in the way we share information have a long history. Over 5,000 years ago in the city of Uruk, on the banks of the Euphrates, communities which relied on the water to irrigate their corps developed an approach to recording transactions in clay. Eventually the system of recording system became sophisticated enough that their oral histories could be recorded in the form of the first epic: Gilgamesh.
See Lawrence (2024) cuneiform p. 337, 360, 390.

Figure: Chicago Stone, side 2, recording sale of a number of fields, probably from Isin, Early Dynastic Period, c. 2600 BC, black basalt
It was initially developed for people as a record of who owed what to whom, expanding individuals’ capacity to remember. But over a five hundred year period writing evolved to become a tool for literature as well. More pithily put, writing was invented by accountants not poets (see e.g. this piece by Tim Harford).
In some respects today’s revolution is different, because it involves also the creation of stories as well as their curation. But in some fundamental ways we can see what we have produced as another tool for us in the information revolution.
The Structure of Scientific Revolutions

Figure: The Structure of Scientific Revolutions by Thomas S. Kuhn suggests scientific paradigms are recorded in books.
Kuhn was a historian of science and a philosopher who suggested that the sociology of science has two principal components to it. His idea is that “normal science” operates within a paradigm That paradigm is defined by books which encode our best understanding. An example of a paradigm is Newtonian mechanics, or another example would be the geocentric view of the Universe. Within a paradigm normal science proceeds by scientists solving the “puzzles” that paradigm sets. A paradigm shift is when the paradigm changes, for example the Corpernican revolution or the introduction of relativity.
The notion of a paradigm shift has also entered common parlance, this reflects the idea that wider human knowledge is also shared and stored, less ormally than scientific knowledge, but still with a dependence on our information infrastructure.
The digital computer has brought a fundamental change in the nature of that information infrastructure. By moving information faster the modern information infrastructure is dominated not by the book, but by the machine. This brings challenges for managing and controlling this information infrastructure.
See Lawrence (2024) Kuhn, Thomas: The Structure of Scientific Revolutions p. 295–299.
Blake’s Newton
William Blake’s rendering of Newton captures humans in a particular state. He is trance-like absorbed in simple geometric shapes. The feel of dreams is enhanced by the underwater location, and the nature of the focus is enhanced because he ignores the complexity of the sea life around him.

Figure: William Blake’s Newton. 1795c-1805
See Lawrence (2024) Blake, William Newton p. 121–123.
The caption in the Tate Britain reads:
Here, Blake satirises the 17th-century mathematician Isaac Newton. Portrayed as a muscular youth, Newton seems to be underwater, sitting on a rock covered with colourful coral and lichen. He crouches over a diagram, measuring it with a compass. Blake believed that Newton’s scientific approach to the world was too reductive. Here he implies Newton is so fixated on his calculations that he is blind to the world around him. This is one of only 12 large colour prints Blake made. He seems to have used an experimental hybrid of printing, drawing, and painting.
From the Tate Britain
See Lawrence (2024) Blake, William Newton p. 121–123, 258, 260, 283, 284, 301, 306.
Lunette Rehoboam Abijah
Many of Blake’s works are inspired by engravings he saw of the Sistine chapel ceiling. The pose of Newton is taken from the Lunette depiction of Abijah, one of the Michelangeo’s ancestors of Christ.

Figure: Lunette containing Rehoboam and Abijah.
People, Communication and Culture
Human intelligence is a social intelligence: it is isolated, but it doesn’t exist in isolation. It sits instead within a broader culture. The term ‘culture’ originates from the Roman orator Cicero, who wrote of cultura animi, the cultivation of our minds. He drew an analogy with agriculture: human knowledge is cultivated similarly to the way crops are raised from the land: our minds grow and respond to their intellectual environment.
It is impossible to understand humans without understanding our context, and human culture is a key part of that context, but the cul- ture that sustains our minds is also evolving. Over time, how we see ourselves within the universe has changed. The world looks different to us today than it did to Michelangelo. Many of these changes have improved our ability to understand the world around us.
Figure: People communicate through artifacts and culture.
See Lawrence (2024) Cicero and culture p. 20-21.

Figure: This is the drawing Dan was inspired to create for Chapter 4. It highlights how even if these machines can generate creative works the lack of origin in humans menas it is not the same as works of art that come to us through history.
See blog post on Art is Human..
For the Working Group for the Royal Society report on Machine Learning, back in 2016, the group worked with Ipsos MORI to engage in public dialogue around the technology. Ever since I’ve been struck about how much more sensible the conversations that emerge from public dialogue are than the breathless drivel that seems to emerge from supposedly more informed individuals.
There were a number of messages that emerged from those dialogues, and many of those messages were reinforced in two further public dialogues we organised in September.
However, there was one area we asked about in 2017, but we didn’t ask about in 2024. That was an area where the public unequivocal that they didn’t want the research community to pursue progress. Quoting from the report (my emphasis).
Art: Participants failed to see the purpose of machine learning-written poetry. For all the other case studies, participants recognised that a machine might be able to do a better job than a human. However, they did not think this would be the case when creating art, as doing so was considered to be a fundamentally human activity that machines could only mimic at best.
Public Views of Machine Learning, April, 2017
How right they were.
The Sorcerer’s Apprentice
See this blog post on The Open Society and its AI.

Figure: A young sorcerer learns his masters spells, and deploys them to perform his chores, but can’t control the result.
In Goethe’s poem The Sorcerer’s Apprentice, a young sorcerer learns one of their master’s spells and deploys it to assist in his chores. Unfortunately, he cannot control it. The poem was popularised by Paul Dukas’s musical composition, in 1940 Disney used the composition in the film Fantasia. Mickey Mouse plays the role of the hapless apprentice who deploys the spell but cannot control the results.
When it comes to our software systems, the same thing is happening. The Harvard Law professor, Jonathan Zittrain calls the phenomenon intellectual debt. In intellectual debt, like the sorcerer’s apprentice, a software system is created but it cannot be explained or controlled by its creator. The phenomenon comes from the difficulty of building and maintaining large software systems: the complexity of the whole is too much for any individual to understand, so it is decomposed into parts. Each part is constructed by a smaller team. The approach is known as separation of concerns, but it has the unfortunate side effect that no individual understands how the whole system works. When this goes wrong, the effects can be devastating. We saw this in the recent Horizon scandal, where neither the Post Office or Fujitsu were able to control the accounting system they had deployed, and we saw it when Facebook’s systems were manipulated to spread misinformation in the 2016 US election.
In 2019 Mark Zuckerberg wrote an op-ed in the Washington Post calling for regulation of social media. He was repeating the realisation of Goethe’s apprentice, he had released a technology he couldn’t control. In Goethe’s poem, the master returns, “Besen, besen! Seid’s gewesen” he calls, and order is restored, but back in the real world the role of the master is played by Popper’s open society. Unfortunately, those institutions have been undermined by the very spell that these modern apprentices have cast. The book, the letter, the ledger, each of these has been supplanted in our modern information infrastructure by the computer. The modern scribes are software engineers, and their guilds are the big tech companies. Facebook’s motto was to “move fast and break things”. Their software engineers have done precisely that and the apprentice has robbed the master of his powers. This is a desperate situation, and it’s getting worse. The latest to reprise the apprentice’s role are Sam Altman and OpenAI who dream of “general intelligence” solutions to societal problems which OpenAI will develop, deploy, and control. Popper worried about the threat of totalitarianism to our open societies, today’s threat is a form of information totalitarianism which emerges from the way these companies undermine our institutions.
So, what to do? If we value the open society, we must expose these modern apprentices to scrutiny. Open development processes are critical here, Fujitsu would never have got away with their claims of system robustness for Horizon if the software they were using was open source. We also need to re-empower the professions, equipping them with the resources they need to have a critical understanding of these technologies. That involves redesigning the interface between these systems and the humans that empowers civil administrators to query how they are functioning. This is a mammoth task. But recent technological developments, such as code generation from large language models, offer a route to delivery.
The open society is characterised by institutions that collaborate with each otherin the pragmatic pursuit of solutions to social problems. The large tech companies that have thrived because of the open society are now putting that ecosystem in peril. For the open society to survive it needs to embrace open development practices that enable Popper’s piecemeal social engineers to come back together and chant “Besen, besen! Seid’s gewesen.” Before it is too late for the master to step in and deal with the mess the apprentice has made.
See Lawrence (2024) sorcerer’s apprentice p. 371-374.
The Open Society and its Enemies

Figure: The Open Society and Its Enemies by Karl Popper views liberal democracies as a collection of “piecemeal social engineers” who strive towards better outcomes.
Popper opened the preface to his book (Popper, 1945) with the following words:
If in this book harsh words are spoken about some of the greatest among the intellectual leaders of mankind, my motive is not, I hope, to belittle them. It springs rather from my conviction that, if our civilization is to survive, we must break with the habit of deference to great men. Great men may make great mistakes; and as the book tries to show, some of the greatest leaders of the past supported the perennial attack on freedom and reason.
He had written the book against the background of the second world war, his decision to write it taken on the day the Nazis invaded Austria in March 1938. His book is a reaction to totalitarianism.
For Popper, the ideas of “great men” become totalitarian when imposed on society. He advocates for direct liberal democracy as the only form of government that can allow for institutional change without bloodshed. The open society is one characterized by institutions and individuals that can engage in the practical pursuit of solutions to social and political problems. The institutions are also underpinned by individuals: lawyers, accountants, civil administrators and many more. To Popper it is these “piecemeal social engineers” who offer pragmatic solutions to our society’s political and social challenges.
See Lawrence (2024) Popper, Karl The Open Society and its Enemies p. 371–374.
Information Topography: How AI Reshapes Organizational Decision Making
The API Mandate
The API Mandate was a memo issued by Jeff Bezos in 2002. Internet folklore has the memo making five statements:
- All teams will henceforth expose their data and functionality through service interfaces.
- Teams must communicate with each other through these interfaces.
- There will be no other form of inter-process communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
- It doesn’t matter what technology they use.
- All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
The mandate marked a shift in the way Amazon viewed software, moving to a model that dominates the way software is built today, so-called “Software-as-a-Service”.
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
Conway (n.d.)
The law is cited in the classic software engineering text, The Mythical Man Month (Brooks, n.d.).
As a result, and in awareness of Conway’s law, the implementation of this mandate also had a dramatic effect on Amazon’s organizational structure.
Because the design that occurs first is almost never the best possible, the prevailing system concept may need to change. Therefore, flexibility of organization is important to effective design.
Conway (n.d.)
Amazon is set up around the notion of the “two pizza team”. Teams of 6-10 people that can be theoretically fed by two (American) pizzas. This structure is tightly interconnected with the software. Each of these teams owns one of these “services”. Amazon is strict about the team that develops the service owning the service in production. This approach is the secret to their scale as a company, and the approach has been adopted by many other large tech companies. The software-as-a-service approach changed the information infrastructure of the company. The routes through which information is shared. This had a knock-on effect on the corporate culture.
Amazon works through an approach I think of as “devolved autonomy”. The culture of the company is widely taught (e.g. Customer Obsession, Ownership, Frugality), a team’s inputs and outputs are strictly defined, but within those parameters, teams have a great of autonomy in how they operate. The information infrastructure was devolved, so the autonomy was devolved. The different parts of Amazon are then bound together through shared corporate culture.
An Attention Economy
I don’t know what the future holds, but there are three things that (in the longer term) I think we can expect to be true.
- Human attention will always be a “scarce resource” (See Simon, 1971)
- Humans will never stop being interested in other humans.
- Organisations will keep trying to “capture” the attention economy.
Over the next few years our social structures will be significantly disrupted, and during periods of volatility it’s difficult to predict what will be financially successful. But in the longer term the scarce resource in the economy will be the “capital” of human attention. Even if all traditionally “productive jobs” such as manufacturing were automated, and sustainable energy problems are resolved, human attention is still the bottle neck in the economy. See Simon (1971)
Beyond that, humans will not stop being interested in other humans, sport is a nice example of this, we are as interested in the human stories of athletes as their achievements (as a series of Netflix productions evidences: Quaterback, Receiver, Drive to Survive, THe Last Dance) etc. Or the “creator economy” on YouTube. While we might prefer a future where the labour in such an economy is distributed, such that we all individually can participate in the creation as well as the consumption, my final thought is that there are significant forces to centralise this so that the many consume from the few, and companies will be financially incentivised to capture this emerging attention economy. For more on the attention economy see Tim O’Reilly’s talk here: https://www.mctd.ac.uk/watch-ai-and-the-attention-economy-tim-oreilly/.
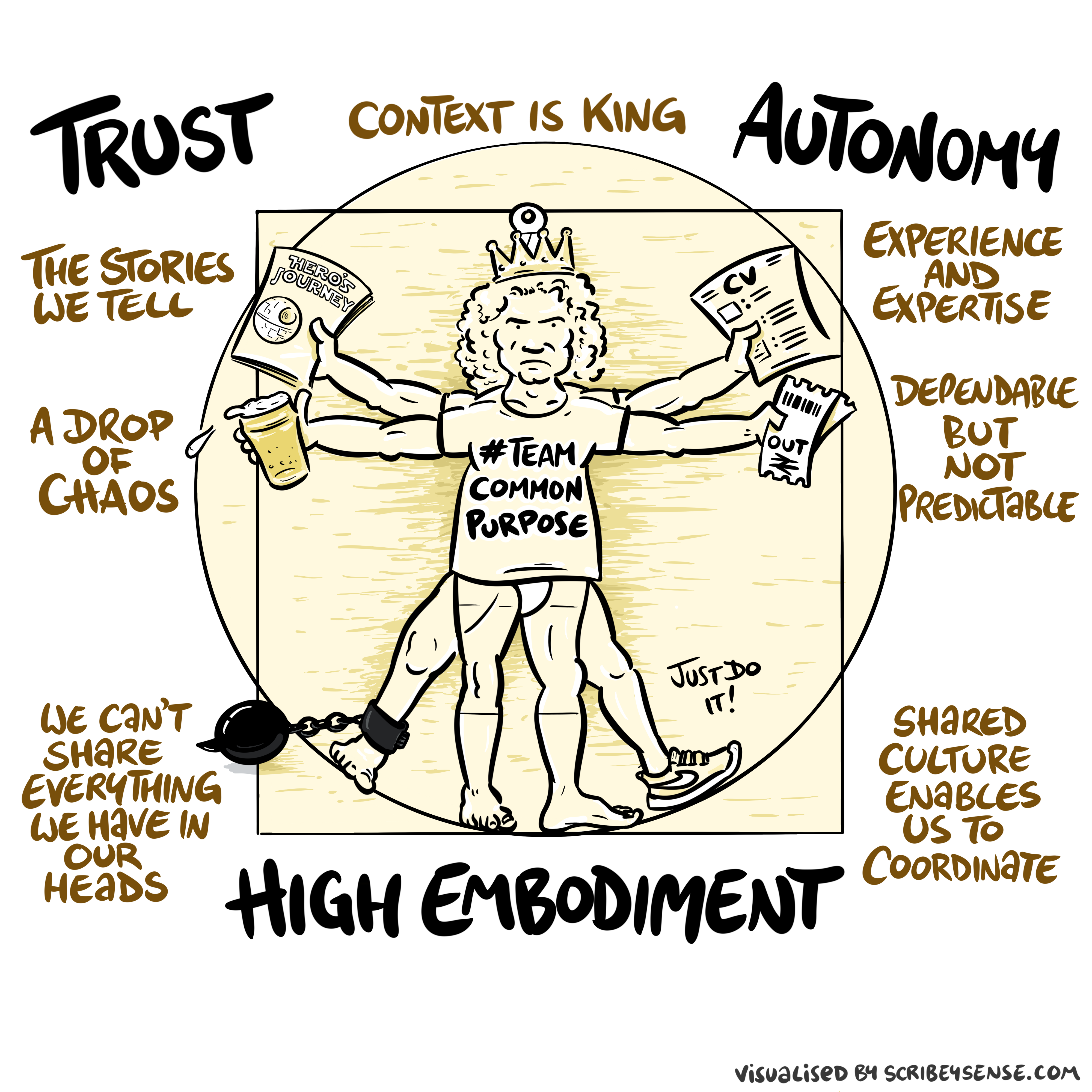
Figure: The relationships between trust, autonomy and embodiment are key to understanding how to properly deploy AI systems in a way that avoids digital autocracy. (Illustration by Dan Andrews inspired by Chapter 3 “Intent” of “The Atomic Human” Lawrence (2024))
This illustration was created by Dan Andrews after reading Chapter 3 “Intent” of “The Atomic Human” book. The chapter explores the concept of intent in AI systems and how trust, autonomy, and embodiment interact to shape our relationship with technology. Dan’s drawing captures these complex relationships and the balance needed for responsible AI deployment.
See blog post on Dan Andrews image from Chapter 3.
See blog post on Dan Andrews image from Chapter 3..
Balancing Centralized Control with Devolved Authority
Question Mark Emails

Figure: Jeff Bezos sends employees at Amazon question mark emails. They require an explaination. The explaination required is different at different levels of the management hierarchy. See this article.
One challenge at Amazon was what I call the “L4 to Q4 problem”. The issue when an graduate engineer (Level 4 in Amazon terminology) makes a change to the code base that has a detrimental effect but we only discover it when the 4th Quarter results are released (Q4).
The challenge in explaining what went wrong is a challenge in intellectual debt.
Executive Sponsorship
Another lever that can be deployed is that of executive sponsorship. My feeling is that organisational change is most likely if the executive is seen to be behind it. This feeds the corporate culture. While it may be a necessary condition, or at least it is helpful, it is not a sufficient condition. It does not solve the challenge of the institutional antibodies that will obstruct long term change. Here by executive sponsorship I mean that of the CEO of the organisation. That might be equivalent to the Prime Minister or the Cabinet Secretary.
A key part of this executive sponsorship is to develop understanding in the executive of how data driven decision making can help, while also helping senior leadership understand what the pitfalls of this decision making are.
Pathfinder Projects
I do exec education courses for the Judge Business School. One of my main recommendations there is that a project is developed that directly involves the CEO, the CFO and the CIO (or CDO, CTO … whichever the appropriate role is) and operates on some aspect of critical importance for the business.
The inclusion of the CFO is critical for two purposes. Firstly, financial data is one of the few sources of data that tends to be of high quality and availability in any organisation. This is because it is one of the few forms of data that is regularly audited. This means that such a project will have a good chance of success. Secondly, if the CFO is bought in to these technologies, and capable of understanding their strengths and weaknesses, then that will facilitate the funding of future projects.
In the DELVE data report (The DELVE Initiative, 2020), we translated this recommendation into that of “pathfinder projects”. Projects that cut across departments, and involve treasury. Although I appreciate the nuances of the relationship between Treasury and No 10 do not map precisely onto that of CEO and CFO in a normal business. However, the importance of cross cutting exemplar projects that have the close attention of the executive remains.
Human-Analogue Machines (HAMs) as Business Tools
The MONIAC
The MONIAC was an analogue computer designed to simulate the UK economy. Analogue comptuers work through analogy, the analogy in the MONIAC is that both money and water flow. The MONIAC exploits this through a system of tanks, pipes, valves and floats that represent the flow of money through the UK economy. Water flowed from the treasury tank at the top of the model to other tanks representing government spending, such as health and education. The machine was initially designed for teaching support but was also found to be a useful economic simulator. Several were built and today you can see the original at Leeds Business School, there is also one in the London Science Museum and one in the Unisversity of Cambridge’s economics faculty.

Figure: Bill Phillips and his MONIAC (completed in 1949). The machine is an analogue computer designed to simulate the workings of the UK economy.
See Lawrence (2024) MONIAC p. 232-233, 266, 343.
Human Analogue Machine
Recent breakthroughs in generative models, particularly large language models, have enabled machines that, for the first time, can converse plausibly with other humans.
The Apollo guidance computer provided Armstrong with an analogy when he landed it on the Moon. He controlled it through a stick which provided him with an analogy. The analogy is based in the experience that Amelia Earhart had when she flew her plane. Armstrong’s control exploited his experience as a test pilot flying planes that had control columns which were directly connected to their control surfaces.
Figure: The human analogue machine is the new interface that large language models have enabled the human to present. It has the capabilities of the computer in terms of communication, but it appears to present a “human face” to the user in terms of its ability to communicate on our terms. (Image quite obviously not drawn by generative AI!)
The generative systems we have produced do not provide us with the “AI” of science fiction. Because their intelligence is based on emulating human knowledge. Through being forced to reproduce our literature and our art they have developed aspects which are analogous to the cultural proxy truths we use to describe our world.
These machines are to humans what the MONIAC was the British economy. Not a replacement, but an analogue computer that captures some aspects of humanity while providing advantages of high bandwidth of the machine.
HAM
The Human-Analogue Machine or HAM therefore provides a route through which we could better understand our world through improving the way we interact with machines.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
The HAM can provide an interface between the digital computer and the human allowing humans to work closely with computers regardless of their understandin gf the more technical parts of software engineering.
Figure: The HAM now sits between us and the traditional digital computer.
Of course this route provides new routes for manipulation, new ways in which the machine can undermine our autonomy or exploit our cognitive foibles. The major challenge we face is steering between these worlds where we gain the advantage of the computer’s bandwidth without undermining our culture and individual autonomy.
See Lawrence (2024) human-analogue machine (HAMs) p. 343-347, 359-359, 365-368.
Conclusion: The Business Imperative
AI cannot replace atomic human
Figure: Opinion piece in the FT that describes the idea of a social flywheel to drive the targeted growth we need in AI innovation.

Figure: Society faces many wicked problems in health, education, security, and social care that require carefully deploying AI toward meaningful societal challenges rather than focusing on commercially appealing applications. (Illustration by Dan Andrews inspired by the Epilogue of “The Atomic Human” Lawrence (2024))
This illustration was created by Dan Andrews after reading the Epilogue of “The Atomic Human” book. The Epilogue discusses how we might deploy AI to address society’s most pressing challenges, and Dan’s drawing captures the various wicked problems we face and some of the initiatives that are looking to address them.
See blog post on Who is Stepping Up?.
See blog post on Who is Stepping Up?.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com