AI and Data Science
Abstract
Waves of automation have driven human advance, and each wave requires humans to The promise of AI is to launch new systems of automated intellectual endeavour that will be the first systems to adapt to us. In reality, the systems we have will not achieve this, and it is the biological sciences that teach us this lesson most starkly. In this talk I will review some of the successes and challenges of AI and its deployment and propose practical visions for the future based on approaches that have worked in the past.
What is Machine Learning?
What is machine learning? At its most basic level machine learning is a combination of
\[\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction}\]
where data is our observations. They can be actively or passively acquired (meta-data). The model contains our assumptions, based on previous experience. That experience can be other data, it can come from transfer learning, or it can merely be our beliefs about the regularities of the universe. In humans our models include our inductive biases. The prediction is an action to be taken or a categorization or a quality score. The reason that machine learning has become a mainstay of artificial intelligence is the importance of predictions in artificial intelligence. The data and the model are combined through computation.
In practice we normally perform machine learning using two functions. To combine data with a model we typically make use of:
a prediction function it is used to make the predictions. It includes our beliefs about the regularities of the universe, our assumptions about how the world works, e.g., smoothness, spatial similarities, temporal similarities.
an objective function it defines the ‘cost’ of misprediction. Typically, it includes knowledge about the world’s generating processes (probabilistic objectives) or the costs we pay for mispredictions (empirical risk minimization).
The combination of data and model through the prediction function and the objective function leads to a learning algorithm. The class of prediction functions and objective functions we can make use of is restricted by the algorithms they lead to. If the prediction function or the objective function are too complex, then it can be difficult to find an appropriate learning algorithm. Much of the academic field of machine learning is the quest for new learning algorithms that allow us to bring different types of models and data together.
A useful reference for state of the art in machine learning is the UK Royal Society Report, Machine Learning: Power and Promise of Computers that Learn by Example.
You can also check my post blog post on What is Machine Learning?.
Artificial Intelligence and Data Science
Machine learning technologies have been the driver of two related, but distinct disciplines. The first is data science. Data science is an emerging field that arises from the fact that we now collect so much data by happenstance, rather than by experimental design. Classical statistics is the science of drawing conclusions from data, and to do so statistical experiments are carefully designed. In the modern era we collect so much data that there’s a desire to draw inferences directly from the data.
As well as machine learning, the field of data science draws from statistics, cloud computing, data storage (e.g. streaming data), visualization and data mining.
In contrast, artificial intelligence technologies typically focus on emulating some form of human behaviour, such as understanding an image, or some speech, or translating text from one form to another. The recent advances in artificial intelligence have come from machine learning providing the automation. But in contrast to data science, in artificial intelligence the data is normally collected with the specific task in mind. In this sense it has strong relations to classical statistics.
Classically artificial intelligence worried more about logic and planning and focused less on data driven decision making. Modern machine learning owes more to the field of Cybernetics (Wiener, 1948) than artificial intelligence. Related fields include robotics, speech recognition, language understanding and computer vision.
There are strong overlaps between the fields, the wide availability of data by happenstance makes it easier to collect data for designing AI systems. These relations are coming through wide availability of sensing technologies that are interconnected by cellular networks, WiFi and the internet. This phenomenon is sometimes known as the Internet of Things, but this feels like a dangerous misnomer. We must never forget that we are interconnecting people, not things.
Supply Chain


Figure: Packhorse Bridge under Burbage Edge. This packhorse route climbs steeply out of Hathersage and heads towards Sheffield. Packhorses were the main route for transporting goods across the Peak District. The high cost of transport is one driver of the ‘smith’ model, where there is a local skilled person responsible for assembling or creating goods (e.g. a blacksmith).
On Sunday mornings in Sheffield, I often used to run across Packhorse Bridge in Burbage valley. The bridge is part of an ancient network of trails crossing the Pennines that, before Turnpike roads arrived in the 18th century, was the main way in which goods were moved. Given that the moors around Sheffield were home to sand quarries, tin mines, lead mines and the villages in the Derwent valley were known for nail and pin manufacture, this wasn’t simply movement of agricultural goods, but it was the infrastructure for industrial transport.
The profession of leading the horses was known as a Jagger and leading out of the village of Hathersage is Jagger’s Lane, a trail that headed underneath Stanage Edge and into Sheffield.
The movement of goods from regions of supply to areas of demand is fundamental to our society. The physical infrastructure of supply chain has evolved a great deal over the last 300 years.
Cromford

Figure: Richard Arkwright is regarded of the founder of the modern factory system. Factories exploit distribution networks to centralize production of goods. Arkwright located his factory in Cromford due to proximity to Nottingham Weavers (his market) and availability of water power from the tributaries of the Derwent river. When he first arrived there was almost no transportation network. Over the following 200 years The Cromford Canal (1790s), a Turnpike (now the A6, 1816-18) and the High Peak Railway (now closed, 1820s) were all constructed to improve transportation access as the factory blossomed.
Richard Arkwright is known as the father of the modern factory system. In 1771 he set up a Mill for spinning cotton yarn in the village of Cromford, in the Derwent Valley. The Derwent valley is relatively inaccessible. Raw cotton arrived in Liverpool from the US and India. It needed to be transported on packhorse across the bridleways of the Pennines. But Cromford was a good location due to proximity to Nottingham, where weavers where consuming the finished thread, and the availability of water power from small tributaries of the Derwent river for Arkwright’s water frames which automated the production of yarn from raw cotton.
By 1794 the Cromford Canal was opened to bring coal in to Cromford and give better transport to Nottingham. The construction of the canals was driven by the need to improve the transport infrastructure, facilitating the movement of goods across the UK. Canals, roads and railways were initially constructed by the economic need for moving goods. To improve supply chain.
The A6 now does pass through Cromford, but at the time he moved there there was merely a track. The High Peak Railway was opened in 1832, it is now converted to the High Peak Trail, but it remains the highest railway built in Britain.
Cooper (1991)
Containerization

Figure: The container is one of the major drivers of globalization, and arguably the largest agent of social change in the last 100 years. It reduces the cost of transportation, significantly changing the appropriate topology of distribution networks. The container makes it possible to ship goods halfway around the world for cheaper than it costs to process those goods, leading to an extended distribution topology.
Containerization has had a dramatic effect on global economics, placing many people in the developing world at the end of the supply chain.

|

|
Figure: Wild Alaskan Cod, being solid in the Pacific Northwest, that is a product of China. It is cheaper to ship the deep frozen fish thousands of kilometers for processing than to process locally.
For example, you can buy Wild Alaskan Cod fished from Alaska, processed in China, sold in North America. This is driven by the low cost of transport for frozen cod vs the higher relative cost of cod processing in the US versus China. Similarly, Scottish prawns are also processed in China for sale in the UK.
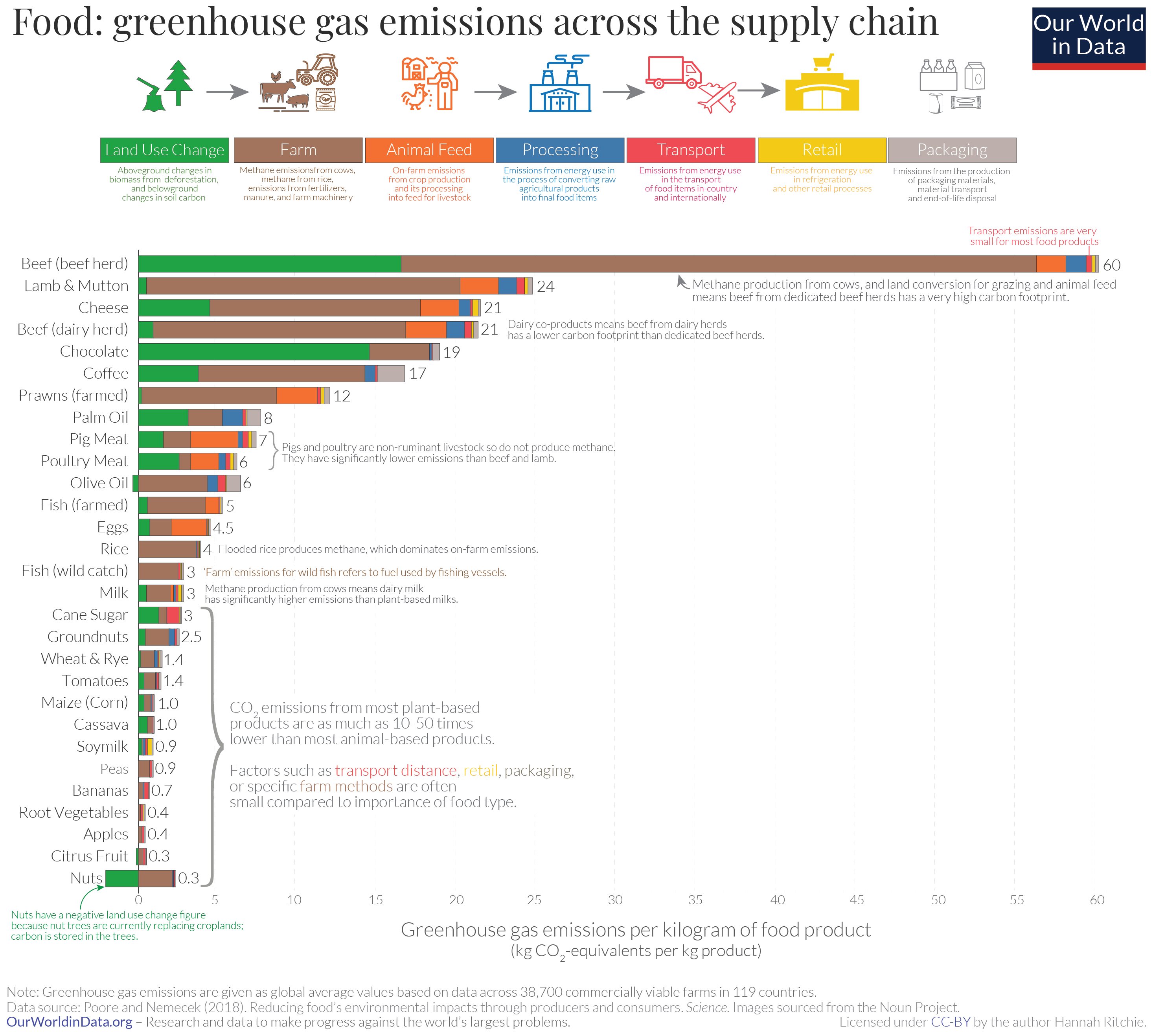
Figure: The transport cost of most foods is a very small portion of the total cost. The exception is if foods are air freighted. Source: https://ourworldindata.org/food-choice-vs-eating-local by Hannah Ritche CC-BY
This effect on cost of transport vs cost of processing is the main driver of the topology of the modern supply chain and the associated effect of globalization. If transport is much cheaper than processing, then processing will tend to agglomerate in places where processing costs can be minimized.
Large scale global economic change has principally been driven by changes in the technology that drives supply chain.
Supply chain is a large-scale automated decision making network. Our aim is to make decisions not only based on our models of customer behavior (as observed through data), but also by accounting for the structure of our fulfilment center, and delivery network.
Many of the most important questions in supply chain take the form of counterfactuals. E.g. “What would happen if we opened a manufacturing facility in Cambridge?” A counter factual is a question that implies a mechanistic understanding of a system. It goes beyond simple smoothness assumptions or translation invariants. It requires a physical, or mechanistic understanding of the supply chain network. For this reason, the type of models we deploy in supply chain often involve simulations or more mechanistic understanding of the network.
In supply chain Machine Learning alone is not enough, we need to bridge between models that contain real mechanisms and models that are entirely data driven.
This is challenging, because as we introduce more mechanism to the models we use, it becomes harder to develop efficient algorithms to match those models to data.
Deploying Artificial Intelligence
With the wide availability of new techniques, we are currently creating Artificial Intelligence through combination of machine learning algorithms to form machine learning systems.
This effect is amplified through the growth in sensorics, in particular the movement of cloud computing towards the customer. The barrier between cloud and device is blurring. This phenomenon is sometimes known as fog computing, or computing on the edge.
This presents major new challenges for machine learning systems design. We would like an internet of intelligence but currently our AI systems are fragile. A classical systems approach to design does not handle evolving environments well.
Data Science Africa
Figure: Data Science Africa https://datascienceafrica.org is a ground up initiative for capacity building around data science, machine learning and artificial intelligence on the African continent.
Figure: Data Science Africa meetings held up to October 2021.
Data Science Africa is a bottom up initiative for capacity building in data science, machine learning and artificial intelligence on the African continent.
As of June 2025 there have been thirteen workshops and schools, located in seven different countries: Nyeri, Kenya (three times); Kampala, Uganda; Arusha, Tanzania (twice); Abuja, Nigeria; Addis Ababa, Ethiopia; Accra, Ghana; Kampala, Uganda and Kimberley, South Africa (virtual), Kigali, Rwanda and Ibadan, Nigeria.
DSA Ibadan, Nigeria
Figure: Organiser’s video from Data Science Africa held in Ibadan, Nigeria from 2nd to 6th June 2025
The main notion is end-to-end data science. For example, going from data collection in the farmer’s field to decision making in the Ministry of Agriculture. Or going from malaria disease counts in health centers to medicine distribution.
The philosophy is laid out in (Lawrence, 2015). The key idea is that the modern information infrastructure presents new solutions to old problems. Modes of development change because less capital investment is required to take advantage of this infrastructure. The philosophy is that local capacity building is the right way to leverage these challenges in addressing data science problems in the African context.
Data Science Africa is now a non-govermental organization registered in Kenya. The organising board of the meeting is entirely made up of scientists and academics based on the African continent.
Figure: The lack of existing physical infrastructure on the African continent makes it a particularly interesting environment for deploying solutions based on the information infrastructure. The idea is explored more in this Guardian op-ed on Guardian article on How African can benefit from the data revolution.
Guardian article on Data Science Africa
Example: Prediction of Malaria Incidence in Uganda
As an example of using Gaussian process models within the full pipeline from data to decsion, we’ll consider the prediction of Malaria incidence in Uganda. For the purposes of this study malaria reports come in two forms, HMIS reports from health centres and Sentinel data, which is curated by the WHO. There are limited sentinel sites and many HMIS sites.
The work is from Ricardo Andrade Pacheco’s PhD thesis, completed in collaboration with John Quinn and Martin Mubangizi (Andrade-Pacheco et al., 2014; Mubangizi et al., 2014). John and Martin were initally from the AI-DEV group from the University of Makerere in Kampala and more latterly they were based at UN Global Pulse in Kampala. You can see the work summarized on the UN Global Pulse disease outbreaks project site here.
Malaria data is spatial data. Uganda is split into districts, and health reports can be found for each district. This suggests that models such as conditional random fields could be used for spatial modelling, but there are two complexities with this. First of all, occasionally districts split into two. Secondly, sentinel sites are a specific location within a district, such as Nagongera which is a sentinel site based in the Tororo district.
The common standard for collecting health data on the African continent is from the Health management information systems (HMIS). However, this data suffers from missing values (Gething et al., 2006) and diagnosis of diseases like typhoid and malaria may be confounded.
Figure: The Tororo district, where the sentinel site, Nagongera, is located.
World Health Organization Sentinel Surveillance systems are set up “when high-quality data are needed about a particular disease that cannot be obtained through a passive system”. Several sentinel sites give accurate assessment of malaria disease levels in Uganda, including a site in Nagongera.
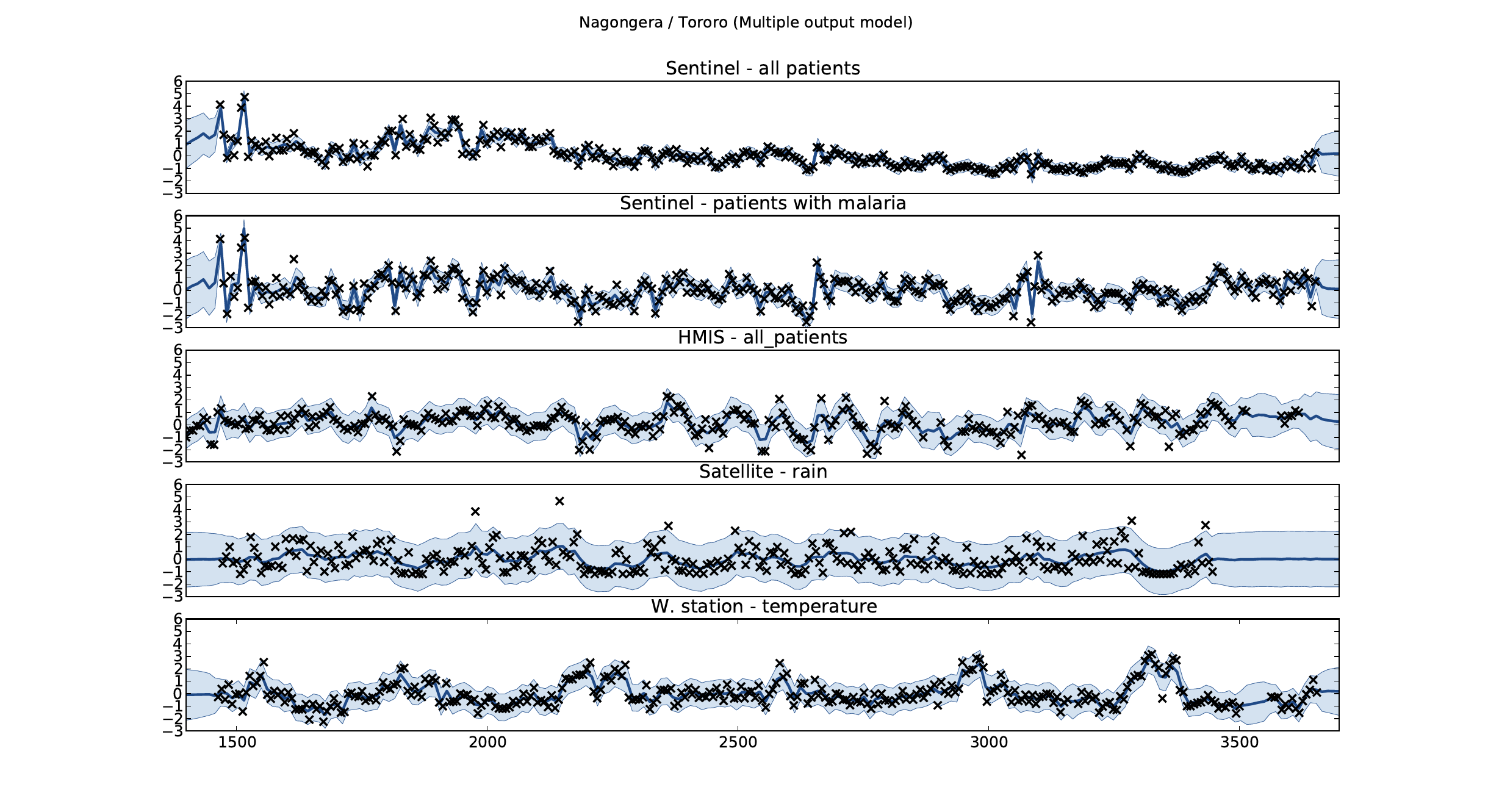
Figure: Sentinel and HMIS data along with rainfall and temperature for the Nagongera sentinel station in the Tororo district.
In collaboration with the AI Research Group at Makerere we chose to investigate whether Gaussian process models could be used to assimilate information from these two different sources of disease informaton. Further, we were interested in whether local information on rainfall and temperature could be used to improve malaria estimates.
The aim of the project was to use WHO Sentinel sites, alongside rainfall and temperature, to improve predictions from HMIS data of levels of malaria.
Figure: The Mubende District.
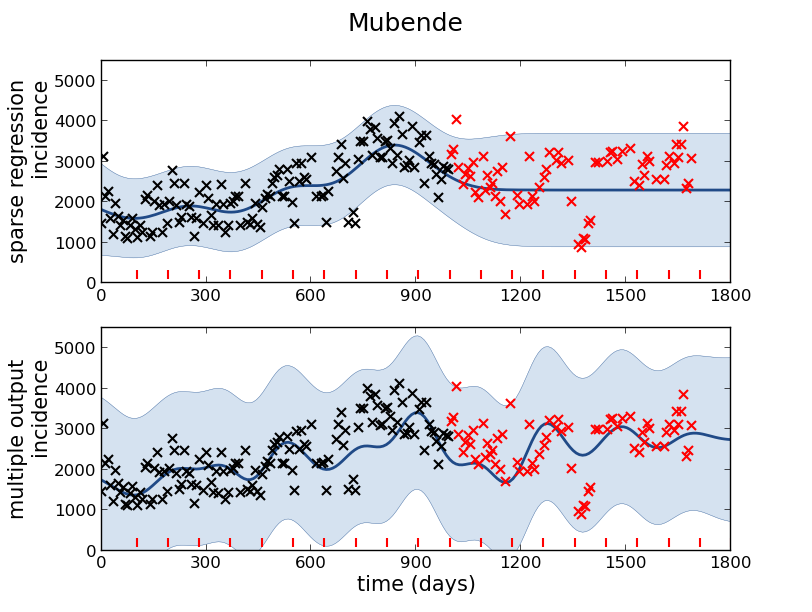
Figure: Prediction of malaria incidence in Mubende.

Figure: The project arose out of the Gaussian process summer school held at Makerere in Kampala in 2013. The school led, in turn, to the Data Science Africa initiative.
Early Warning Systems
Figure: The Kabarole district in Uganda.
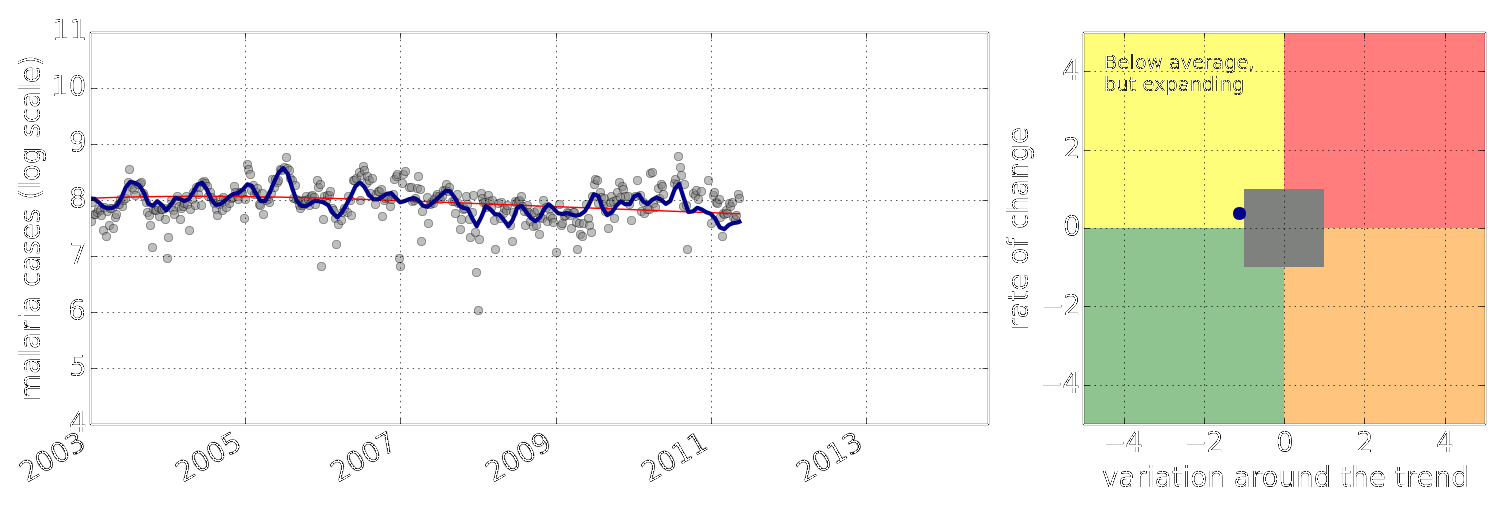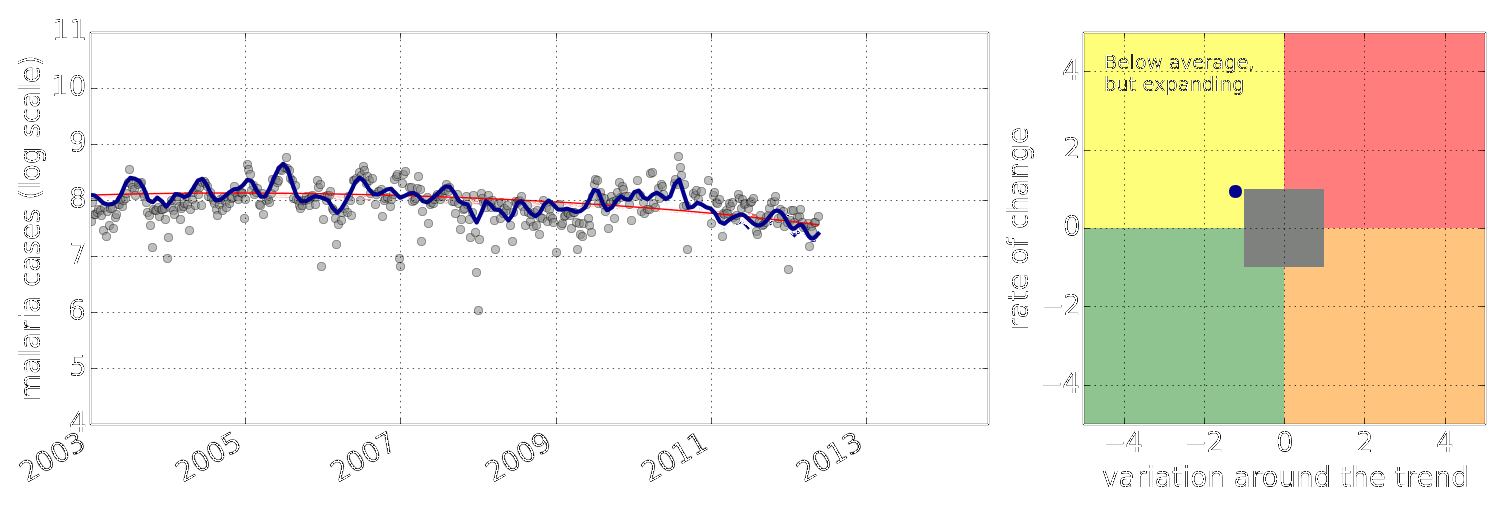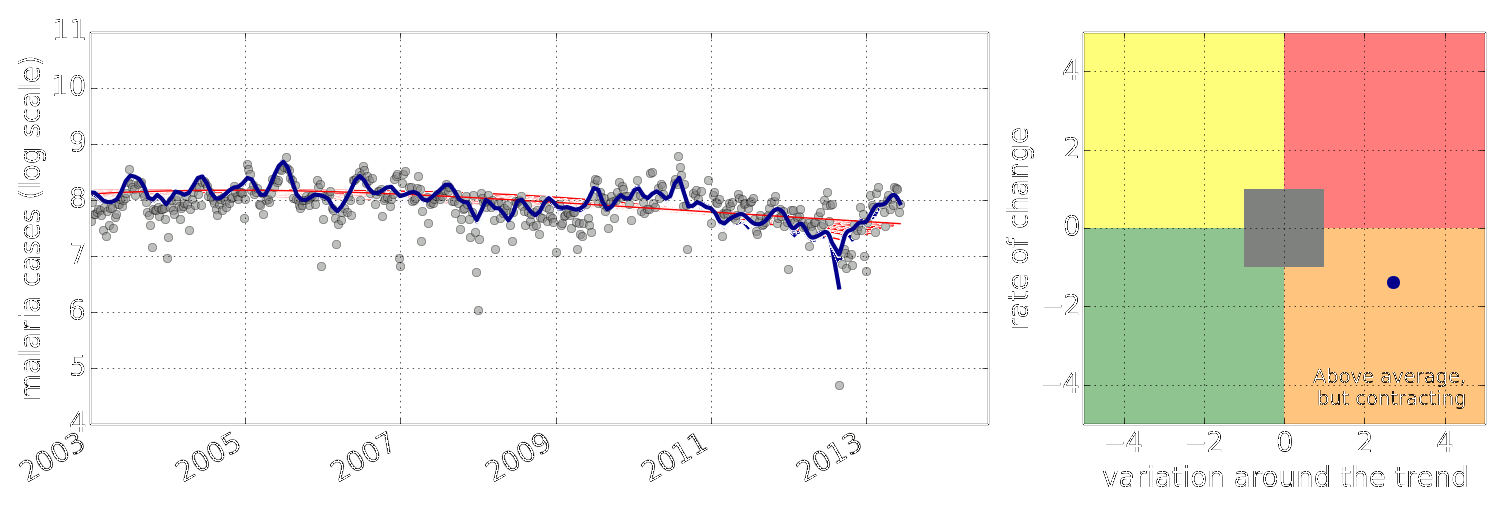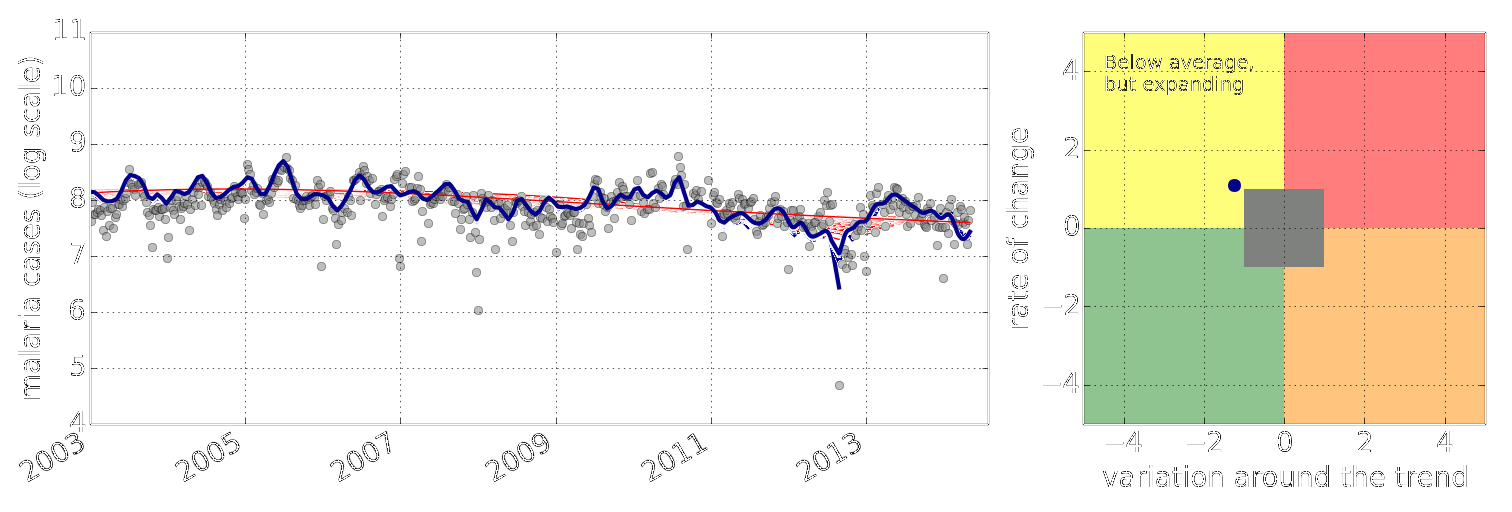
Figure: Estimate of the current disease situation in the Kabarole district over time. Estimate is constructed with a Gaussian process with an additive covariance funciton.
Health monitoring system for the Kabarole district. Here we have fitted the reports with a Gaussian process with an additive covariance function. It has two components, one is a long time scale component (in red above) the other is a short time scale component (in blue).
Monitoring proceeds by considering two aspects of the curve. Is the blue line (the short term report signal) above the red (which represents the long term trend? If so we have higher than expected reports. If this is the case and the gradient is still positive (i.e. reports are going up) we encode this with a red color. If it is the case and the gradient of the blue line is negative (i.e. reports are going down) we encode this with an amber color. Conversely, if the blue line is below the red and decreasing, we color green. On the other hand if it is below red but increasing, we color yellow.
This gives us an early warning system for disease. Red is a bad situation getting worse, amber is bad, but improving. Green is good and getting better and yellow good but degrading.
Finally, there is a gray region which represents when the scale of the effect is small.
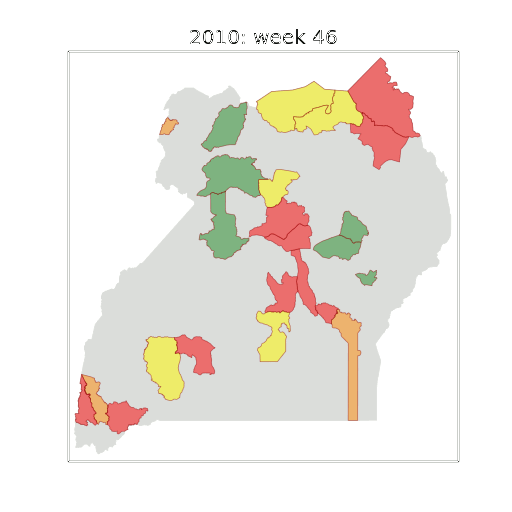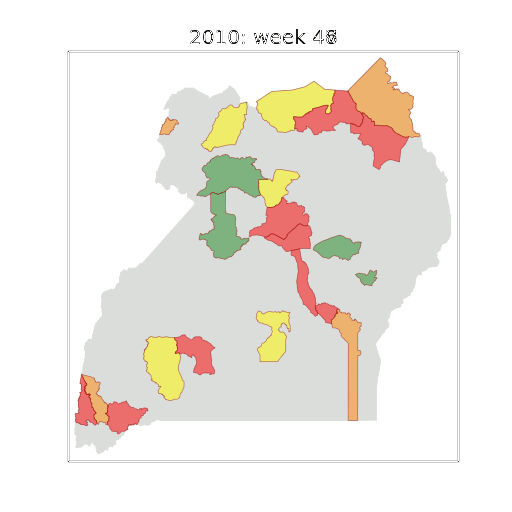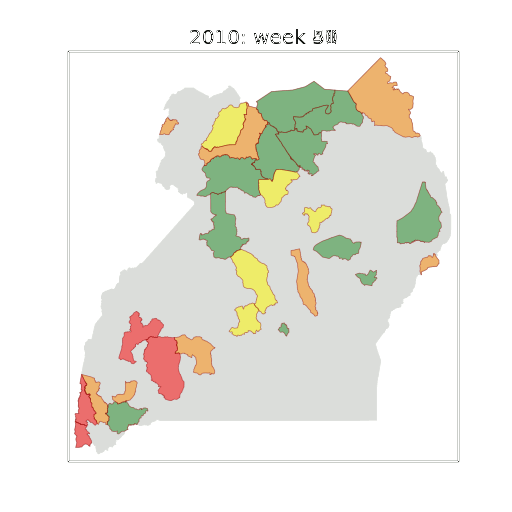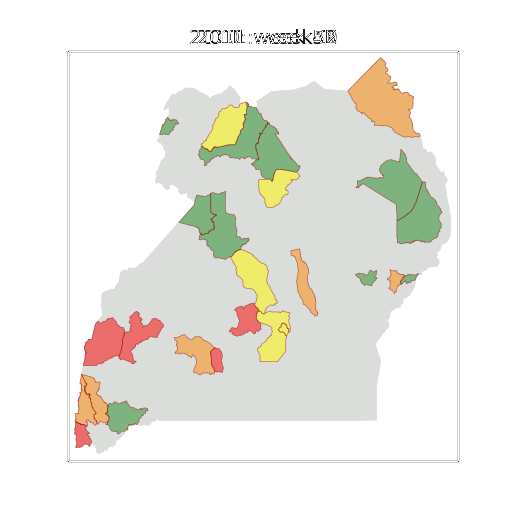
Figure: The map of Ugandan districts with an overview of the Malaria situation in each district.
These colors can now be observed directly on a spatial map of the districts to give an immediate impression of the current status of the disease across the country.
Conclusion
Separation between machine learning and AI
Real world challenges such as matching supply to demand
Example of predicting disease via Gaussian processes
Thanks!
For more information on these subjects and more you might want to check the following resources.
- company: Trent AI
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com