AI for Science: An Oral Report from a Recent Dagstuhl Workshop
Abstract
As part of the Accelerate Science programme with Jess Montgomery, the University of Tuebingen, the University of Wisconsin, and NYU we recently hosted a week-long programme at the Leibniz-Zentrum für Informatik in Dagstuhl, Germany. In this talk Neil will give an oral report on the discussions sharing some of the ideas presented at the meeting. The ideas will feed into a longer report on the area produced by the Accelerate Science team.
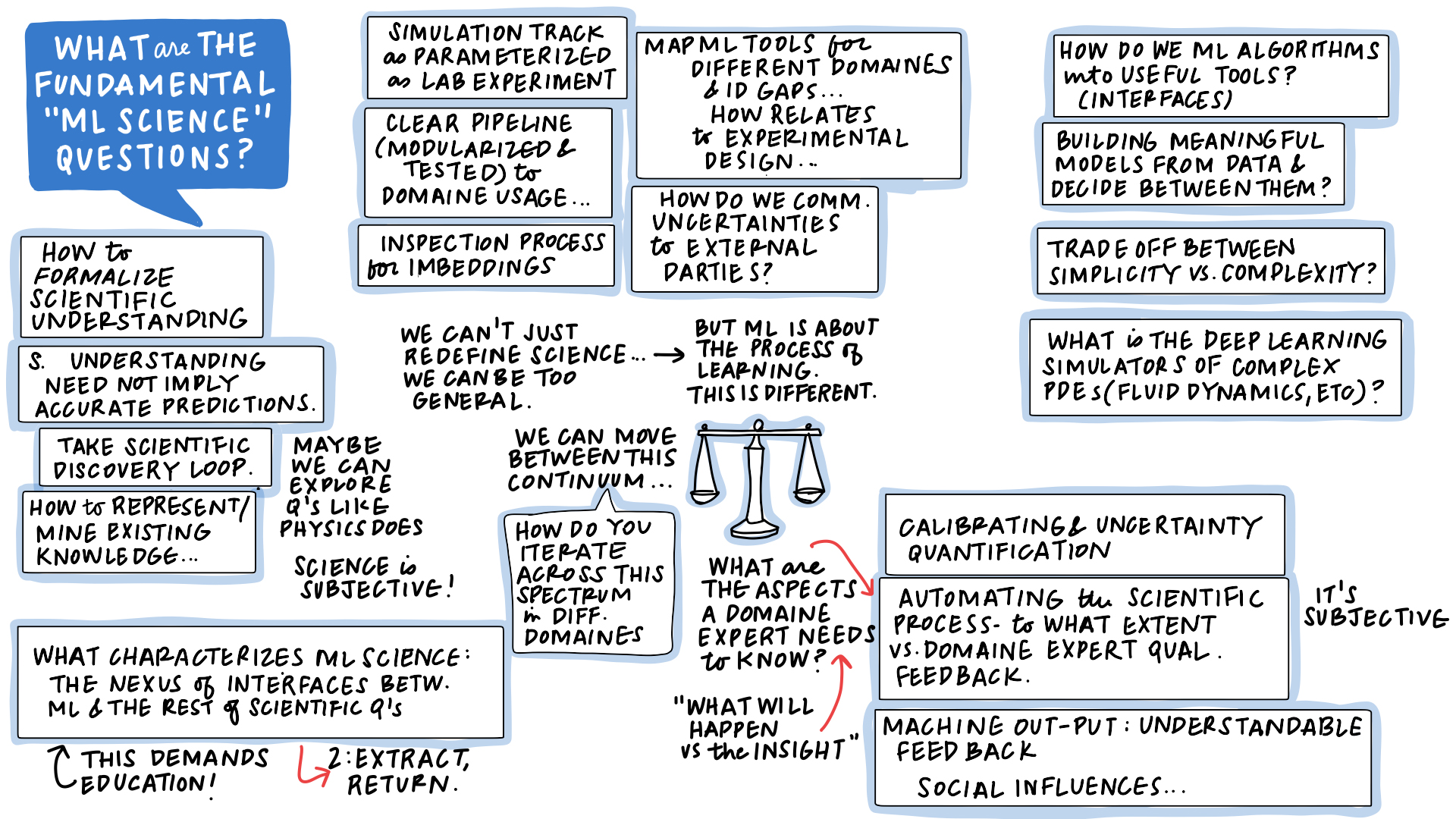

Figure:
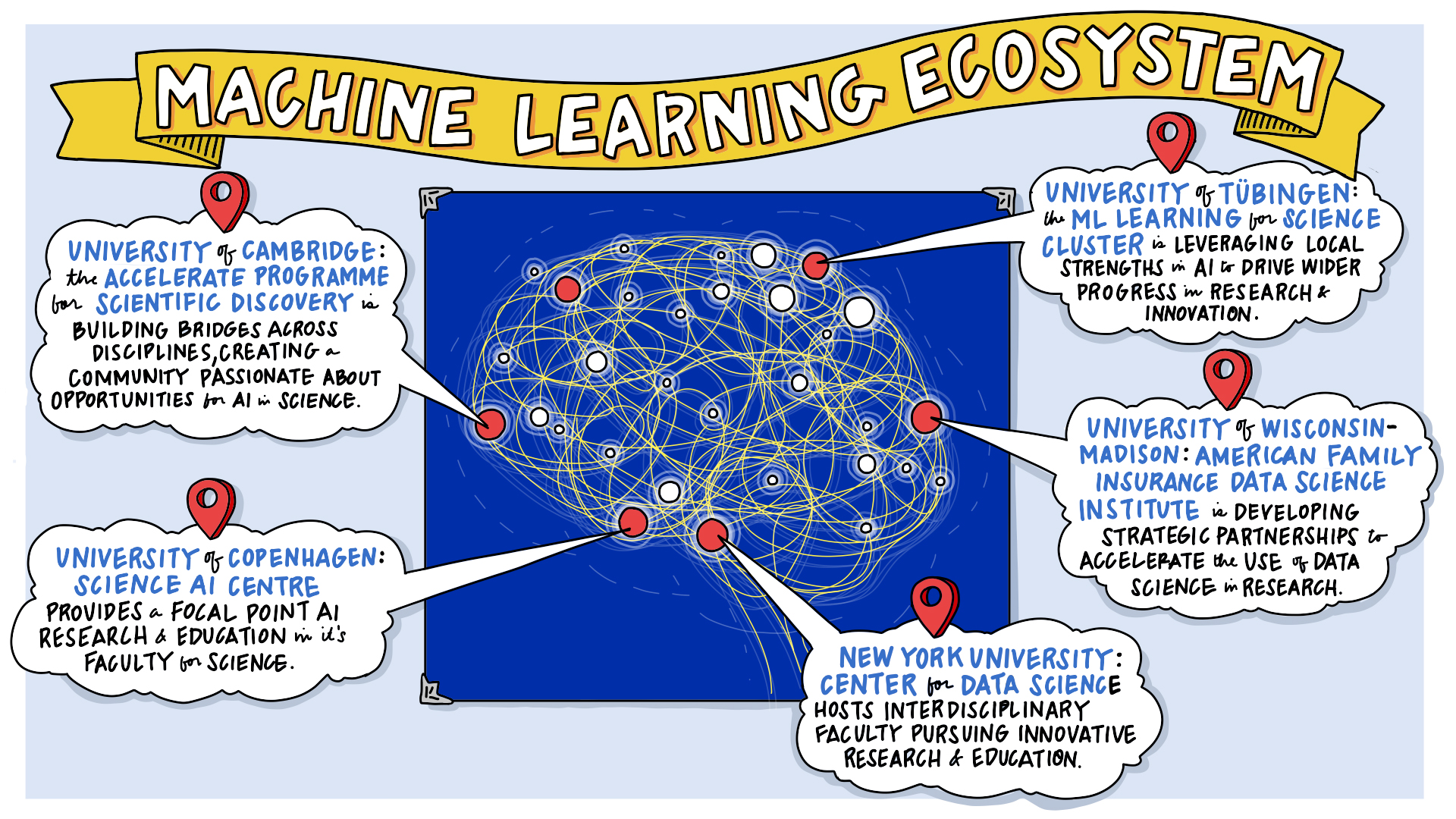
Figure:
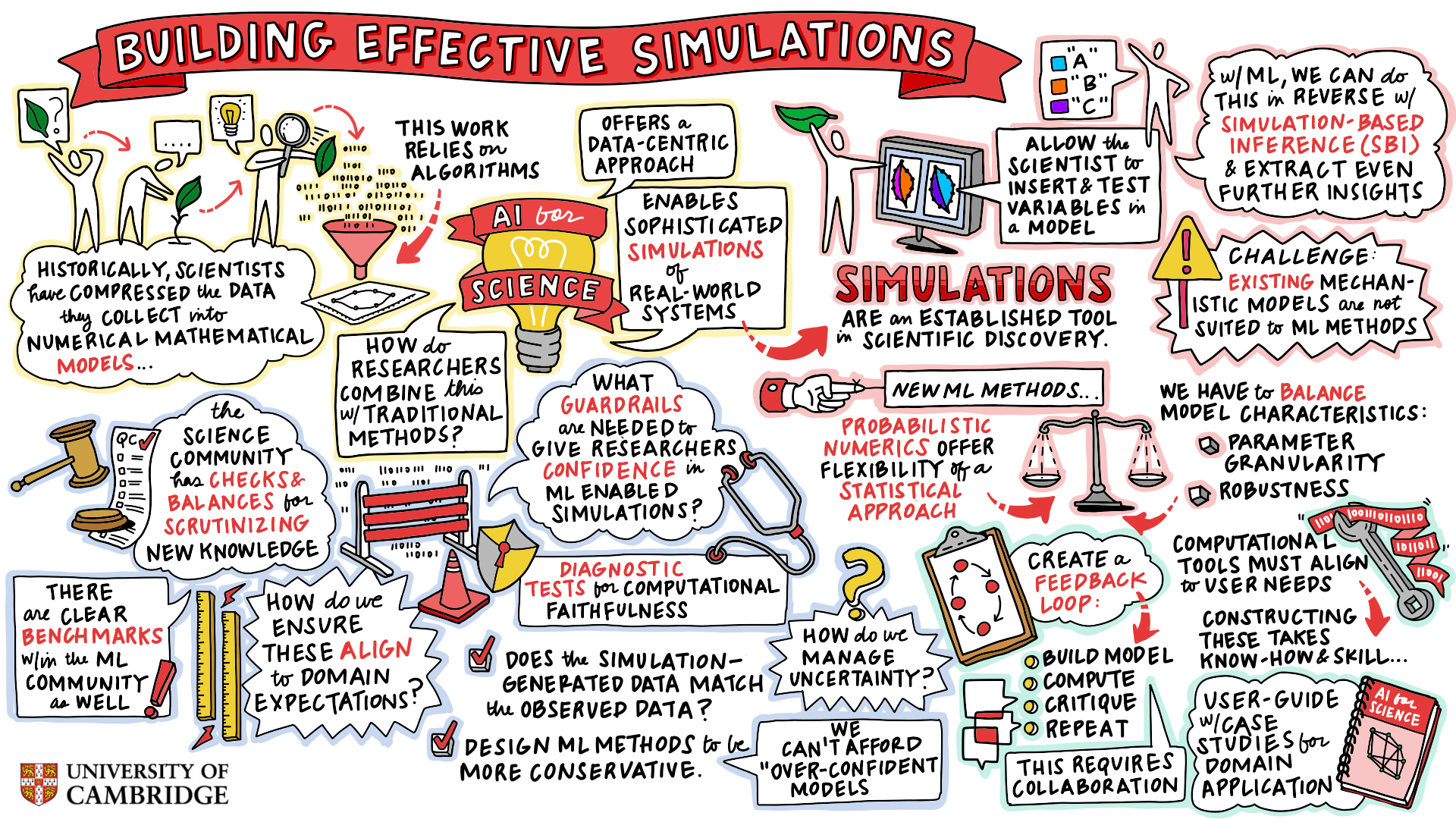
Figure:
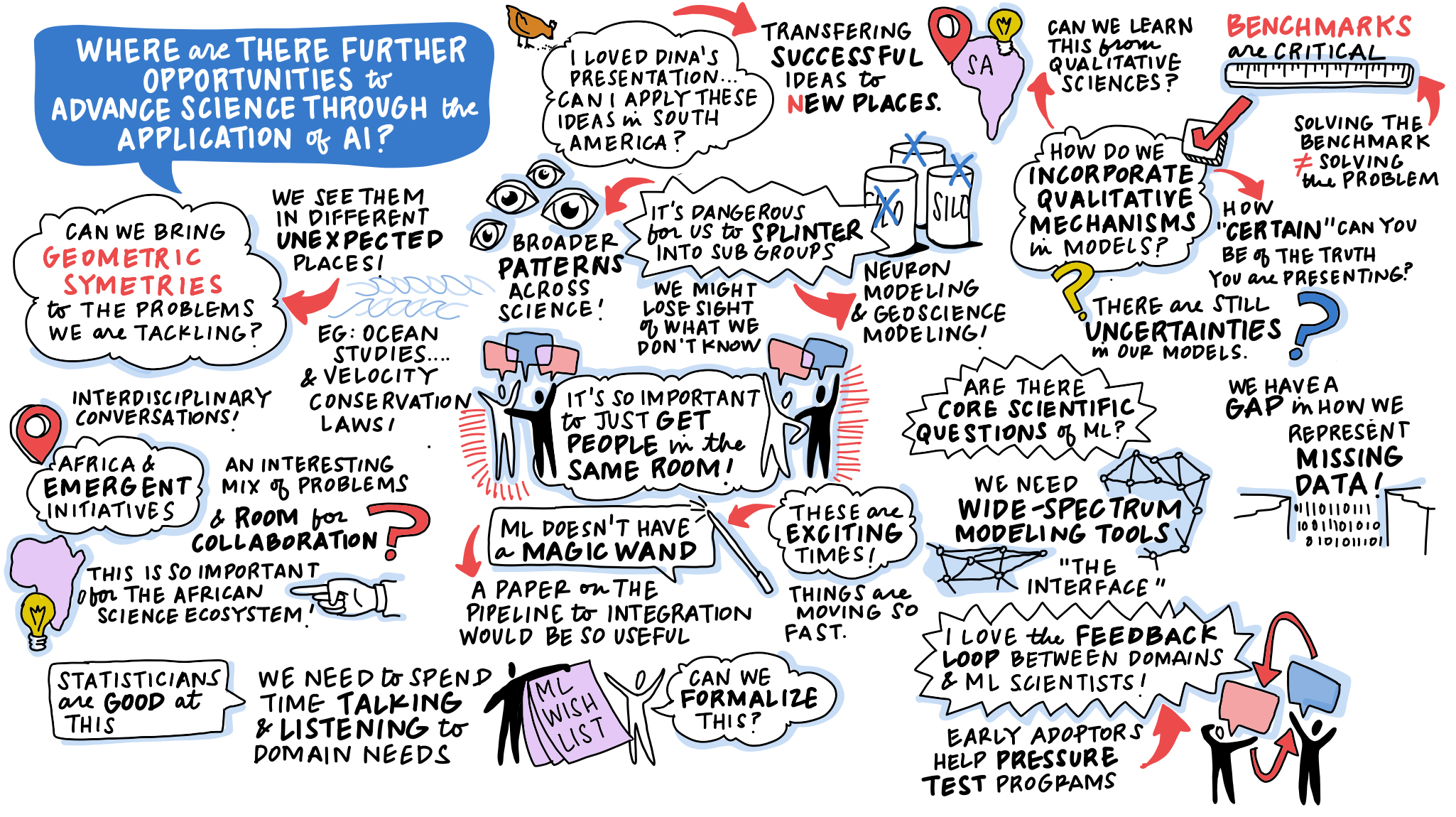
Figure:
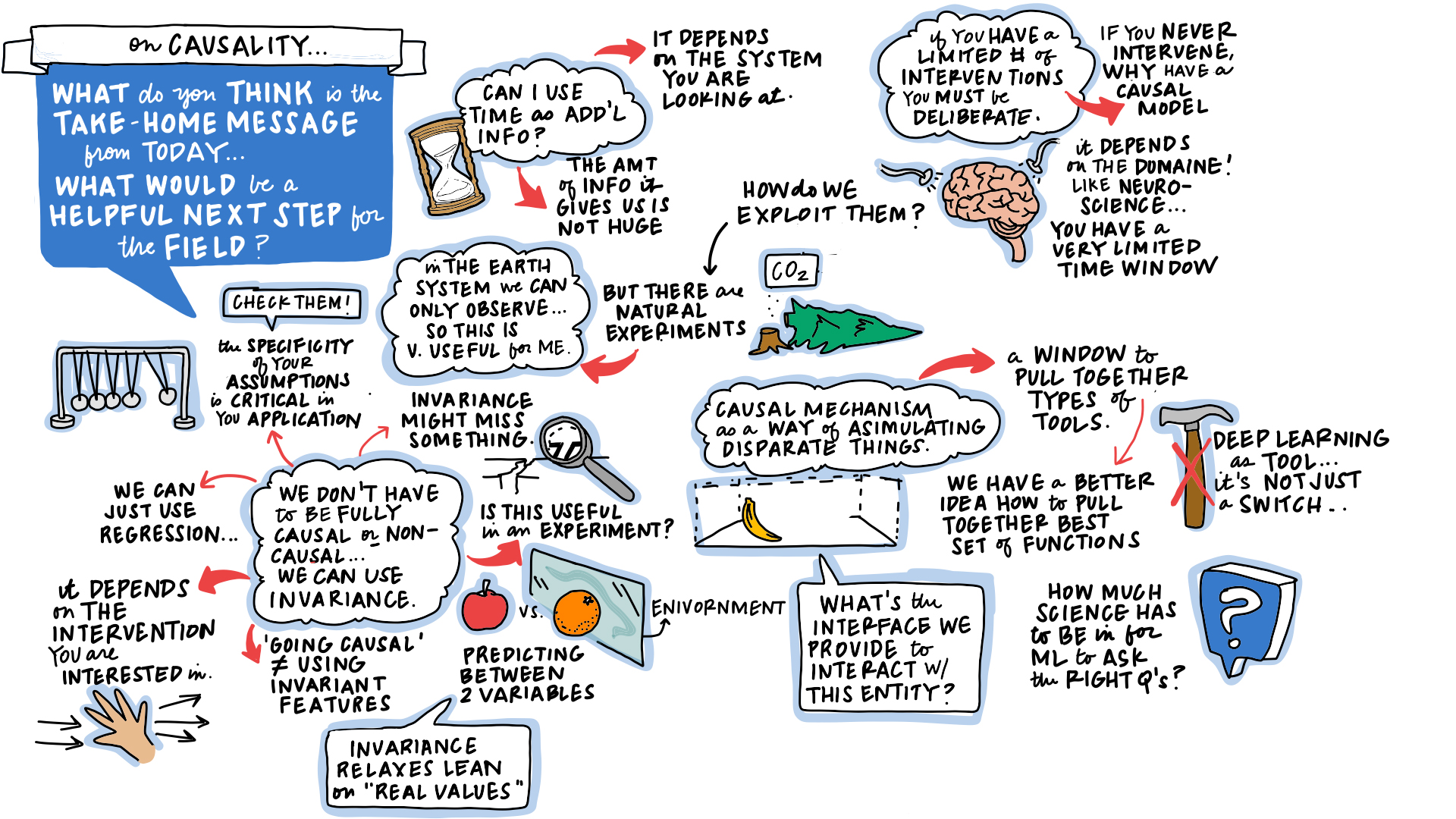
Figure:
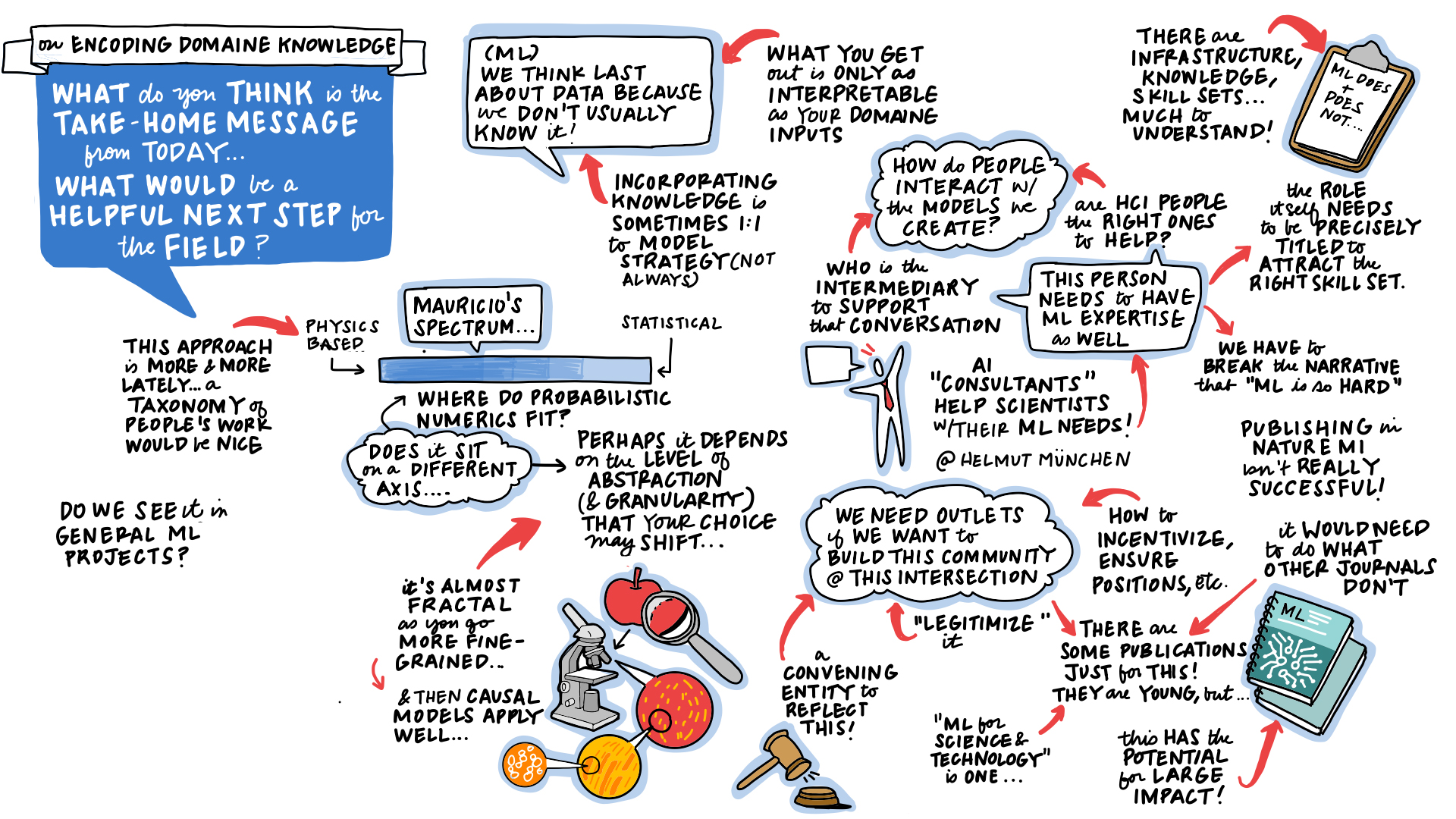
Figure:

Figure:
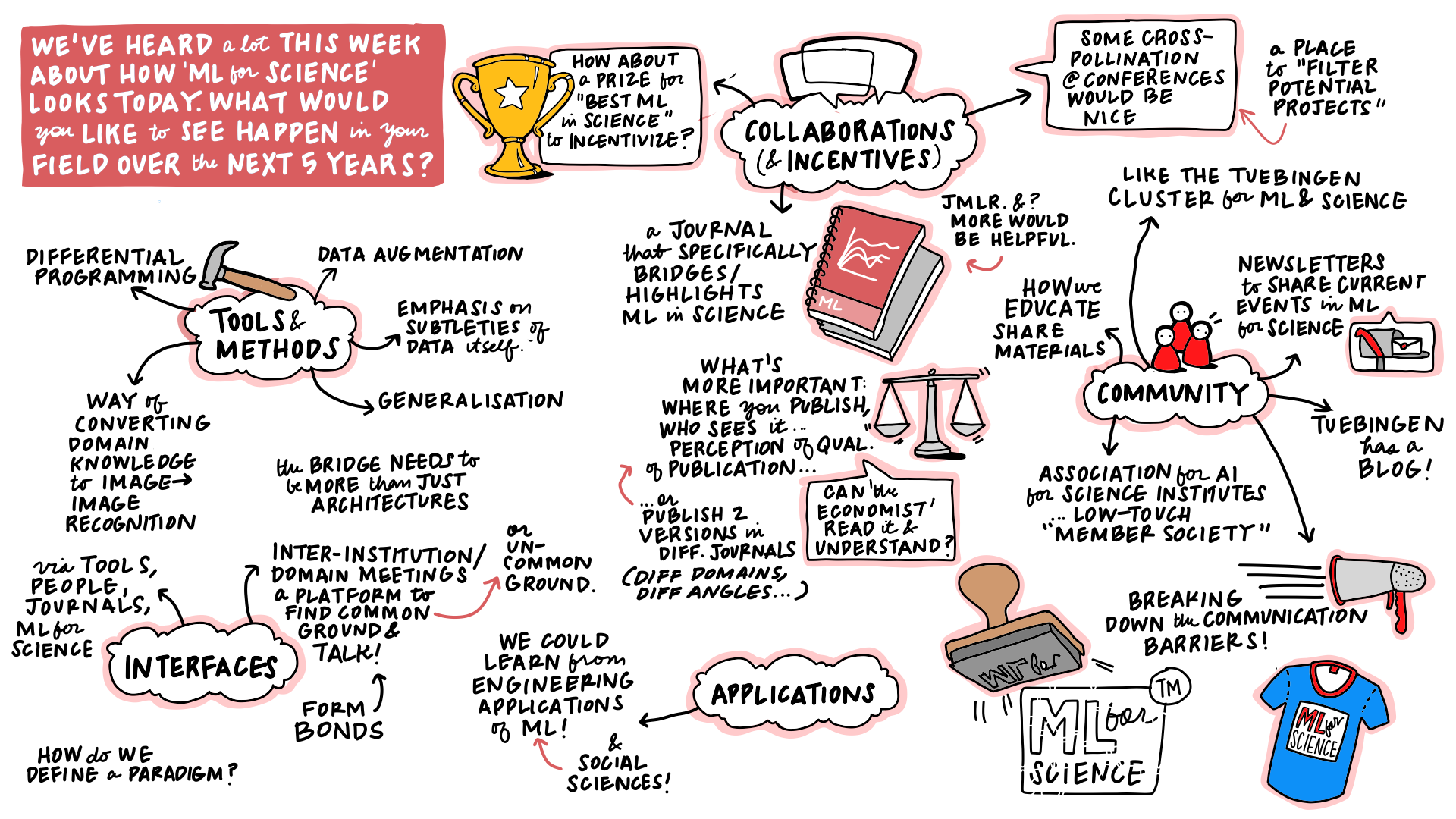
Figure:
With thanks to Jessical Beasley (Collective Next) for graphic facilitaton and Jessica Montgomery, Ule von Luxburg, Philipp Berens and Kyle Cranmer for co-organisation as well as all attendees.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com