data : observations, could be actively or passively acquired (meta-data).
model : assumptions, based on previous experience (other data! transfer learning etc), or beliefs about the regularities of the universe. Inductive bias.
prediction : an action to be taken or a categorization or a quality score.
E.g. least squares \[\errorFunction(\boldsymbol{\beta}, \dataMatrix, \inputMatrix) = \sum_{i=1}^\numData \left(\dataScalar_i - \mappingFunction(\inputVector_i, \boldsymbol{\beta})\right)^2.\]
Two Components
Prediction function, \(\mappingFunction(\cdot)\)
Objective function, \(\errorFunction(\cdot)\)
Deep Learning
These are interpretable models: vital for disease modeling etc.
Modern machine learning methods are less interpretable
Example: face recognition
DeepFace
Outline of the DeepFace architecture. A front-end of a single convolution-pooling-convolution filtering on the rectified input, followed by three locally-connected layers and two fully-connected layers. Color illustrates feature maps produced at each layer. The net includes more than 120 million parameters, where more than 95% come from the local and fully connected.
Source: DeepFace (Taigman et al., 2014)
Deep Learning as Pinball
Uncertainty and Learning
In this “vanilla” form these machines “don’t know when they don’t know”.
Doubt is vital in real world decision making.
Incorporating this in systems is a long time focus of my technical research.
Comparison with Human Learning & Embodiment
The emulation of intelligence does not exhibit all the meta-modelling humans perform.
Data Science and Professionalisation
Industrial Revolution 4.0?
Industrial Revolution (1760-1840) term coined by Arnold Toynbee (1852-1883).
Maybe: But this one is dominated by data not capital
A revolution in information rather than energy.
That presents challenges and opportunities
Consider Apple vs Nokia: How you handle disruption.
New technologies historically led to new professions:
Brunel (born 1806): Civil, mechanical, naval
Tesla (born 1856): Electrical and power
William Shockley (born 1910): Electronic
Watts S. Humphrey (born 1927): Software
Why?
Codification of best practice.
Developing trust
Where are we?
Perhaps around the 1980s of programming.
We understand if, for, and procedures
But we don’t share best practice.
Let’s avoid the over formalisation of software engineering.
The Software Crisis
The major cause of the software crisis is that the machines have become several orders of magnitude more powerful! To put it quite bluntly: as long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a mild problem, and now we have gigantic computers, programming has become an equally gigantic problem.
Edsger Dijkstra (1930-2002), The Humble Programmer
The Data Crisis
The major cause of the data crisis is that machines have become more interconnected than ever before. Data access is therefore cheap, but data quality is often poor. What we need is cheap high-quality data. That implies that we develop processes for improving and verifying data quality that are efficient.
There would seem to be two ways for improving efficiency. Firstly, we should not duplicate work. Secondly, where possible we should automate work.
{Our current information infrastructure bears a close relation with feudal systems of government. In the feudal system a lord had a duty of care over his serfs and vassals, a duty to protect subjects. But in practice there was a power-asymetry. In feudal days protection was against Viking raiders, today, it is against information raiders. However, when there is an information leak, when there is some failure in protections, it is already too late.
Alternatively, our data is publicly shared, as in an information commons. Akin to common land of the medieval village. But just as commons were subject to overgrazing and poor management, so it is that much of our data cannot be managed in this way. In particularly personal, sensitive data.
I explored this idea further in this .
Rest of the Talk
Importance of data infrastructure
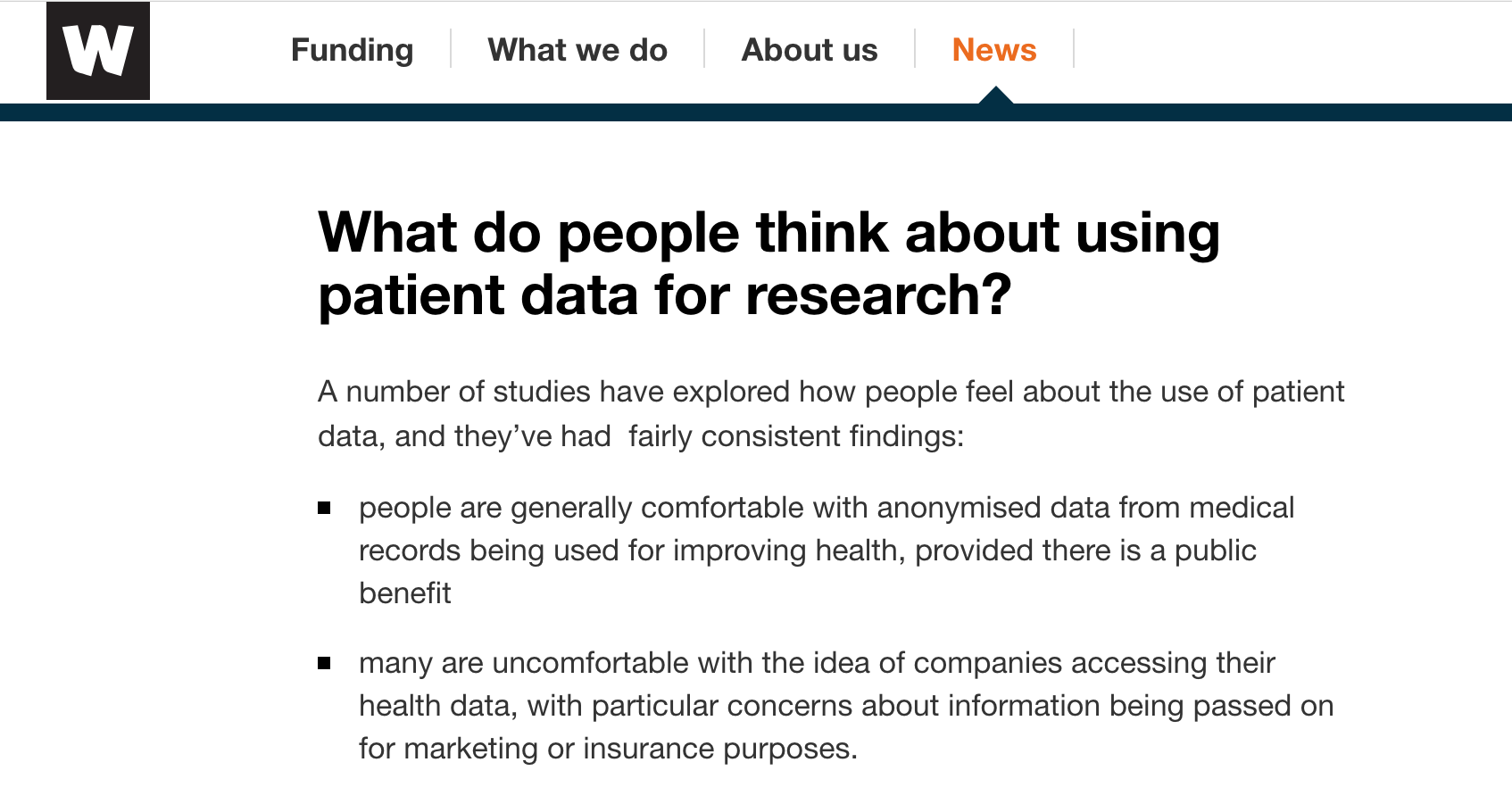
Understanding Patient Data
WannaCry
Bush Pilot Model
The difference between capability and intent.
Motivation
Indsidious decision-making that has downstream instrumental effects we don’t control.
A power-asymmetry between data-controllers and data-subjects
A loss of personhood in the re-representation of ourselves in the digital world.
The GDPR’s endeavour to curb contractual freedom cannot by itself reverse the power-asymmetry between data-controllers and data-subjects.
Analogy
Digital Democracy vs Digital Oligarchy Lawrence (2015a) or Information Feudalism Lawrence (2015b)
Data subjects, data controllers and data processors.
Legal Mechanism of Trusts
Fiduciary responsibility of Trustees.
Burden of proof in negligence is reversed.
Trustees are data controllers
Beneficiaries are data subjects
Power of data accumulation wielded on the beneficiaries behalf
See Edwards (2004), Delacroix and Lawrence (2019) and Lawrence (2016)
Delacroix, S., Lawrence, N.D., 2019. Bottom-up data trusts: Disturbing the “one size fits all” approach to data governance. International Data Privacy Law. https://doi.org/10.1093/idpl/ipz014
Edwards, L., 2004. The problem with privacy. International Review of Law Computers & Technology 18, 263–294.
Lawrence, N.D., 2017. Living together: Mind and machine intelligence. arXiv.
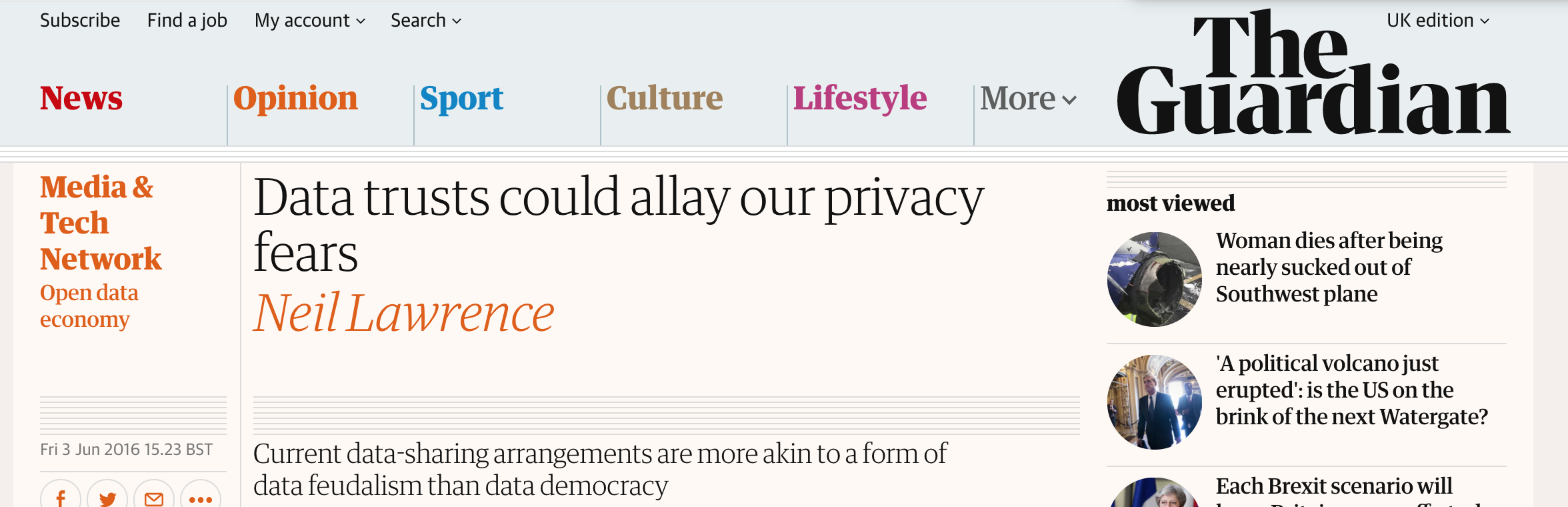
Lawrence, N.D., 2016. Data trusts could allay our privacy fears.
Lawrence, N.D., 2015a. Beware the rise of the digital oligarchy.
Lawrence, N.D., 2015b. The information barons threaten our autonomy and our privacy.
Taigman, Y., Yang, M., Ranzato, M., Wolf, L., 2014. DeepFace: Closing the gap to human-level performance in face verification, in: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2014.220