Educating the Atomic Human
Abstract
How do we assimilate artificial intelligence technologies in a way that respects the essence of humanity? The answer lies in education, but the nature of education will also radically change in the face of these technologies. In this shifting landscape we first step back and explore the essence of being human in the age of AI.
Drawing parallels between AI as a modern philosopher’s stone we argue we are facing a battle between attention capture and reinvestment, and explain how education and skills are at the heart of preserving our human essence within that battle.
Artificial General Vehicle


Figure: The notion of artificial general intelligence is as absurd as the notion of an artifical general vehicle.
I often turn up to book talks with my Brompton bicycle. Embarrassingly I even took it to Google which is only a 30 second walk from King’s Cross station. That made me realise it’s become a sort of security blanket. I like having it because it’s such a flexible means of transport.
But is the Brompton an “artificial general vehicle”? A vehicle that can do everything? Unfortunately not, for example it’s not very good for flying to the USA. There is no artificial general vehicle that is optimal for every journey. Similarly there is no such thing as artificial general intelligence. The idea is artificial general nonsense.
That doesn’t mean there aren’t different principles to intelligence we can look at. Just like vehicles have principles that apply to them. When designing vehicles we need to think about air resistance, friction, power. We have developed solutions such as wheels, different types of engines and wings that are deployed across different vehicles to achieve different results.
Intelligence is similar. The notion of artificial general intelligence is fundamentally eugenic. It builds on Spearman’s term “general intelligence” which is part of a body of literature that was looking to assess intelligence in the way we assess height. The objective then being to breed greater intelligences (Lyons, 2022).
Figure: This is the drawing Dan was inspired to create for Chapter 3.
See blog post on Dan Andrews image from Chapter 3..
More like machines?
AI: The Modern Philosopher’s Stone
Just as medieval alchemists sought the philosopher’s stone to transmute base metals into gold, today’s tech industry presents AI as a magical transformer of human capital.
The Promise of Transformation
The philosopher’s stone of AI promises to:
- Transform human knowledge into automated systems
- Convert human experience into scalable algorithms
- Transmute human creativity into reproducible outputs
- Turn human judgment into computational decisions
The Hidden Cost
Like alchemy, this transformation comes with hidden costs:
- Devaluation of human expertise
- Loss of tacit knowledge
- Erosion of human agency
- Dependency on technological systems
Beyond the Myth
Understanding AI as the modern philosopher’s stone helps us:
- Recognize the limits of technological transformation
- Value human capabilities that resist automation
- Maintain healthy skepticism of magical solutions
- Invest in human development alongside technological advancement
The philosopher’s stone metaphor reminds us that while AI offers powerful capabilities, we must be wary of seeing it as a magical solution to human challenges. True value lies in the thoughtful integration of AI with human capabilities, not in the replacement of human judgment and creativity.
AI is a Means to an End
The Battle for Attention
In our modern digital landscape, we find ourselves caught between two competing cycles: the attention capture cycle and the attention reinvestment cycle.
The Attention Capture Cycle
The attention capture cycle is characterized by:
- Algorithmic targeting of our attention
- Short-term engagement metrics
- Dopamine-driven feedback loops
- Erosion of deep thinking and reflection
- Commoditization of human attention
The Attention Reinvestment Cycle
In contrast, the attention reinvestment cycle involves:
- Conscious direction of attention
- Development of deep understanding
- Building of lasting knowledge and skills
- Creation of meaningful connections
- Investment in human capital
Breaking Free
The challenge of our time is to break free from the capture cycle and cultivate reinvestment. This requires:
- Awareness of how our attention is being targeted
- Active choices about technology use
- Development of metacognitive skills
- Creation of spaces for deep work and reflection
The attention capture cycle represents a form of cognitive extractivism, where human attention is harvested for profit. The attention reinvestment cycle offers a path to reclaim our cognitive sovereignty and invest in our collective future.
We need to “draw out the human inside us”
AI cannot replace atomic human
Figure: Opinion piece in the FT that describes the idea of a social flywheel to drive the targeted growth we need in AI innovation.
Essential Skills for the Digital Age
To thrive in this new landscape, education must foster:
- Critical thinking and information literacy
- Metacognitive awareness
- Human connection and social skills
Atrophy and Cognitive Flattening
Even if we calibrate these tools correctly so that they do represent the world appropriately we are at risk. The hippocampus is part of our brain’s cortex, one role of our hippocampus is in navigation, knowing how to move from one place to another.
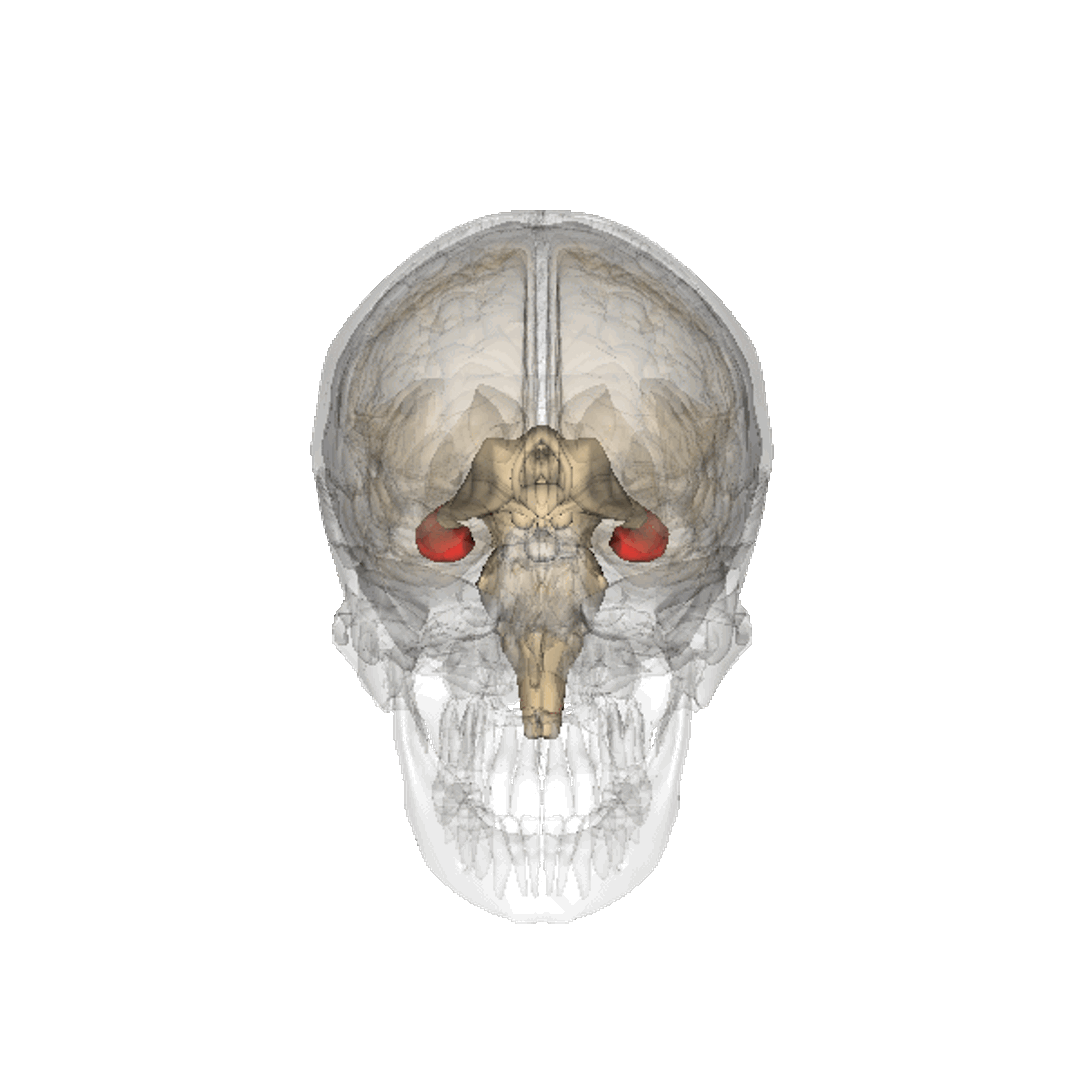
Figure: The hippocampus within the brain. Image generated from Anatomography, https://lifesciencedb.jp/.
Our prefrontal cortex, the size of which differentiates us from other primates and mammals, is the seat of our planning and of our higher intelligence. It fires in sympathy with our hippocampus.
By becoming overreliant on HAMs and there interface to the digital computer are we at risk of suffering from the same deskilling we perceive in our navigational skills? Does this place us at risk of sleepwalking into a world that is managed by the machine even as we believe that we are managing it ourselves?
The Human Teacher in the AI Age
- AI can augment but never replace the human relationship in education
- Real learning happens in the space between humans
- Education must develop both technical and deeply human capacities
- The “atomic human” - our irreducible essence - requires nurturing through authentic human connection
The Atomic Human
Figure: The Atomic Eye, by slicing away aspects of the human that we used to believe to be unique to us, but are now the preserve of the machine, we learn something about what it means to be human.
The development of what some are calling intelligence in machines, raises questions around what machine intelligence means for our intelligence. The idea of the atomic human is derived from Democritus’s atomism.
In the fifth century bce the Greek philosopher Democritus posed a question about our physical universe. He imagined cutting physical matter into pieces in a repeated process: cutting a piece, then taking one of the cut pieces and cutting it again so that each time it becomes smaller and smaller. Democritus believed this process had to stop somewhere, that we would be left with an indivisible piece. The Greek word for indivisible is atom, and so this theory was called atomism.
The Atomic Human considers the same question, but in a different domain, asking: As the machine slices away portions of human capabilities, are we left with a kernel of humanity, an indivisible piece that can no longer be divided into parts? Or does the human disappear altogether? If we are left with something, then that uncuttable piece, a form of atomic human, would tell us something about our human spirit.
See Lawrence (2024) atomic human, the p. 13.
As explored further in “The Atomic Human” book, this perspective invites us to see beyond the digital interfaces that increasingly mediate our experiences and reconnect with our fundamental human qualities.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com