The Atomic Human
Abstract
A vital perspective is missing from the discussions we’re having about Artificial Intelligence: what does it mean for our identity?
Our fascination with AI stems from the perceived uniqueness of human intelligence. We believe it’s what differentiates us. Fears of AI not only concern how it invades our digital lives, but also the implied threat of an intelligence that displaces us from our position at the centre of the world.
Atomism, proposed by Democritus, suggested it was impossible to continue dividing matter down into ever smaller components: eventually we reach a point where a cut cannot be made (the Greek for uncuttable is ‘atom’). In the same way, by slicing away at the facets of human intelligence that can be replaced by machines, AI uncovers what is left: an indivisible core that is the essence of humanity.
I’ll contrast our own (evolved, locked-in, embodied) intelligence with the capabilities of machine intelligence and speculate on what it means for our futures.
This talk is based on Neil’s forthcoming book to be published with Allen Lane in June 2024.
The Atomic Human


Figure: The Atomic Eye, by slicing away aspects of the human that we used to believe to be unique to us, but are now the preserve of the machine, we learn something about what it means to be human.
The development of what some are calling intelligence in machines, raises questions around what machine intelligence means for our intelligence. The idea of the atomic human is derived from Democritus’s atomism.
In the fifth century bce the Greek philosopher Democritus posed a similar question about our physical universe. He imagined cutting physical matter into pieces in a repeated process: cutting a piece, then taking one of the cut pieces and cutting it again so that each time it becomes smaller and smaller. Democritus believed this process had to stop somewhere, that we would be left with an indivisible piece. The Greek word for indivisible is atom, and so this theory was called atomism. This book considers this question, but in a different domain, asking: As the machine slices away portions of human capabilities, are we left with a kernel of humanity, an indivisible piece that can no longer be divided into parts? Or does the human disappear altogether? If we are left with something, then that uncuttable piece, a form of atomic human, would tell us something about our human spirit.
See Lawrence (2024) atomic human, the p. 13.
The Diving Bell and the Butterfly

Figure: The Diving Bell and the Buttefly is the autobiography of Jean Dominique Bauby.
The Diving Bell and the Butterfly is the autobiography of Jean Dominique Bauby. Jean Dominique, the editor of French Elle magazine, suffered a major stroke at the age of 43 in 1995. The stroke paralyzed him and rendered him speechless. He was only able to blink his left eyelid, he became a sufferer of locked in syndrome.
See Lawrence (2024) Le Scaphandre et le paillon (The Diving Bell and the Butterfly) p. 10–12.
O M D P C F B V
H G J Q Z Y X K W
Figure: The ordering of the letters that Bauby used for writing his autobiography.
How could he do that? Well, first, they set up a mechanism where he could scan across letters and blink at the letter he wanted to use. In this way, he was able to write each letter.
It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
Imagine doing all that thinking, but so little speaking, having all those thoughts and so little ability to communicate.
One challenge for the atomic human is that we are all in that situation. While not as extreme as for Bauby, when we compare ourselves to the machine, we all have a locked-in intelligence.
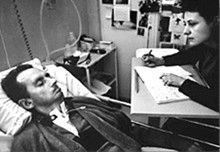
Figure: Jean Dominique Bauby was the Editor in Chief of the French Elle Magazine, he suffered a stroke that destroyed his brainstem, leaving him only capable of moving one eye. Jean Dominique became a victim of locked in syndrome.
Incredibly, Jean Dominique wrote his book after he became locked in. It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
The idea behind embodiment factors is that we are all in that situation. While not as extreme as for Bauby, we all have somewhat of a locked in intelligence.
See Lawrence (2024) Bauby, Jean Dominique p. 9–11, 18, 90, 99-101, 133, 186, 212–218, 234, 240, 251–257, 318, 368–369.
|
|

|
Figure: Claude Shannon developed information theory which allows us to quantify how much Bauby can communicate. This allows us to compare how locked in he is to us.
See Lawrence (2024) Shannon, Claude p. 10, 30, 61, 74, 98, 126, 134, 140, 143, 149, 260, 264, 269, 277, 315, 358, 363.

Figure: A Colossus Mark II codebreaking computer being operated by Dorothy Du Boisson (left) and Elsie Booker (right). Colossus was designed by Tommy Flowers, but programmed and operated by groups of Wrens based at Bletchley Park.
In the early hours of 1 June 1944, Tommy Flowers was wading ankle deep in water from a broken pipe, making the final connections to bring Mark 2 Colossus online. Colossus was the world’s first programmable, electronic, digital computer. Four days later, and Eisenhower was reading one of its first decrypts and ordering the invasion of Normandy. Flowers’s machine didn’t just launch an invasion, it launched an intellectual revolution.
See Lawrence (2024) Colossus (computer) p. 76–79, 91, 103, 108, 124, 130, 142–143, 149, 173–176, 199, 231–232, 251, 264, 267, 290, 380.
Embodiment Factors
| bits/min | billions | 2,000 |
|
billion calculations/s |
~100 | a billion |
| embodiment | 20 minutes | 5 billion years |
Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, it is a matter of thousands of millions of years. See also “Living Together: Mind and Machine Intelligence” Lawrence (2017)
There is a fundamental limit placed on our intelligence based on our ability to communicate. Claude Shannon founded the field of information theory. The clever part of this theory is it allows us to separate our measurement of information from what the information pertains to.1
Shannon measured information in bits. One bit of information is the amount of information I pass to you when I give you the result of a coin toss. Shannon was also interested in the amount of information in the English language. He estimated that on average a word in the English language contains 12 bits of information.
Given typical speaking rates, that gives us an estimate of our ability to communicate of around 100 bits per second (Reed and Durlach, 1998). Computers on the other hand can communicate much more rapidly. Current wired network speeds are around a billion bits per second, ten million times faster.
When it comes to compute though, our best estimates indicate our computers are slower. A typical modern computer can process make around 100 billion floating-point operations per second, each floating-point operation involves a 64 bit number. So the computer is processing around 6,400 billion bits per second.
It’s difficult to get similar estimates for humans, but by some estimates the amount of compute we would require to simulate a human brain is equivalent to that in the UK’s fastest computer (Ananthanarayanan et al., 2009), the MET office machine in Exeter, which in 2018 ranked as the 11th fastest computer in the world. That machine simulates the world’s weather each morning, and then simulates the world’s climate in the afternoon. It is a 16-petaflop machine, processing around 1,000 trillion bits per second.
See Lawrence (2024) embodiment factor p. 13, 29, 35, 79, 87, 105, 197, 216-217, 249, 269, 353, 369.
Bandwidth Constrained Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Embodiment factors imply that, in our communication between humans, what is not said is, perhaps, more important than what is said. To communicate with each other we need to have a model of who each of us are.
To aid this, in society, we are required to perform roles. Whether as a parent, a teacher, an employee or a boss. Each of these roles requires that we conform to certain standards of behaviour to facilitate communication between ourselves.
Control of self is vitally important to these communications.
The high availability of data available to humans undermines human-to-human communication channels by providing new routes to undermining our control of self.
The consequences between this mismatch of power and delivery are to be seen all around us. Because, just as driving an F1 car with bicycle wheels would be a fine art, so is the process of communication between humans.
If I have a thought and I wish to communicate it, I first need to have a model of what you think. I should think before I speak. When I speak, you may react. You have a model of who I am and what I was trying to say, and why I chose to say what I said. Now we begin this dance, where we are each trying to better understand each other and what we are saying. When it works, it is beautiful, but when mis-deployed, just like a badly driven F1 car, there is a horrible crash, an argument.
Sistine Chapel Ceiling
Shortly before I first moved to Cambridge, my girlfriend (now my wife) took me to the Sistine Chapel to show me the recently restored ceiling.

Figure: The ceiling of the Sistine Chapel.
When we got to Cambridge, we both attended Patrick Boyde’s talks on chapel. He focussed on both the structure of the chapel ceiling, describing the impression of height it was intended to give, as well as the significance and positioning of each of the panels and the meaning of the individual figures.
The Creation of Adam

Figure: Photo of Detail of Creation of Man from the Sistine chapel ceiling.
One of the most famous panels is central in the ceiling, it’s the creation of man. Here, God in the guise of a pink-robed bearded man reaches out to a languid Adam.
The representation of God in this form seems typical of the time, because elsewhere in the Vatican Museums there are similar representations.

Figure: Photo detail of God.
Photo from https://commons.wikimedia.org/wiki/File:Michelangelo,_Creation_of_Adam_04.jpg.
My colleague Beth Singler has written about how often this image of creation appears when we talk about AI (Singler, 2020).
See Lawrence (2024) Michelangelo, The Creation of Adam p. 7-9, 31, 91, 105–106, 121, 153, 206, 216, 350.
The way we represent this “other intelligence” in the figure of a Zeus-like bearded mind demonstrates our tendency to embody intelligences in forms that are familiar to us.
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
A Six Word Novel

Figure: Consider the six-word novel, apocryphally credited to Ernest Hemingway, “For sale: baby shoes, never worn”. To understand what that means to a human, you need a great deal of additional context. Context that is not directly accessible to a machine that has not got both the evolved and contextual understanding of our own condition to realize both the implication of the advert and what that implication means emotionally to the previous owner.
See Lawrence (2024) baby shoes p. 368.
But this is a very different kind of intelligence than ours. A computer cannot understand the depth of the Ernest Hemingway’s apocryphal six-word novel: “For Sale, Baby Shoes, Never worn”, because it isn’t equipped with that ability to model the complexity of humanity that underlies that statement.
Royal Society Report

Figure: The Royal Society report on Machine Learning was released on 25th April 2017
A useful reference for state of the art in machine learning is the UK Royal Society Report, Machine Learning: Power and Promise of Computers that Learn by Example.
Public Research

Figure: The Royal Society comissioned public research from Mori as part of the machine learning review.
As is often the cas when members of the public are well convened, they offered sensible opinions about the utility and challenges of machine learning methods.

Figure: One of the questions focussed on machine learning applications.
A range of different scenaios were captured by this qualitative work.

Figure: The public were broadly supportive of a range of application areas.

Figure: But they failed to see the point in AI’s that could produce poetry.
The one scenario where the public were unable to perceive any advantage in machine learning was an example from art, the creation of poetry. This was felt to be a fundamentally human activity that machines could only emulate at best.
Mercutio
It’s ironic that despite the public focus on transport, health, cities, crime and their confusion as to why we might want AI to do art, one area where significant progress has been made is on AIs that can create literature.
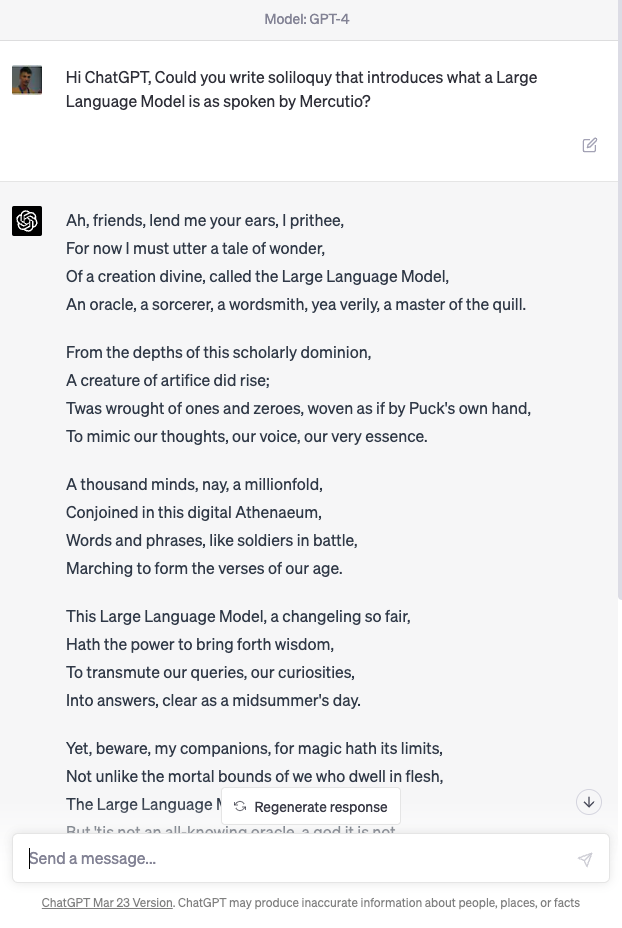
Figure: Despite the public’s desire to see challenges in health, finance, transport, crime solved by machine learning and their skepticism around poetry, one of the problems we have solved seems to be poetry.
User: Hi ChatGPT, Could you write soliloquy that introduces what a Large Language Model is as spoken by Mercutio?
Machine: Ah, friends, lend me your ears, I prithee, For now I must utter a tale of wonder, Of a creation divine, called the Large Language Model, An oracle, a sorcerer, a wordsmith, yea verily, a master of the quill.
From the depths of this scholarly dominion, A creature of artifice did rise; Twas wrought of ones and zeroes, woven as if by Puck’s own hand, To mimic our thoughts, our voice, our very essence.
A thousand minds, nay, a millionfold, Conjoined in this digital Athenaeum, Words and phrases, like soldiers in battle, Marching to form the verses of our age.
This Large Language Model, a changeling so fair, Hath the power to bring forth wisdom, To transmute our queries, our curiosities, Into answers, clear as a midsummer’s day.
Yet, beware, my companions, for magic hath its limits, Not unlike the mortal bounds of we who dwell in flesh, The Large Language Model hath its strengths, But ’tis not an all-knowing oracle, a god it is not.
As Mercutio, your humble servant, doth stand before thee, I marvel at the art and science that hath brought forth this wondrous creation, This Large Language Model, a testament to man’s yearning, To comprehend the world and make meaning of the great tapestry of existence.
In faith, dear friends, let us embrace the magic and beauty of this digital bard, And mayhaps, by its grace, we shall glean some wisdom, As we wander together, hand in hand, Through this boundless realm of knowledge and wonder.
ChatGPT transcript, 14th April 2023.
Revolution
Arguably the information revolution we are experiencing is unprecedented in history. But changes in the way we share information have a long history. Over 5,000 years ago in the city of Uruk, on the banks of the Euphrates, communities which relied on the water to irrigate their corps developed an approach to recording transactions in clay. Eventually the system of recording system became sophisticated enough that their oral histories could be recorded in the form of the first epic: Gilgamesh.
See Lawrence (2024) cuneiform p. 337, 360, 390.

Figure: Chicago Stone, side 2, recording sale of a number of fields, probably from Isin, Early Dynastic Period, c. 2600 BC, black basalt
It was initially developed for people as a record of who owed what to whom, expanding individuals’ capacity to remember. But over a five hundred year period writing evolved to become a tool for literature as well. More pithily put, writing was invented by accountants not poets (see e.g. this piece by Tim Harford).
In some respects today’s revolution is different, because it involves also the creation of stories as well as their curation. But in some fundamental ways we can see what we have produced as another tool for us in the information revolution.
The Future of Professions

Figure: The Future of Professions (Susskind and Susskind, 2015) is a 2015 book focussed on how the next wave of technology revolution is going to effect the professions.
Richard and Daniel Susskind’s 2015 book foresaw that the next wave of automation, artificial intelligence, would have an effect on professional work, information work. And that looks likely to be the case. But professionals are typically well educated and can adapt to changes in their circumstances. For example stocks have already been revolutioniswd by algorithmic trading, businesses and individuals have adapted to those changes.
Intellectual Debt
Figure: Jonathan Zittrain’s term to describe the challenges of explanation that come with AI is Intellectual Debt.
In the context of machine learning and complex systems, Jonathan Zittrain has coined the term “Intellectual Debt” to describe the challenge of understanding what you’ve created. In the ML@CL group we’ve been foucssing on developing the notion of a data-oriented architecture to deal with intellectual debt (Cabrera et al., 2023).
Zittrain points out the challenge around the lack of interpretability of individual ML models as the origin of intellectual debt. In machine learning I refer to work in this area as fairness, interpretability and transparency or FIT models. To an extent I agree with Zittrain, but if we understand the context and purpose of the decision making, I believe this is readily put right by the correct monitoring and retraining regime around the model. A concept I refer to as “progression testing”. Indeed, the best teams do this at the moment, and their failure to do it feels more of a matter of technical debt rather than intellectual, because arguably it is a maintenance task rather than an explanation task. After all, we have good statistical tools for interpreting individual models and decisions when we have the context. We can linearise around the operating point, we can perform counterfactual tests on the model. We can build empirical validation sets that explore fairness or accuracy of the model.
See Lawrence (2024) intellectual debt p. 84, 85, 349, 365.
Technical Debt
In computer systems the concept of technical debt has been surfaced by authors including Sculley et al. (2015). It is an important concept, that I think is somewhat hidden from the academic community, because it is a phenomenon that occurs when a computer software system is deployed.
Separation of Concerns
To construct such complex systems an approach known as “separation of concerns” has been developed. The idea is that you architect your system, which consists of a large-scale complex task, into a set of simpler tasks. Each of these tasks is separately implemented. This is known as the decomposition of the task.
This is where Jonathan Zittrain’s beautifully named term “intellectual debt” rises to the fore. Separation of concerns enables the construction of a complex system. But who is concerned with the overall system?
Technical debt is the inability to maintain your complex software system.
Intellectual debt is the inability to explain your software system.
It is right there in our approach to software engineering. “Separation of concerns” means no one is concerned about the overall system itself.
See Lawrence (2024) separation of concerns p. 84-85, 103, 109, 199, 284, 371.
See Lawrence (2024) intellectual debt p. 84-85, 349, 365, 376.
The Sorcerer’s Apprentice
See this blog blog post on The Open Society and its AI.

Figure: A young sorcerer learns his masters spells, and deploys them to perform his chores, but can’t control the result.
In Goethe’s poem The Sorcerer’s Apprentice, a young sorcerer learns one of their master’s spells and deploys it to assist in his chores. Unfortunately, he cannot control it. The poem was popularised by Paul Dukas’s musical composition, in 1940 Disney used the composition in the film Fantasia. Mickey Mouse plays the role of the hapless apprentice who deploys the spell but cannot control the results.
When it comes to our software systems, the same thing is happening. The Harvard Law professor, Jonathan Zittrain calls the phenomenon intellectual debt. In intellectual debt, like the sorcerer’s apprentice, a software system is created but it cannot be explained or controlled by its creator. The phenomenon comes from the difficulty of building and maintaining large software systems: the complexity of the whole is too much for any individual to understand, so it is decomposed into parts. Each part is constructed by a smaller team. The approach is known as separation of concerns, but it has the unfortunate side effect that no individual understands how the whole system works. When this goes wrong, the effects can be devastating. We saw this in the recent Horizon scandal, where neither the Post Office or Fujitsu were able to control the accounting system they had deployed, and we saw it when Facebook’s systems were manipulated to spread misinformation in the 2016 US election.
In 2019 Mark Zuckerberg wrote an op-ed in the Washington Post calling for regulation of social media. He was repeating the realisation of Goethe’s apprentice, he had released a technology he couldn’t control. In Goethe’s poem, the master returns, “Besen, besen! Seid’s gewesen” he calls, and order is restored, but back in the real world the role of the master is played by Popper’s open society. Unfortunately, those institutions have been undermined by the very spell that these modern apprentices have cast. The book, the letter, the ledger, each of these has been supplanted in our modern information infrastructure by the computer. The modern scribes are software engineers, and their guilds are the big tech companies. Facebook’s motto was to “move fast and break things”. Their software engineers have done precisely that and the apprentice has robbed the master of his powers. This is a desperate situation, and it’s getting worse. The latest to reprise the apprentice’s role are Sam Altman and OpenAI who dream of “general intelligence” solutions to societal problems which OpenAI will develop, deploy, and control. Popper worried about the threat of totalitarianism to our open societies, today’s threat is a form of information totalitarianism which emerges from the way these companies undermine our institutions.
So, what to do? If we value the open society, we must expose these modern apprentices to scrutiny. Open development processes are critical here, Fujitsu would never have got away with their claims of system robustness for Horizon if the software they were using was open source. We also need to re-empower the professions, equipping them with the resources they need to have a critical understanding of these technologies. That involves redesigning the interface between these systems and the humans that empowers civil administrators to query how they are functioning. This is a mammoth task. But recent technological developments, such as code generation from large language models, offer a route to delivery.
The open society is characterised by institutions that collaborate with each otherin the pragmatic pursuit of solutions to social problems. The large tech companies that have thrived because of the open society are now putting that ecosystem in peril. For the open society to survive it needs to embrace open development practices that enable Popper’s piecemeal social engineers to come back together and chant “Besen, besen! Seid’s gewesen.” Before it is too late for the master to step in and deal with the mess the apprentice has made.
See Lawrence (2024) sorcerer’s apprentice p. 371-374.
The Open Society and its Enemies

Figure: The Open Society and Its Enemies by Karl Popper views liberal democracies as a collection of “piecemeal social engineers” who strive towards better outcomes.
Popper opened the preface to his book (Popper-open45?) with the following words:
If in this book harsh words are spoken about some of the greatest among the intellectual leaders of mankind, my motive is not, I hope, to belittle them. It springs rather from my conviction that, if our civilization is to survive, we must break with the habit of deference to great men. Great men may make great mistakes; and as the book tries to show, some of the greatest leaders of the past supported the perennial attack on freedom and reason.
He had written the book against the background of the second world war, his decision to write it taken on the day the Nazis invaded Austria in March 1938. His book is a reaction to totalitarianism.
For Popper, the ideas of “great men” become totalitarian when imposed on society. He advocates for direct liberal democracy as the only form of government that can allow for institutional change without bloodshed. The open society is one characterized by institutions and individuals that can engage in the practical pursuit of solutions to social and political problems. The institutions are also underpinned by individuals: lawyers, accountants, civil administrators and many more. To Popper it is these “piecemeal social engineers” who offer pragmatic solutions to our society’s political and social challenges.
See Lawrence (2024) Popper, Karl The Open Society and its Enemies p. 371–374.
Coin Pusher
Disruption of society is like a coin pusher, it’s those who are already on the edge who are most likely to be effected by disruption.

Figure: A coin pusher is a game where coins are dropped into th etop of the machine, and they disrupt those on the existing steps. With any coin drop, many coins move, but it is those on the edge, who are often only indirectly effected, but also most traumatically effected by the change.
One danger of the current hype around ChatGPT is that we are overly focussing on the fact that it seems to have significant effect on professional jobs, people are naturally asking the question “what does it do for my role?”. No doubt, there will be disruption, but the coin pusher hypothesis suggests that that disruption will likely involve movement on the same step. However it is those on the edge already, who are often not working directly in the information economy, who often have less of a voice in the policy conversation who are likely to be most disrupted.
The Horizon Scandal
In the UK we saw these effects play out in the Horizon scandal: the accounting system of the national postal service was computerized by Fujitsu and first installed in 1999, but neither the Post Office nor Fujitsu were able to control the system they had deployed. When it went wrong individual sub postmasters were blamed for the systems’ errors. Over the next two decades they were prosecuted and jailed leaving lives ruined in the wake of the machine’s mistakes.
{kind=link}
See Lawrence (2024) Horizon scandal p. 371.
Data Oriented Architectures
In a streaming architecture we shift from management of services, to management of data streams. Instead of worrying about availability of the services we shift to worrying about the quality of the data those services are producing.
Historically we’ve been software first, this is a necessary but insufficient condition for data first. We need to move from software-as-a-service to data-as-a-service, from service oriented architectures to data oriented architectures.
Data Oriented Principles
Figure: For an overview of data oriented principles see Cabrera et al. (2023).
Our work comes from surveying machine learning case studies (Paleyes-challenges22?) identifying the challenges and then surveying papers that focus on deployment (Cabrera et al., 2023) and identifying the principles they use.
The philosphy of DOA is also possible with more standard data infrastructures, such as SQL data bases, but more work has to be put into place to ensure that book-keeping around data provenance and origin is stored, as well as approaches for snapshotting the data ecosystem. Our studies (Paleyes-flow22?) have made a lot of use of flow based programming (Paleyes-flow22?).
How LLMs are Different
So far our description has provided an understanding of how digital computers present problems for our understanding. So what do LLMs do that’s different?
The MONIAC
The MONIAC was an analogue computer designed to simulate the UK economy. Analogue comptuers work through analogy, the analogy in the MONIAC is that both money and water flow. The MONIAC exploits this through a system of tanks, pipes, valves and floats that represent the flow of money through the UK economy. Water flowed from the treasury tank at the top of the model to other tanks representing government spending, such as health and education. The machine was initially designed for teaching support but was also found to be a useful economic simulator. Several were built and today you can see the original at Leeds Business School, there is also one in the London Science Museum and one in the Unisversity of Cambridge’s economics faculty.

Figure: Bill Phillips and his MONIAC (completed in 1949). The machine is an analogue computer designed to simulate the workings of the UK economy.
See Lawrence (2024) MONIAC p. 232-233, 266, 343.
HAM
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Figure: The HAM now sits between us and the traditional digital computer.
Networked Interactions
Our modern society intertwines the machine with human interactions. The key question is who has control over these interfaces between humans and machines.
Figure: Humans and computers interacting should be a major focus of our research and engineering efforts.
So the real challenge that we face for society is understanding which systemic interventions will encourage the right interactions between the humans and the machine at all of these interfaces.
Figure:
Figure: Bandwidth vs Complexity.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com