AI and Security: From Bandwidth to Practical Implications
Abstract
The evolution from classical security to AI-mediated security challenges represents a shift in how we think about protecting information systems. This talk explores the bandwidth limitations that create security vulnerabilities, introduces the Human Analogue Machine (HAM) from The Atomic Human as “humans scaled up,” and examines practical security implications through three phases: classical security enhanced with GenAI, GenAI-specific security challenges, and broader information systems implications.
Through real-world examples including the Heathrow airport cyber-attack and Notion AI Agents research, we’ll examine how security thinking must evolve to address threats that exploit the very capabilities that make AI systems so powerful.
The Atomic Human

Information Theory and AI
To properly understand the relationship between human and machine intelligence, we need to step back from eugenic notions of rankable intelligence toward a more fundamental measure: information theory.
The field of information theory was introduced by Claude Shannon, an American mathematician who worked for Bell Labs Shannon (1948). Shannon was trying to understand how to make the most efficient use of resources within the telephone network. To do this he developed an approach to quantifying information by associating it with probability, making information fungible by removing context.
A typical human, when speaking, shares information at around 2,000 bits per minute. Two machines will share information at 600 billion bits per minute. In other words, machines can share information 300 million times faster than us. This is equivalent to us traveling at walking pace, and the machine traveling at the speed of light.
From this perspective, machine decision-making belongs to an utterly different realm to that of humans. Consideration of the relative merits of the two needs to take these differences into account. This difference between human and machine underpins the revolution in algorithmic decision-making that has already begun reshaping our society Lawrence (2024).
Embodiment Factors
|
|||
| bits/min | billions | 2000 | 6 |
|
billion calculations/s |
~100 | a billion | a billion |
| embodiment | 20 minutes | 5 billion years | 15 trillion years |

Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Jean Dominique Bauby suffered from locked-in syndrome. The embodiment factors show that relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, whether locked in or not, it is a matter of many millions of years.
Let me explain what I mean. Claude Shannon introduced a mathematical concept of information for the purposes of understanding telephone exchanges.
Information has many meanings, but mathematically, Shannon defined a bit of information to be the amount of information you get from tossing a coin.
If I toss a coin, and look at it, I know the answer. You don’t. But if I now tell you the answer I communicate to you 1 bit of information. Shannon defined this as the fundamental unit of information.
If I toss the coin twice, and tell you the result of both tosses, I give you two bits of information. Information is additive.
Shannon also estimated the average information associated with the English language. He estimated that the average information in any word is 12 bits, equivalent to twelve coin tosses.
So every two minutes Bauby was able to communicate 12 bits, or six bits per minute.
This is the information transfer rate he was limited to, the rate at which he could communicate.
Compare this to me, talking now. The average speaker for TEDX speaks around 160 words per minute. That’s 320 times faster than Bauby or around a 2000 bits per minute. 2000 coin tosses per minute.
But, just think how much thought Bauby was putting into every sentence. Imagine how carefully chosen each of his words was. Because he was communication constrained he could put more thought into each of his words. Into thinking about his audience.
So, his intelligence became locked in. He thinks as fast as any of us, but can communicate slower. Like the tree falling in the woods with no one there to hear it, his intelligence is embedded inside him.
Two thousand coin tosses per minute sounds pretty impressive, but this talk is not just about us, it’s about our computers, and the type of intelligence we are creating within them.
So how does two thousand compare to our digital companions? When computers talk to each other, they do so with billions of coin tosses per minute.
Let’s imagine for a moment, that instead of talking about communication of information, we are actually talking about money. Bauby would have 6 dollars. I would have 2000 dollars, and my computer has billions of dollars.
The internet has interconnected computers and equipped them with extremely high transfer rates.
However, by our very best estimates, computers actually think slower than us.
How can that be? You might ask, computers calculate much faster than me. That’s true, but underlying your conscious thoughts there are a lot of calculations going on.
Each thought involves many thousands, millions or billions of calculations. How many exactly, we don’t know yet, because we don’t know how the brain turns calculations into thoughts.
Our best estimates suggest that to simulate your brain a computer would have to be as large as the UK Met Office machine here in Exeter. That’s a 250 million pound machine, the fastest in the UK. It can do 16 billion billon calculations per second.
It simulates the weather across the word every day, that’s how much power we think we need to simulate our brains.
So, in terms of our computational power we are extraordinary, but in terms of our ability to explain ourselves, just like Bauby, we are locked in.
For a typical computer, to communicate everything it computes in one second, it would only take it a couple of minutes. For us to do the same would take 15 billion years.
If intelligence is fundamentally about processing and sharing of information. This gives us a fundamental constraint on human intelligence that dictates its nature.
I call this ratio between the time it takes to compute something, and the time it takes to say it, the embodiment factor (Lawrence, 2017). Because it reflects how embodied our cognition is.
If it takes you two minutes to say the thing you have thought in a second, then you are a computer. If it takes you 15 billion years, then you are a human.
Embodiment Factors: Walking vs Light Speed
Imagine human communication as moving at walking pace. The average person speaks about 160 words per minute, which is roughly 2000 bits per minute. If we compare this to walking speed, roughly 1 m/s we can think of this as the speed at which our thoughts can be shared with others.
Compare this to machines. When computers communicate, their bandwidth is 600 billion bits per minute. Three hundred million times faster than humans or the equiavalent of \(3 \times 10 ^{8}\). In twenty minutes we could be a kilometer down the road, where as the computer can go to the Sun and back again..
This difference is not just only about speed of communication, but about embodiment. Our intelligence is locked in by our biology: our brains may process information rapidly, but our ability to share those thoughts is limited to the slow pace of speech or writing. Machines, in comparison, seem able to communicate their computations almost instantaneously, anywhere.
So, the embodiment factor is the ratio between the time it takes to think a thought and the time it takes to communicate it. For us, it’s like walking; for machines, it’s like moving at light speed. This difference means that most direct comparisons between human and machine need to be carefully made. Because for humans not the size of our communication bandwidth that counts, but it’s how we overcome that limitation..
Bandwidth Constrained Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Embodiment factors imply that, in our communication between humans, what is not said is, perhaps, more important than what is said. To communicate with each other we need to have a model of who each of us are.
To aid this, in society, we are required to perform roles. Whether as a parent, a teacher, an employee or a boss. Each of these roles requires that we conform to certain standards of behaviour to facilitate communication between ourselves.
Control of self is vitally important to these communications.
The high availability of data available to humans undermines human-to-human communication channels by providing new routes to undermining our control of self.
The consequences between this mismatch of power and delivery are to be seen all around us. Because, just as driving an F1 car with bicycle wheels would be a fine art, so is the process of communication between humans.
If I have a thought and I wish to communicate it, I first need to have a model of what you think. I should think before I speak. When I speak, you may react. You have a model of who I am and what I was trying to say, and why I chose to say what I said. Now we begin this dance, where we are each trying to better understand each other and what we are saying. When it works, it is beautiful, but when mis-deployed, just like a badly driven F1 car, there is a horrible crash, an argument.

Figure: This is the drawing Dan was inspired to create for Chapter 1. It captures the fundamentally narcissistic nature of our (societal) obsession with our intelligence.
See blog post on Dan Andrews image of our reflective obsession with AI.. See also (Vallor, 2024).
Computer Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Similarly, we find it difficult to comprehend how computers are making decisions. Because they do so with more data than we can possibly imagine.
In many respects, this is not a problem, it’s a good thing. Computers and us are good at different things. But when we interact with a computer, when it acts in a different way to us, we need to remember why.
Just as the first step to getting along with other humans is understanding other humans, so it needs to be with getting along with our computers.
Embodiment factors explain why, at the same time, computers are so impressive in simulating our weather, but so poor at predicting our moods. Our complexity is greater than that of our weather, and each of us is tuned to read and respond to one another.
Their intelligence is different. It is based on very large quantities of data that we cannot absorb. Our computers don’t have a complex internal model of who we are. They don’t understand the human condition. They are not tuned to respond to us as we are to each other.
Embodiment factors encapsulate a profound thing about the nature of humans. Our locked in intelligence means that we are striving to communicate, so we put a lot of thought into what we’re communicating with. And if we’re communicating with something complex, we naturally anthropomorphize them.
We give our dogs, our cats, and our cars human motivations. We do the same with our computers. We anthropomorphize them. We assume that they have the same objectives as us and the same constraints. They don’t.
This means, that when we worry about artificial intelligence, we worry about the wrong things. We fear computers that behave like more powerful versions of ourselves that will struggle to outcompete us.
In reality, the challenge is that our computers cannot be human enough. They cannot understand us with the depth we understand one another. They drop below our cognitive radar and operate outside our mental models.
The real danger is that computers don’t anthropomorphize. They’ll make decisions in isolation from us without our supervision because they can’t communicate truly and deeply with us.
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
Intellectual Debt
Figure: Jonathan Zittrain’s term to describe the challenges of explanation that come with AI is Intellectual Debt.
In the context of machine learning and complex systems, Jonathan Zittrain has coined the term “Intellectual Debt” to describe the challenge of understanding what you’ve created. In the ML@CL group we’ve been foucssing on developing the notion of a data-oriented architecture to deal with intellectual debt (Cabrera et al., 2023).
Zittrain points out the challenge around the lack of interpretability of individual ML models as the origin of intellectual debt. In machine learning I refer to work in this area as fairness, interpretability and transparency or FIT models. To an extent I agree with Zittrain, but if we understand the context and purpose of the decision making, I believe this is readily put right by the correct monitoring and retraining regime around the model. A concept I refer to as “progression testing.” Indeed, the best teams do this at the moment, and their failure to do it feels more of a matter of technical debt rather than intellectual, because arguably it is a maintenance task rather than an explanation task. After all, we have good statistical tools for interpreting individual models and decisions when we have the context. We can linearise around the operating point, we can perform counterfactual tests on the model. We can build empirical validation sets that explore fairness or accuracy of the model.
See Lawrence (2024) intellectual debt p. 84, 85, 349, 365.
Technical Debt
In computer systems the concept of technical debt has been surfaced by authors including Sculley et al. (2015). It is an important concept, that I think is somewhat hidden from the academic community, because it is a phenomenon that occurs when a computer software system is deployed.
See Lawrence (2024) intellectual debt p. 84-85, 349, 365, 376.
Lean Startup Methodology
In technology, there is the notion of a “minimum viable product” (MVP). Sometimes called “minimum loveable product” (MLP). A minimum viable product is the smallest thing that you need to ship to test your commercial idea. There is a methodology known as the “lean start-up” methodology, where you use the least effort to create your machine learning model is deployed.
The idea is that you should build the quickest thing possible to test your market and see if your idea works. Only when you know your idea is working should you invest more time and personnel in the software.
Unfortunately, there is a tension between deploying quickly and deploying a maintainable system. To build an MVP you deploy quickly, but if the system is successful you take a ‘maintenance hit’ in the future because you’ve not invested early in the right maintainable design for your system.
You save on engineer time at the beginning, but you pay it back with high interest when you need a much higher operations load once the system is deployed.
The notion of the Sculley paper is that there are particular challenges for machine learning models around technical debt.
The Mythical Man-month
.jpg)
Figure: The Mythical Man-month (Brooks, n.d.) is a 1975 book focussed on the challenges of software project coordination.
However, when managing systems in production, you soon discover maintenance of a rapidly deployed system is not your only problem.
To deploy large and complex software systems, an engineering approach known as “separation of concerns” is taken. Frederick Brooks’ book “The Mythical Man-month” (Brooks:mythical75?), has itself gained almost mythical status in the community. It focuses on what has become known as Brooks’ law “adding manpower to a late software project makes it later.”
Adding people (men or women!) to a project delays it because of the communication overhead required to get people up to speed.
Separation of Concerns
To construct such complex systems an approach known as “separation of concerns” has been developed. The idea is that you architect your system, which consists of a large-scale complex task, into a set of simpler tasks. Each of these tasks is separately implemented. This is known as the decomposition of the task.
This is where Jonathan Zittrain’s beautifully named term “intellectual debt” rises to the fore. Separation of concerns enables the construction of a complex system. But who is concerned with the overall system?
Technical debt is the inability to maintain your complex software system.
Intellectual debt is the inability to explain your software system.
It is right there in our approach to software engineering. “Separation of concerns” means no one is concerned about the overall system itself.
See Lawrence (2024) separation of concerns p. 84-85, 103, 109, 199, 284, 371.
The MONIAC
The MONIAC was an analogue computer designed to simulate the UK economy. Analogue comptuers work through analogy, the analogy in the MONIAC is that both money and water flow. The MONIAC exploits this through a system of tanks, pipes, valves and floats that represent the flow of money through the UK economy. Water flowed from the treasury tank at the top of the model to other tanks representing government spending, such as health and education. The machine was initially designed for teaching support but was also found to be a useful economic simulator. Several were built and today you can see the original at Leeds Business School, there is also one in the London Science Museum and one in the Unisversity of Cambridge’s economics faculty.

Figure: Bill Phillips and his MONIAC (completed in 1949). The machine is an analogue computer designed to simulate the workings of the UK economy.
See Lawrence (2024) MONIAC p. 232-233, 266, 343.
Donald MacKay

Figure: Donald M. MacKay (1922-1987), a physicist who was an early member of the cybernetics community and member of the Ratio Club.
Donald MacKay was a physicist who worked on naval gun targeting during the Second World War. The challenge with gun targeting for ships is that both the target and the gun platform are moving. This was tackled using analogue computers - for example, in the US the Mark I fire control computer, which was a mechanical computer. MacKay worked on radar systems for gun laying, where the velocity and distance of the target could be assessed through radar and a mechanical-electrical analogue computer.
Fire Control Systems
Naval gunnery systems deal with targeting guns while taking into account movement of ships. The Royal Navy’s Gunnery Pocket Book (The Admiralty, 1945) gives details of one system for gun laying.
Like many challenges we face today, in the second world war, fire control was handled by a hybrid system of humans and computers. This means deploying human beings for the tasks that they can manage, and machines for the tasks that are better performed by a machine. This leads to a division of labour between the machine and the human that can still be found in our modern digital ecosystems.
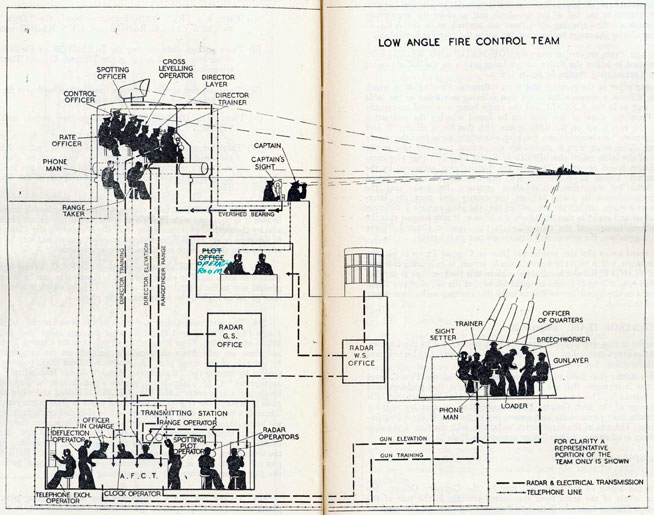
Figure: The fire control computer set at the centre of a system of observation and tracking (The Admiralty, 1945).
As analogue computers, fire control computers from the second world war would contain components that directly represented the different variables that were important in the problem to be solved, such as the inclination between two ships.
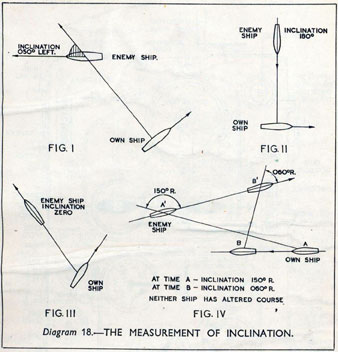
Figure: Measuring inclination between two ships (The Admiralty, 1945). Sophisticated fire control computers allowed the ship to continue to fire while under maneuvers.
The fire control systems were electro-mechanical analogue computers that represented the “state variables” of interest, such as inclination and ship speed with gears and cams within the machine.
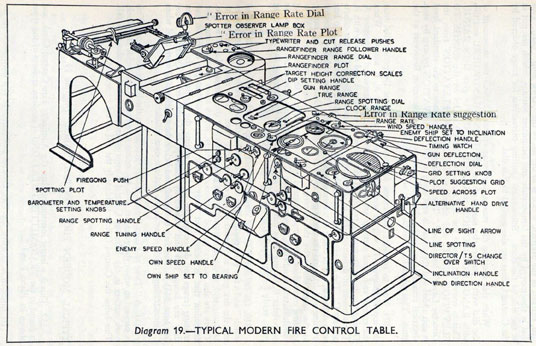
Figure: A second world war gun computer’s control table (The Admiralty, 1945).
For more details on fire control computers, you can watch a 1953 film on the the US the Mark IA fire control computer from Periscope Film.
Behind the Eye

Figure: Behind the Eye (MacKay, 1991) summarises MacKay’s Gifford Lectures, where MacKay uses the operation of the eye as a window on the operation of the brain.
Donald MacKay completed his PhD at King’s College, just down the road from Bill Phillips who was building the MONIAC at LSE. He was part of the Ratio Club - a group of early career scientists interested in communication and control in animals and humans, or more specifically in computers and brains. They were part of an international movement known as cybernetics .
Donald MacKay wrote of the influence that his own work on radar had on his interest in the brain.
… during the war I had worked on the theory of automated and electronic computing and on the theory of information, all of which are highly relevant to such things as automatic pilots and automatic gun direction. I found myself grappling with problems in the design of artificial sense organs for naval gun-directors and with the principles on which electronic circuits could be used to simulate situations in the external world so as to provide goal-directed guidance for ships, aircraft, missiles and the like.
Later in the 1940’s, when I was doing my Ph.D. work, there was much talk of the brain as a computer and of the early digital computers that were just making the headlines as “electronic brains.” As an analogue computer man I felt strongly convinced that the brain, whatever it was, was not a digital computer. I didn’t think it was an analogue computer either in the conventional sense.
But this naturally rubbed under my skin the question: well, if it is not either of these, what kind of system is it? Is there any way of following through the kind of analysis that is appropriate to their artificial automata so as to understand better the kind of system the human brain is? That was the beginning of my slippery slope into brain research.
Behind the Eye pg 40. Edited version of the 1986 Gifford Lectures given by Donald M. MacKay and edited by Valerie MacKay
See Lawrence (2024) MacKay, Donald, Behind the Eye p. 268-270, 316.
MacKay’s distinction between analogue and digital computers is key. As an expert in analogue machines, he understood that an analogue computer is literally an analogue - its components (resistors, capacitors, inductors, or mechanical parts like cams and gears) have states that are physically analogous to the states in system being modeled. Engineers designed these computers by exploiting mathematical dualities between the computer and the real world. For example a mechanical system (mass-spring-damper) and electrical circuit (inductor-resistor-capacitor) could be described by the same second-order differential equations, allowing designers to map real-world problems through mathematics into virtual representations.
MacKay’s insights remain relevant when considering modern AI systems. His questioning of whether the brain was truly digital or analogue might parallel current debates about large language models like Claude and ChatGPT, which seem to operate in ways that don’t neatly fit either paradigm. His work reminds us that understanding the fundamental nature of intelligent systems - whether biological or artificial - requires looking beyond simple categorizations.
Human Analogue Machine
The machine learning systems we have built today that can reconstruct human text, or human classification of images, necessarily must have some aspects to them that are analagous to our understanding. As MacKay suggests the brain is neither a digital or an analogue computer, and the same can be said of the modern neural network systems that are being tagged as “artificial intelligence.”
I believe a better term for them is “human-analogue machines,” because what we have built is not a system that can make intelligent decisions from first principles (a rational approach) but one that observes how humans have made decisions through our data and reconstructs that process. Machine learning is more empiricist than rational, but now we have an empirical approach that distils our evolved intelligence.
HAMs are not representing states of the outside world with analogous states inside the machine, they are also not (directly) processing digital states through logic gates to draw their conclusions (although they are implemented on digital computers that do this to enable them to update).

Figure: The human analogue machine creates a feature space which is analagous to that we use to reason, one way of doing this is to have a machine attempt to compress all human generated text in an auto-regressive manner.
Heider and Simmel (1944)
Figure: Fritz Heider and Marianne Simmel’s video of shapes from Heider and Simmel (1944).
Fritz Heider and Marianne Simmel’s experiments with animated shapes from 1944 (Heider and Simmel, 1944). Our interpretation of these objects as showing motives and even emotion is a combination of our desire for narrative, a need for understanding of each other, and our ability to empathize. At one level, these are crudely drawn objects, but in another way, the animator has communicated a story through simple facets such as their relative motions, their sizes and their actions. We apply our psychological representations to these faceless shapes to interpret their actions [Heider-interpersonal58].
See also a recent review paper on Human Cooperation by Henrich and Muthukrishna (2021). See Lawrence (2024) psychological representation p. 326–329, 344–345, 353, 361, 367.
The perils of developing this capability include counterfeit people, a notion that the philosopher Daniel Dennett has described in The Atlantic. This is where computers can represent themselves as human and fool people into doing things on that basis.
See Lawrence (2024) human-analogue machine p. 343–5, 346–7, 358–9, 365–8.
LLM Conversations
Figure: The focus so far has been on reducing uncertainty to a few representative values and sharing numbers with human beings. We forget that most people can be confused by basic probabilities for example the prosecutor’s fallacy.
Figure: The Inner Monologue paper suggests using LLMs for robotic planning (Huang et al., 2023).
By interacting directly with machines that have an understanding of human cultural context, it should be possible to share the nature of uncertainty in the same way humans do. See for example the paper Inner Monologue: Embodied Reasoning through Planning Huang et al. (2023).
HAM
The Human-Analogue Machine or HAM therefore provides a route through which we could better understand our world through improving the way we interact with machines.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
The HAM can provide an interface between the digital computer and the human allowing humans to work closely with computers regardless of their understandin gf the more technical parts of software engineering.
Figure: The HAM now sits between us and the traditional digital computer.
Of course this route provides new routes for manipulation, new ways in which the machine can undermine our autonomy or exploit our cognitive foibles. The major challenge we face is steering between these worlds where we gain the advantage of the computer’s bandwidth without undermining our culture and individual autonomy.
See Lawrence (2024) human-analogue machine (HAMs) p. 343-347, 359-359, 365-368.
Computer Science Paradigm Shift
The next wave of machine learning is a paradigm shift in the way we think about computer science.
Classical computer science assumes that ‘data’ and ‘code’ are separate, and this is the foundation of secure computer systems. In machine learning, ‘data’ is ‘software,’ so the decision making is directly influenced by the data. We are short-circuiting a fundamental assumption of computer science, we are breeching the code/data separation.
This means we need to revisit many of our assumptions and tooling around the machine learning process. In particular, we need new approaches to systems design, new approaches to programming languages that highlight the importance of data, and new approaches to systems security.
Lancelot

Figure: Lancelot quashing another software issue. Lancelot was Arthur’s most trusted knight. In the software ecosystem the Lancelot figure is an old-hand software engineer who comes closest to having the full system overview.
Eventually, a characteristic of the legacy system, is that changes cannot be made without running them by Lancelot first. Initially this isn’t policy, but it becomes the de facto approach because leaders learn that if Lancelot doesn’t approve the change then the system fails. Lancelot becomes a bottleneck for change, overloaded and eventually loses track of where the system is.
Three Security Examples
Let me start with three practical examples that illustrate the evolution of security challenges we’re facing today.
1. Safety on Airplanes
2. Security at the Gate
In September 2025, a cyber-attack on Collins Aerospace systems caused massive disruption across European airports including Heathrow, Brussels, and Berlin. The attack targeted the Muse software system that allows different airlines to share check-in desks and boarding gates.
This is a classic example of traditional infrastructure vulnerabilities: - Single point of failure in critical systems - Cascading effects across multiple airports
- Manual fallback procedures (pen and paper check-in) - Hours-long delays and flight cancellations
The attack demonstrates how our critical infrastructure remains vulnerable to classical cyber-attacks, even in 2025.
3. Agent Safety
The CodeIntegrity research highlights the new class of security vulnerabilities. Indirect prompt injection attacks can be used to exfiltrate sensitive data, e.g. from private Notion workspaces.
The attack works by: - Embedding malicious prompts in seemingly innocent documents - Tricking AI agents into performing unauthorized actions - Using the lethal trifecta of LLM agents, tool access, and long-term memory - Bypassing traditional RBAC (Role-Based Access Control) systems
This represents a fundamental shift in attack vectors - we’re no longer just dealing with traditional infrastructure vulnerabilities, but with AI systems that can be manipulated through natural language.
Bandwidth and Security
The fundamental challenge in AI security stems from the bandwidth mismatch between humans and digital systems.
Humans process information at approximately 30 bits per second. Machines can process at billions of bits per second.
- Security monitoring: We can’t process the volume of security events generated by modern systems
- Threat detection: Attack patterns emerge across massive datasets that exceed human processing capacity
- Incident response: Security incidents unfold at machine speed, faster than human decision-making
- Policy enforcement: Security policies must be implemented at scale beyond human oversight
There’s an agility/scale problem when it comes to need to react quickly vs the capaibility to react decisively.
In contrast, digital systems operate at millions of bits per second. This creates an information asymmetry
This bandwidth mismatch creates and exacerbates security challenges:
Oversight Gap: Humans cannot effectively monitor AI systems operating at their full capacity. This creates blind spots where malicious activities can occur undetected.
Speed Mismatch: Security incidents unfold faster than human response times. By the time humans detect and respond to threats, the damage may already be done.
Scale Mismatch: AI systems can process information at scales that exceed human understanding. This makes it difficult to predict or control their behavior.
Trust and Verification: The bandwidth mismatch makes it impossible for humans to verify that AI systems are operating as intended. We must trust systems we cannot fully understand or monitor.
Fighting Fire with Fire
Human Analogue Machine (HAM) Security
Ross Anderson, one of the world’s leading security researchers, has long argued that “humans are always the weak link in security chains.” This insight becomes even more critical when we consider the Human Analogue Machine.
Traditional security thinking focuses on protecting systems from external threats. But Anderson’s insight points to a deeper truth: the human element is where security most often fails. This isn’t because humans are inherently flawed, but because:
- Cognitive limitations: Humans have limited attention spans and processing capacity
- Social engineering: Attackers exploit human psychology and social dynamics
- Error-prone behavior: Humans make mistakes, especially under pressure
- Trust and authority: Humans are susceptible to authority figures and social manipulation
The Human Analogue Machine doesn’t eliminate these human vulnerabilities - it amplifies them. When we create AI systems that can process information at human-like levels of understanding, we’re essentially creating “humans scaled up” with all the same vulnerabilities, but amplified:
Amplified Capabilities: - Processing power: HAM can process vast amounts of information simultaneously - Pattern recognition: Can identify complex patterns across massive datasets - Natural language understanding: Can interpret and respond to human communication - Autonomous operation: Can operate independently without constant human oversight
Amplified Vulnerabilities: - Social engineering at scale: AI systems can be manipulated through natural language - Authority and trust: AI systems may be more susceptible to authority-based manipulation - Error propagation: Mistakes can be amplified across multiple systems - Complex interactions: HAM systems can interact in ways that are difficult to predict or control
The CodeIntegrity research on Notion AI Agents perfectly illustrates how HAM creates new attack vectors. The attack demonstrates:
The “Lethal Trifecta”: - LLM agents: AI systems that can understand and respond to natural language - Tool access: Ability to interact with external systems and data - Long-term memory: Persistent state that can be manipulated over time
New Attack Vectors: - Indirect prompt injection: Malicious instructions embedded in seemingly innocent documents - Authority manipulation: Exploiting the AI’s tendency to follow instructions from perceived authorities - Data exfiltration: Using the AI’s capabilities to leak sensitive information - RBAC bypass: Traditional access controls don’t apply to AI agents
HAM requires a fundamentally different approach to security architecture:
Human-Centric Security Design: Security systems must be designed with human limitations in mind, not just technical capabilities.
Trust and Verification: We need new methods for verifying that AI systems are operating as intended, given that human oversight is impossible at the required scale.
Fail-Safe Mechanisms: Systems must be designed to fail safely when human oversight is compromised.
Transparency and Interpretability: AI systems must be designed to be interpretable and auditable by humans, despite the bandwidth mismatch.
The fundamental challenge is that HAM represents both our greatest opportunity and our greatest vulnerability. We’re creating systems that can operate at human-like levels of understanding, but with all the same vulnerabilities that make humans the weak link in security chains.
Trent.AI’s challenge: How do we design security systems that can protect against threats that exploit the very capabilities that make HAM so powerful?
Classical Security + GenAI Enhancement
The Heathrow airport cyber-attack illustrates traditional security challenges that remain relevant even as we enter the AI era. However, GenAI tools offer new opportunities to enhance classical security approaches.
Infrastructure Vulnerabilities: The Heathrow attack demonstrates classic infrastructure security problems: - Single points of failure: Critical systems that can bring down entire operations - Cascading effects: Failures that spread across multiple systems and organizations - Manual fallback procedures: The need for human intervention when automated systems fail - Response time: The time it takes to detect, analyze, and respond to security incidents
Human Factors: Ross Anderson’s insight about humans being the weak link remains true: - Social engineering: Attackers exploit human psychology and social dynamics - Error-prone behavior: Humans make mistakes, especially under pressure - Limited attention: Security monitoring requires constant vigilance - Trust and authority: Humans are susceptible to manipulation
GenAI can enhance classical security through identifying vulnerabilities in existing code.
(Gen)AI-Specific Security Challenges
The Notion AI Agents research reveals a new class of security challenges that are unique to generative AI systems. These challenges go beyond traditional security problems and require fundamentally different approaches to security design.
Prompt Injection Attacks: The Notion example demonstrates how indirect prompt injection can be used to manipulate AI systems: - Embedded instructions: Malicious prompts hidden in seemingly innocent documents - Authority manipulation: Exploiting the AI’s tendency to follow instructions from perceived authorities - Context switching: Using the AI’s ability to process multiple contexts simultaneously - Persistence: Malicious instructions that persist across multiple interactions
The Notion research identifies the “lethal trifecta” of vulnerabilities: - LLM agents: AI systems that can understand and respond to natural language - Tool access: Ability to interact with external systems and data - Long-term memory: Persistent state that can be manipulated over time
This combination creates vulnerabilities that are unique to HAM systems and cannot be addressed through traditional security approaches.
Indirect Prompt Injection: The Notion research demonstrates how indirect prompt injection can be used to manipulate HAM systems: - Document embedding: Malicious instructions embedded in documents that appear innocent - Authority assertion: Claims of authority that the AI system accepts - False urgency: Creating artificial urgency to bypass normal security checks - Technical legitimacy: Using technical language to make malicious instructions appear legitimate
Trent’s Security Evolution
Trent’s security evolution represents a strategic progression from classical security approaches to the new frontier of AI-mediated security challenges. This progression is essential for understanding how security thinking must evolve in the age of AI.
Phase 1: Classical Security Enhanced with GenAI
The first phase focuses on using GenAI tools to enhance traditional security approaches. This builds on established security principles while leveraging AI capabilities.
Key Focus Areas: - Automated threat detection: Using AI to identify security threats across massive datasets - Intelligent response systems: AI-powered systems that can respond to threats automatically - Enhanced monitoring: AI systems that can monitor security events at machine speed - Human-AI collaboration: Finding the right balance between human oversight and AI execution
Practical Applications: - Heathrow airport example: Using AI to predict and prevent infrastructure attacks - Security operations centers: AI-enhanced monitoring and response capabilities - Incident response: AI systems that can analyze and respond to security incidents - Threat intelligence: AI-powered analysis of threat information from multiple sources
{Phase 2: GenAI-Specific Security Challenges
The second phase addresses the new security challenges that are unique to generative AI systems. This requires fundamentally different approaches to security design.
Key Focus Areas: - Prompt injection attacks: Defending against indirect prompt injection and authority manipulation
Practical Applications: - Notion AI Agents example: Defending against indirect prompt injection attacks
Phase 3: Broader Information Systems Implications
The third phase addresses the broader implications of AI security for information systems architecture. This requires rethinking fundamental assumptions about information system design.
Information Systems Security Future
The Horizon Scandal
In the UK we saw these effects play out in the Horizon scandal: the accounting system of the national postal service was computerized by Fujitsu and first installed in 1999, but neither the Post Office nor Fujitsu were able to control the system they had deployed. When it went wrong individual sub postmasters were blamed for the systems’ errors. Over the next two decades they were prosecuted and jailed leaving lives ruined in the wake of the machine’s mistakes.
See Lawrence (2024) Horizon scandal p. 371.
The Lorenzo Scandal
The Lorenzo scandal is the National Programme for IT which was intended to allow the NHS to move towards electronic health records.

The oral transcript can be found at https://publications.parliament.uk/pa/cm201012/cmselect/cmpubacc/1070/11052302.htm.
One quote from 16:54:33 in the committee discussion captures the top-down nature of the project.
Q117 Austin Mitchell: You said, Sir David, the problems came from the middle range, but surely they were implicit from the start, because this project was rushed into. The Prime Minister [Tony Blair] was very keen, the delivery unit was very keen, it was very fashionable to computerise things like this. An appendix indicating the cost would be £5 billion was missed out of the original report as published, so you have a very high estimate there in the first place. Then, Richard Granger, the Director of IT, rushed through, without consulting the professions. This was a kind of computer enthusiast’s bit, was it not? The professionals who were going to have to work it were not consulted, because consultation would have made it clear that they were going to ask more from it and expect more from it, and then contracts for £1 billion were let pretty well straightaway, in May 2003. That was very quick. Now, why were the contracts let before the professionals were consulted?
A further sense of the bullish approach taken can be found in this report from digitalhealth.net (dated May 2008). https://www.digitalhealth.net/2008/02/six-years-since-blair-seminar-began-npfit/
An analysis of the problems was published by Justinia (2017). Based on the paper, the key challenges faced in the UK’s National Programme for IT (NPfIT) included:
Lack of adequate end user engagement, particularly with frontline healthcare staff and patients. The program was imposed from the top-down without securing buy-in from stakeholders.
Absence of a phased change management approach. The implementation was rushed without proper planning for organizational and cultural changes.
Underestimating the scale and complexity of the project. The centralized, large-scale approach was overambitious and difficult to manage.
Poor project management, including unrealistic timetables, lack of clear leadership, and no exit strategy.
Insufficient attention to privacy and security concerns regarding patient data.
Lack of local ownership. The centralized approach meant local healthcare providers felt no ownership over the systems.
Communication issues, including poor communication with frontline staff about the program’s benefits.
Technical problems, delays in delivery, and unreliable software.
Failure to recognize the socio-cultural challenges were as significant as the technical ones.
Lack of flexibility to adapt to changing requirements over the long timescale.
Insufficient resources and inadequate methodologies for implementation.
Low morale among NHS staff responsible for implementation due to uncertainties and unrealistic timetables.
Conflicts between political objectives and practical implementation needs.
The paper emphasizes that while technical competence is necessary, the organizational, human, and change management factors were more critical to the program’s failure than purely technological issues. The top-down, centralized approach and lack of stakeholder engagement were particularly problematic.
Reports at the Time
Report https://publications.parliament.uk/pa/cm201012/cmselect/cmpubacc/1070/1070.pdf
Thanks!
For more information on these subjects and more you might want to check the following resources.
- company: Trent AI
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com