AI and Data Trusts
Abstract
Resolutely complementary to top-down regulation, bottom-up data trusts aim to ‘give a voice’ to data subjects whose choices when it comes to data governance are often reduced to binary, ill-informed consent. While the rights granted by instruments like the GDPR can be used as tools in a bit to shape possible data-reliant futures - such as better use of natural resources, medical care etc., their exercise is both demanding and unlikely to be as impactful when leveraged individually. The power that stems from aggregated data should be returned to individuals through the legal mechanism of trusts.
Embodiment Factors
| bits/min | billions | 2,000 |
|
billion calculations/s |
~100 | a billion |
| embodiment | 20 minutes | 5 billion years |

Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, it is a matter of thousands of millions of years. See also “Living Together: Mind and Machine Intelligence” Lawrence (2017)
There is a fundamental limit placed on our intelligence based on our ability to communicate. Claude Shannon founded the field of information theory. The clever part of this theory is it allows us to separate our measurement of information from what the information pertains to.1
Shannon measured information in bits. One bit of information is the amount of information I pass to you when I give you the result of a coin toss. Shannon was also interested in the amount of information in the English language. He estimated that on average a word in the English language contains 12 bits of information.
Given typical speaking rates, that gives us an estimate of our ability to communicate of around 100 bits per second (Reed and Durlach, 1998). Computers on the other hand can communicate much more rapidly. Current wired network speeds are around a billion bits per second, ten million times faster.
When it comes to compute though, our best estimates indicate our computers are slower. A typical modern computer can process make around 100 billion floating point operations per second, each floating point operation involves a 64 bit number. So the computer is processing around 6,400 billion bits per second.
It’s difficult to get similar estimates for humans, but by some estimates the amount of compute we would require to simulate a human brain is equivalent to that in the UK’s fastest computer (Ananthanarayanan et al., 2009), the MET office machine in Exeter, which in 2018 ranks as the 11th fastest computer in the world. That machine simulates the world’s weather each morning, and then simulates the world’s climate in the afternoon. It is a 16 petaflop machine, processing around 1,000 trillion bits per second.
Evolved Relationship with Information
The high bandwidth of computers has resulted in a close relationship between the computer and data. Large amounts of information can flow between the two. The degree to which the computer is mediating our relationship with data means that we should consider it an intermediary.
Originaly our low bandwith relationship with data was affected by two characteristics. Firstly, our tendency to over-interpret driven by our need to extract as much knowledge from our low bandwidth information channel as possible. Secondly, by our improved understanding of the domain of mathematical statistics and how our cognitive biases can mislead us.
With this new set up there is a potential for assimilating far more information via the computer, but the computer can present this to us in various ways. If it’s motives are not aligned with ours then it can misrepresent the information. This needn’t be nefarious it can be simply as a result of the computer pursuing a different objective from us. For example, if the computer is aiming to maximize our interaction time that may be a different objective from ours which may be to summarize information in a representative manner in the shortest possible length of time.
For example, for me, it was a common experience to pick up my telephone with the intention of checking when my next appointment was, but to soon find myself distracted by another application on the phone, and end up reading something on the internet. By the time I’d finished reading, I would often have forgotten the reason I picked up my phone in the first place.
There are great benefits to be had from the huge amount of information we can unlock from this evolved relationship between us and data. In biology, large scale data sharing has been driven by a revolution in genomic, transcriptomic and epigenomic measurement. The improved inferences that can be drawn through summarizing data by computer have fundamentally changed the nature of biological science, now this phenomenon is also infuencing us in our daily lives as data measured by happenstance is increasingly used to characterize us.
Better mediation of this flow actually requires a better understanding of human-computer interaction. This in turn involves understanding our own intelligence better, what its cognitive biases are and how these might mislead us.
For further thoughts see Guardian article on marketing in the internet era from 2015.
You can also check my blog post on System Zero. also from 2015.
New Flow of Information
Classically the field of statistics focussed on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarise what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data, but must also deal with the possibility that the machine has either inadvertently or malisciously misrepresented the underlying data.
Data Rights
Data is not property, at least not in the modern sense of the word. But if we look back over time, we see different notions of property. In particular, associated with different resources. For example, common land is a particular type of property, which may or may not be explicitly owned, but members of a community have a particular set of rights to.
In Sheffield, where I used to live, work, run and cycle. The moorland was historically common land until the enclosures acts applied in the 1860s. Until that time, local people had the right to, for example, collect sand from the moorland for use in building their houses. After enclosure, the crime of ‘sand poaching’ evolved. On Houndkirk Moor, south West of Sheffield, after enclosure sand poachers went to collect sand at night for houses being built in the village of Dore.

Figure: Milestone on Houndkirk Road on Houndkirk Moor. Sand poaching took place near here after the Moor was enclosed, also restricting access to this ancient route.
Computational Biologists at the forefront of data sharing, particularly public data sharing. Transcriptomic, genomic, epigenomic data is publicly available and have allowed people, like me, not even working directly with biologists to develop algorithms for interpreting and analyzing that data.
But as we transition from biological data to health data, that data starts to pertain to individuals. It falls under the domain of personal data.
These rights to a resource become particularly interesting when considering rivers. Sheffield itself emerged as the home of cutlers, knife makers. Their small mills were driven by water-power flowing from Houndkirk Moor to the center of town. There the lakes they built are called dams, today they line the streams of the city’s parkland, but 200 years ago they were a bustling industry of forges, grinders and polishers.
Important, regardless of who owned the river, different mills on the river had different rights to the water. If an upstream mill damns the entire flow, the downstream mill has to stop working in times of drought.
The rivers of Sheffield are streams, but as they flow down into the Don and eventually the Humber new rights to this water emerge. As well as power from the river, there is its use as a source of drinking water, for navigation and for irrigation.

Figure: Shepherd Wheel in Whitely Wood. In Sheffield the millpond itself is called a damn. This Wheel is now a working museum on Porter Brook, but it dates originally to the 1500s. It now sits in Bingham Park, but historically the river would have had several Wheels operating from the Porter Brook.

Figure: Interior of Shepherd Wheel showing spinning wheel in background, and stationary wheel in foreground with the wooden saddle of the grinder’s ‘horse.’
Many of these rights are in tension. Mills working on the river may pollute the stream. If the water is damned or used for irrigation, then it can be too low for navigation. There is complex interplay of demands on the river that creates tensions between different users.
The general data protection regulation is poorly named. It doesn’t protect data, what it does instead is give us some limited rights around access to and control of processing of our personal data.
Personal data has some of the characteristics of a river. My choice to share my data has effects on other individuals. If I share my genome, I am sharing information about my children’s genome. If I share my address book (e.g. with Facebook or Linkedin) I’m sharing information about what people know me. If I share a photo of myself with friends, I’m sharing the location of friends.
What the GDPR does is give us limited personal data rights. It outlines a limited right of deletion. It also allows us access to our personal data, which in turn confers a portability right.
A pure notion of ownership, in that I own a ball, or I own a car, is that I have the absolute right to share and restrict access to my property as I choose. Personal data rights are not absolute, but nevertheless they return some control to the individual.

Figure: The convention for the protection of individuals with regard to the processing of personal data was opened for signature on 28th January 1981. It was the first legally binding international instrument in the field of data protection.
GDPR Origins
There’s been much recent talk about GDPR, much of it implying that the recent incarnation is radically different from previous incarnations. While the most recent iteration began to be developed in 2012, but in reality, its origins are much older. It dates back to 1981, and 28th January is “Data Potection day”. The essence of the law didn’t change much in the previous iterations. The critical chance was the size of the fines that the EU stipulated may be imposed for infringements. Paul Nemitz, who was closely involved with the drafting, told me that they were initially inspired by competition law, which levies fines of 10% of international revenue. The final implementation is restricted to 5%, but it’s worth pointing out that Facebook’s fine (imposed in the US by the FTC) was $5 billion dollars. Or approximately 7% of their international revenue at the time.
So the big change is the seriousness with which regulators are taking breaches of the intent of GDPR. And indeed, this newfound will on behalf of the EU led to an amount of panic around companies who rushed to see if they were complying with this strengthened legislation.
But is it really the big bad regulator coming down hard on the poor scientist or company, just trying to do an honest day’s work? I would argue not. The stipulations of the GDPR include fairly simple things like the ‘right to an explanation’ for consequential decision-making. Or the right to deletion, to remove personal private data from a corporate data ecosystem.
Guardian article on Digital Oligarchies
While these are new stipulations, if you reverse the argument and ask a company “would it not be a good thing if you could explain why your automated decision making system is making decision X about customer Y” seems perfectly reasonable. Or “Would it not be a good thing if we knew that we were capable of deleting customer Z’s data from our systems, rather than being concerned that it may be lying unregistered in an S3 bucket somewhere?”
Phrased in this way, you can see that GDPR perhaps would better stand for “Good Data Practice Rules,” and should really be being adopted by the scientist, the company or whoever in an effort to respect the rights of the people they aim to serve.
So how do Data Trusts fit into this landscape? Well it’s appropriate that we’ve mentioned the commons, because a current challenge is how we manage data rights within our community. And the situation is rather akin to that which one might have found in a feudal village (in the days before Houndkirk Moor was enclosed).
How the GDPR May Help
Figure: The convention for the protection of individuals with regard to the processing of personal data was opened for signature on 28th January 1981. It was the first legally binding international instrument in the field of data protection.
Early reactions to the General Data Protection Regulation by companies seem to have been fairly wary, but if we view the principles outlined in the GDPR as good practice, rather than regulation, it feels like companies can only improve their internal data ecosystems by conforming to the GDPR. For this reason, I like to think of the initials as standing for “Good Data Practice Rules” rather than General Data Protection Regulation. In particular, the term “data protection” is a misnomer, and indeed the earliest data protection directive from the EU (from 1981) refers to the protection of individuals with regard to the automatic processing of personal data, which is a much better sense of the term.
If we think of the legislation as protecting individuals, and we note that it seeks, and instead of viewing it as regulation, we view it as “Wouldn’t it be good if …,” e.g. in respect to the “right to an explanation”, we might suggest: “Wouldn’t it be good if we could explain why our automated decision making system made a particular decison.” That seems like good practice for an organization’s automated decision making systems.
Similarly, with regard to data minimization principles. Retaining the minimum amount of personal data needed to drive decisions could well lead to better decision making as it causes us to become intentional about which data is used rather than the sloppier thinking that “more is better” encourages. Particularly when we consider that to be truly useful data has to be cleaned and maintained.
If GDPR is truly reflecting the interests of individuals, then it is also reflecting the interests of consumers, patients, users etc, each of whom make use of these systems. For any company that is customer facing, or any service that prides itself on the quality of its delivery to those individuals, “good data practice” should become part of the DNA of the organization.
GDPR in Practice
Need to understand why you are processing personal data, for example see the ICO’s Lawful Basis Guidance and their Lawful Basis Guidance Tool.
For websites, if you are processing personal data you will need a privacy policy to be in place. See the ICO’s Make your own privacy notice site which also provides a template.
Feudal Era Data Ecosystem
Figure: Feudal systems consist of serfs and vassals who are under the protection of a Lord. The Lord has a duty of care over the vassals, but due to power asymmetries that duty of care can be difficult to monitor and enforce. This is similar to the way our information is managed. Data controllers have a duty of care towards their data subjects, but there is also a power asymmetry between controller and subject.
Our current information infrastructure bears a close relation with feudal systems of government. In the feudal system a lord had a duty of care over his serfs and vassals, a duty to protect subjects. But in practice there was a power-asymetry. In feudal days protection was against Viking raiders, today, it is against information raiders. However, when there is an information leak, when there is some failure in protections, it is already too late.
Alternatively, our data is publicly shared, as in an information commons. Akin to common land of the medieval village. But just as commons were subject to overgrazing and poor management, so it is that much of our data cannot be managed in this way. In particularly personal, sensitive data.
I explored this idea further in this Guardian article on 2015/nov/16/information-barons-threaten-autonomy-privacy-online.
So how do we regulate for such an eventuality? I’m fond of a quote from Rodney Brooks that says: “You can’t regulate what doesn’t exist.” Indeed, it seems we have enough problems with regulating technologies and ideas that already exist today. But again, we can be inspired by the way that regulation has evolved in the past to take into account evolving technology. In particular, in intellectual property, patents emerged from the notion of ‘letters patent,’ which were monopolies granted by the monarch for a guild to work in a certain domain, such as weaving. They have evolved to be a mechanism for intellectual property rights.
Similarly, when motorised vehicles were introduced, after some false starts (including the poorly formed Red Flag Act) a Highway Code emerged that lays out the different responsibilities of road users in sharing the highway.

Figure: Evolving previous legislation is one route to develop new legislation in the presence of new technologies.
Guardian article on Let’s learn the rules of the digital road before talking about a web Magna Carta
Personal Data Trusts
What mechanism should we look to for forming these ‘data collectives.’ There are many inspirations from history including credit unions, building societies, co-operatives and land societies. Many of these have the bottom-up flavour of a collective that feels appropriate for managing data rights.
One particularly interesting mechanism also dates back to Medieval law. The Courts of Equity is a separate system of law that runs alongside Common Law. One of the domains of law it recognises are Trusts.
Trusts are institutions where there is an enhanced duty of care, known as “fiducirary duty” or “undivided loyalty” over the trustees to implement the constituent terms of the trust.
Broadly speaking a Trust has three components. There are the settlors. This group is the group that starts with assets. These might be rights to the property, or in the data trust, the rights to data. Then there are the beneficiaries. This is the group that will benefit from the operation of the trust. Finally there are the Trustees. This group oversees the management of the trust and ensures that the settlors intent is being conformed to in the management of the assets.
In a Data Trust (Delacroix and Lawrence, 2019) the settlors and the beneficiaries will be the same, or significantly overlapping groups. Unusually, because the value of data only comes when it accumulates, it is only once the data is within the Trust that it becomes useful. In the data trust, the Trustee takes on the role of data-controller. But they are now obliged to conform to the constitutional terms of the trust that is formed.
The data trust is not a specfic solution for data sharing. It is a set of legal mechanisms that can be used to create solutions. The consitutional terms of the trust will depend on what data is being shared and for what purpose. One can imagine data trusts that are associated with special interests, like a group of patients with a particular cancer. Or data trusts that might be associated with a region (the Hackney Data Trust) for assisting with local issues like transport links etc. Or one could imagine general data trusts, that would interact with individual specialized data trusts.
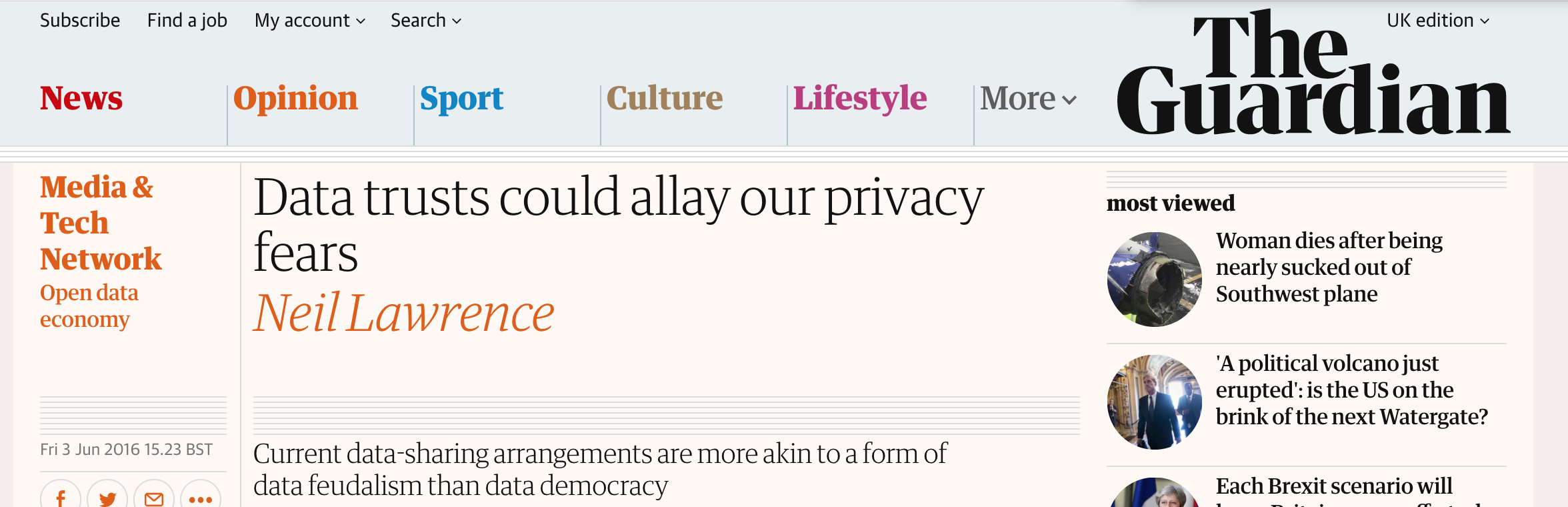
Figure: This article published in 2016 in the Guardian outlines the ideas behind data trusts.
Guardian article on Data Trusts
Importantly, any data governance approach is going to have tensions. In particular, there is a need to represent the interests of the individual, the interests of society and those of vulnerable people (such as children). Any data constitutional terms should also consider issues such as enfranchisement of the data subjects. There is a value based choice for how particular data should be shared.
But in order to enact such choices, and ensure that the correct responsibilities are applied to the data controllers, Trust law seems a promising avenue to pursue in institutionalising data sharing.
Data Trusts Initiative
The Data Trusts Initiative, funded by the Patrick J. McGovern Foundation is supporting three pilot projects that consider how bottom-up empowerment can redress the imbalance associated with the digital oligarchy.

Figure: The Data Trusts Initiative (http://datatrusts.uk) hosts blog posts helping build understanding of data trusts and supports research and pilot projects.
Progress So Far
In its first 18 months of operation, the Initiative has:
Convened over 200 leading data ethics researchers and practitioners;
Funded 7 new research projects tackling knowledge gaps in data trust theory and practice;
Supported 3 real-world data trust pilot projects establishing new data stewardship mechanisms.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com
References
the challenge of understanding what information pertains to is known as knowledge representation.↩︎