Artificial Intelligence: Reclaiming Control
Abstract
Though artificial intelligence is ubiquitous in our homes and workplaces, there is widespread misunderstanding of what it really is. Join us for this public lecture as Neil Lawrence, DeepMind Professor of Machine Learning encourages us to reframe our view of AI.
He’ll discuss how the artificial systems we have developed operate in a fundamentally different way to our own intelligence. He’ll describe how this difference in operational capability leads us to misunderstand the influence that decisions made by machine intelligence are having on our lives. Without this understanding we cannot take back control of those decisions from the machine. Along the way, he’ll chat with fellow Cambridge University researchers about how we maximise the benefits of these technologies while minimising the harms.
Introduction
It’s said that Henry Ford’s customers wanted a “a faster horse.” If Henry Ford was selling us artificial intelligence today, what would the customer call for, “a smarter human?” That’s certainly the picture of machine intelligence we find in science fiction narratives, but the reality of what we’ve developed is much more mundane.
Car engines produce prodigious power from petrol. Machine intelligences deliver decisions derived from data. In both cases the scale of consumption enables a speed of operation that is far beyond the capabilities of their natural counterparts. Unfettered energy consumption has consequences in the form of climate change. Does unbridled data consumption also have consequences for us?
If we devolve decision making to machines, we depend on those machines to accommodate our needs. If we don’t understand how those machines operate, we lose control over our destiny. Our mistake has been to see machine intelligence as a reflection of our intelligence. We cannot understand the smarter human without understanding the human. To understand the machine, we need to better understand ourselves.
Cambridge has been involved in the formulation of the methods used in the current wave of AI solutions since their beginnings. In 1997 I attend the Machine Learning and Generalisation Summer School at the Newton Institute. There we heard from many of those who developed the methods that are foundational to the recent wave of progress, including Geoff Hinton and Yann LeCun.


Figure: Neil standing outside the Newton Institute on 2nd August 1997, just after arriving for “Generalisation in Neural Networks and Machine Learning,” see page 26-30 of this report.

Figure: The ceiling of the Sistine Chapel.
Patrick Boyde’s talks on the Sistine Chapel focussed on both the structure of the chapel ceiling, describing the impression of height it was intended to give, as well as the significance and positioning of each of the panels and the meaning of the individual figures.

Figure: Photo of Detail of Creation of Man from the Sistine chapel ceiling.
One of the most famous panels is central in the ceiling, it’s the creation of man. Here, God in the guise of a pink-robed bearded man reaches out to a languid Adam.
The representation of God in this form seems typical of the time, because elsewhere in the Vatican Museums there are similar representations.

Figure: Photo detail of God.
https://commons.wikimedia.org/wiki/File:Michelangelo,_Creation_of_Adam_04.jpg
For a time at the head of all articles about AI, an image of the terminator was included.

Figure: Image of James Cameron’s terminator. Images like this have been used to illustrate articles about artificial intelligence.
Sometimes, this image is even combined with that of God to create what Beth Singler, a digital anthropologist who is a JRF at Hmerton College, refers to as the creation meme (Singler, 2020).

Figure: Beth Singler is a digital anthropologist who holds a JRF at Homerton College. She has explored parallels between the Michelangelo image of creation and our own notion of robotic creation
So in a very real sense, we can see that both God and AI are viewed by us as embodied intelligences, whether creator or created. We show these other-intelligences in a humanoid form.

Figure: Photo of David Mackay on Bicycle by David Stern. Taken for the book “Sustainable Energy without the Hot Air.”
My own understanding of why we might want to picture these intelligences as embodied goes back to lectures I heard at the institute by David MacKay. By the time I arrived in Cambridge, David was very focussed on the relationships between learning and information theory, and as well as his lecture at the Newton Institute, his group meetings were focussed on information theory and machine learning.
The key idea I wasnt to communicate next is related to our ability to share our thoughts.
The Diving Bell and the Butterfly

Figure: The Diving Bell and the Buttefly is the autobiography of Jean Dominique Bauby.
The Diving Bell and the Butterfly is the autobiography of Jean Dominique Bauby. Jean Dominique was the editor of the French Elle magazine, in 1995 at the age of 43, he suffered a major stroke. The stroke paralyzed him and rendered him speechless. He was only able to blink his left eyelid, he became a sufferer of locked in syndrome.
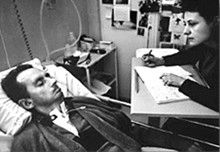
Figure: Jean Dominique Bauby was the Editor in Chief of the French Elle Magazine, he suffered a stroke that destroyed his brainstem, leaving him only capable of moving one eye. Jean Dominique became a victim of locked in syndrome.
Incredibly, Jean Dominique wrote his book after he became locked in. It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
The idea behind embodiment factors is that we are all in that situation. While not as extreme as for Bauby, we all have somewhat of a locked in intelligence.
|
|

|
Figure: Claude Shannon developed information theory which allows us to quantify how much Bauby can communicate. This allows us to compare how locked in he is to us.
Embodiment Factors
| bits/min | billions | 2,000 |
|
billion calculations/s |
~100 | a billion |
| embodiment | 20 minutes | 5 billion years |
Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, it is a matter of thousands of millions of years. See also “Living Together: Mind and Machine Intelligence” Lawrence (2017)
There is a fundamental limit placed on our intelligence based on our ability to communicate. Claude Shannon founded the field of information theory. The clever part of this theory is it allows us to separate our measurement of information from what the information pertains to.1
Shannon measured information in bits. One bit of information is the amount of information I pass to you when I give you the result of a coin toss. Shannon was also interested in the amount of information in the English language. He estimated that on average a word in the English language contains 12 bits of information.
Given typical speaking rates, that gives us an estimate of our ability to communicate of around 100 bits per second (Reed and Durlach, 1998). Computers on the other hand can communicate much more rapidly. Current wired network speeds are around a billion bits per second, ten million times faster.
When it comes to compute though, our best estimates indicate our computers are slower. A typical modern computer can process make around 100 billion floating point operations per second, each floating point operation involves a 64 bit number. So the computer is processing around 6,400 billion bits per second.
It’s difficult to get similar estimates for humans, but by some estimates the amount of compute we would require to simulate a human brain is equivalent to that in the UK’s fastest computer (Ananthanarayanan et al., 2009), the MET office machine in Exeter, which in 2018 ranks as the 11th fastest computer in the world. That machine simulates the world’s weather each morning, and then simulates the world’s climate in the afternoon. It is a 16 petaflop machine, processing around 1,000 trillion bits per second.
Heider and Simmel (1944)
Figure: Fritz Heider and Marianne Simmel’s video of shapes from Heider and Simmel (1944).
Fritz Heider and Marianne Simmel’s experiments with animated shapes from 1944 (Heider and Simmel, 1944). Our interpretation of these objects as showing motives and even emotion is a combination of our desire for narrative, a need for understanding of each other, and our ability to empathise. At one level, these are crudely drawn objects, but in another key way, the animator has communicated a story through simple facets such as their relative motions, their sizes and their actions. We apply our psychological representations to these faceless shapes in an effort to interpret their actions.
See also a recent review paper on Human Cooperation by Henrich and Muthukrishna (2021).
Human Communication
For human conversation to work, we require an internal model of who we are speaking to. We model each other, and combine our sense of who they are, who they think we are, and what has been said. This is our approach to dealing with the limited bandwidth connection we have. Empathy and understanding of intent. Mental dispositional concepts are used to augment our limited communication bandwidth.
Fritz Heider referred to the important point of a conversation as being that they are happenings that are “psychologically represented in each of the participants” (his emphasis) (Heider, 1958).
Bandwidth Constrained Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Embodiment factors imply that, in our communication between humans, what is not said is, perhaps, more important than what is said. To communicate with each other we need to have a model of who each of us are.
To aid this, in society, we are required to perform roles. Whether as a parent, a teacher, an employee or a boss. Each of these roles requires that we conform to certain standards of behaviour to facilitate communication between ourselves.
Control of self is vitally important to these communications.
The high availability of data available to humans undermines human-to-human communication channels by providing new routes to undermining our control of self.
Computer Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Similarly, we find it difficult to comprehend how computers are making decisions. Because they do so with more data than we can possibly imagine.
In many respects, this is not a problem, it’s a good thing. Computers and us are good at different things. But when we interact with a computer, when it acts in a different way to us, we need to remember why.
Just as the first step to getting along with other humans is understanding other humans, so it needs to be with getting along with our computers.
Embodiment factors explain why, at the same time, computers are so impressive in simulating our weather, but so poor at predicting our moods. Our complexity is greater than that of our weather, and each of us is tuned to read and respond to one another.
Their intelligence is different. It is based on very large quantities of data that we cannot absorb. Our computers don’t have a complex internal model of who we are. They don’t understand the human condition. They are not tuned to respond to us as we are to each other.
Embodiment factors encapsulate a profound thing about the nature of humans. Our locked in intelligence means that we are striving to communicate, so we put a lot of thought into what we’re communicating with. And if we’re communicating with something complex, we naturally anthropomorphize them.
We give our dogs, our cats and our cars human motivations. We do the same with our computers. We anthropomorphize them. We assume that they have the same objectives as us and the same constraints. They don’t.
This means, that when we worry about artificial intelligence, we worry about the wrong things. We fear computers that behave like more powerful versions of ourselves that will struggle to outcompete us.
In reality, the challenge is that our computers cannot be human enough. They cannot understand us with the depth we understand one another. They drop below our cognitive radar and operate outside our mental models.
The real danger is that computers don’t anthropomorphize. They’ll make decisions in isolation from us without our supervision, because they can’t communicate truly and deeply with us.
Figure: Our tendency to anthrox means that even when an intelligence is very different from ours we tend to embody it and represent it as having objectives similar to human.
Figure: Our tendency to anthrox means that even when an intelligence is very different from ours we tend to embody it and represent it as having objectives similar to human.
Evolved Relationship with Information
The high bandwidth of computers has resulted in a close relationship between the computer and data. Large amounts of information can flow between the two. The degree to which the computer is mediating our relationship with data means that we should consider it an intermediary.
Originaly our low bandwith relationship with data was affected by two characteristics. Firstly, our tendency to over-interpret driven by our need to extract as much knowledge from our low bandwidth information channel as possible. Secondly, by our improved understanding of the domain of mathematical statistics and how our cognitive biases can mislead us.
With this new set up there is a potential for assimilating far more information via the computer, but the computer can present this to us in various ways. If it’s motives are not aligned with ours then it can misrepresent the information. This needn’t be nefarious it can be simply as a result of the computer pursuing a different objective from us. For example, if the computer is aiming to maximize our interaction time that may be a different objective from ours which may be to summarize information in a representative manner in the shortest possible length of time.
For example, for me, it was a common experience to pick up my telephone with the intention of checking when my next appointment was, but to soon find myself distracted by another application on the phone, and end up reading something on the internet. By the time I’d finished reading, I would often have forgotten the reason I picked up my phone in the first place.
There are great benefits to be had from the huge amount of information we can unlock from this evolved relationship between us and data. In biology, large scale data sharing has been driven by a revolution in genomic, transcriptomic and epigenomic measurement. The improved inferences that can be drawn through summarizing data by computer have fundamentally changed the nature of biological science, now this phenomenon is also infuencing us in our daily lives as data measured by happenstance is increasingly used to characterize us.
Better mediation of this flow actually requires a better understanding of human-computer interaction. This in turn involves understanding our own intelligence better, what its cognitive biases are and how these might mislead us.
For further thoughts see Guardian article on marketing in the internet era from 2015.
You can also check my blog post on System Zero. also from 2015.
New Flow of Information
Classically the field of statistics focussed on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarise what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data, but must also deal with the possibility that the machine has either inadvertently or malisciously misrepresented the underlying data.
In the group Diana Robinson has been focussing on how we can communicate the machine’s understanding of uncertainty to clinicians, within the context blood plasma infusions and surgical operations.
Fairness in Decision Making
As a more general example, let’s consider fairness in decision making. Computers make decisions on the basis of our data, how can we have confidence in those decisions?

Figure: The convention for the protection of individuals with regard to the processing of personal data was opened for signature on 28th January 1981. It was the first legally binding international instrument in the field of data protection.
GDPR Origins
There’s been much recent talk about GDPR, much of it implying that the recent incarnation is radically different from previous incarnations. While the most recent iteration began to be developed in 2012, but in reality, its origins are much older. It dates back to 1981, and 28th January is “Data Potection day”. The essence of the law didn’t change much in the previous iterations. The critical chance was the size of the fines that the EU stipulated may be imposed for infringements. Paul Nemitz, who was closely involved with the drafting, told me that they were initially inspired by competition law, which levies fines of 10% of international revenue. The final implementation is restricted to 5%, but it’s worth pointing out that Facebook’s fine (imposed in the US by the FTC) was $5 billion dollars. Or approximately 7% of their international revenue at the time.
So the big change is the seriousness with which regulators are taking breaches of the intent of GDPR. And indeed, this newfound will on behalf of the EU led to an amount of panic around companies who rushed to see if they were complying with this strengthened legislation.
But is it really the big bad regulator coming down hard on the poor scientist or company, just trying to do an honest day’s work? I would argue not. The stipulations of the GDPR include fairly simple things like the ‘right to an explanation’ for consequential decision-making. Or the right to deletion, to remove personal private data from a corporate data ecosystem.
Guardian article on Digital Oligarchies
While these are new stipulations, if you reverse the argument and ask a company “would it not be a good thing if you could explain why your automated decision making system is making decision X about customer Y” seems perfectly reasonable. Or “Would it not be a good thing if we knew that we were capable of deleting customer Z’s data from our systems, rather than being concerned that it may be lying unregistered in an S3 bucket somewhere?”
Phrased in this way, you can see that GDPR perhaps would better stand for “Good Data Practice Rules,” and should really be being adopted by the scientist, the company or whoever in an effort to respect the rights of the people they aim to serve.
So how do Data Trusts fit into this landscape? Well it’s appropriate that we’ve mentioned the commons, because a current challenge is how we manage data rights within our community. And the situation is rather akin to that which one might have found in a feudal village (in the days before Houndkirk Moor was enclosed).
How the GDPR May Help
Early reactions to the General Data Protection Regulation by companies seem to have been fairly wary, but if we view the principles outlined in the GDPR as good practice, rather than regulation, it feels like companies can only improve their internal data ecosystems by conforming to the GDPR. For this reason, I like to think of the initials as standing for “Good Data Practice Rules” rather than General Data Protection Regulation. In particular, the term “data protection” is a misnomer, and indeed the earliest data protection directive from the EU (from 1981) refers to the protection of individuals with regard to the automatic processing of personal data, which is a much better sense of the term.
If we think of the legislation as protecting individuals, and we note that it seeks, and instead of viewing it as regulation, we view it as “Wouldn’t it be good if …,” e.g. in respect to the “right to an explanation”, we might suggest: “Wouldn’t it be good if we could explain why our automated decision making system made a particular decison.” That seems like good practice for an organization’s automated decision making systems.
Similarly, with regard to data minimization principles. Retaining the minimum amount of personal data needed to drive decisions could well lead to better decision making as it causes us to become intentional about which data is used rather than the sloppier thinking that “more is better” encourages. Particularly when we consider that to be truly useful data has to be cleaned and maintained.
If GDPR is truly reflecting the interests of individuals, then it is also reflecting the interests of consumers, patients, users etc, each of whom make use of these systems. For any company that is customer facing, or any service that prides itself on the quality of its delivery to those individuals, “good data practice” should become part of the DNA of the organization.
GDPR in Practice
Need to understand why you are processing personal data, for example see the ICO’s Lawful Basis Guidance and their Lawful Basis Guidance Tool.
For websites, if you are processing personal data you will need a privacy policy to be in place. See the ICO’s Make your own privacy notice site which also provides a template.
The GDPR gives us some indications of the aspects we might consider when judging whether or not a decision is “fair.”
But when considering fairness, it seems that there’s two forms that we might consider.
\(p\)-Fairness and \(n\)-Fairness
Figure: We seem to have two different aspects to fairness, which in practice can be in tension.
We’ve outlined \(n\)-fairness and \(p\)-fairness. By \(n\)-fairness we mean the sort of considerations that are associated with substantive equality of opportunity vs formal equality of opportunity. Formal equality of community is related to \(p\)-fairness. This is sometimes called procedural fairness and we might think of it as a performative form of fairness. It’s about clarity of rules, for example as applied in sport. \(n\)-Fairness is more nuanced. It’s a reflection of society’s normative judgment about how individuals may have been disadvantaged, e.g. due to their upbringing.
The important point here is that these forms of fairness are in tension. Good procedural fairness needs to be clear and understandable. It should be clear to everyone what the rules are, they shouldn’t be obscured by jargon or overly subtle concepts. \(p\)-Fairness should not be easily undermined by adversaries, it should be difficult to “cheat” good \(p\)-fairness. However, \(n\)-fairness requires nuance, understanding of the human condition, where we came from and how different individuals in our society have been advantaged or disadvantaged in their upbringing and their access to opportunity.
Pure \(n\)-fairness and pure \(p\)-fairness both have the feeling of dystopias. In practice, any decision making system needs to balance the two. The correct point of operation will depend on the context of the decision. Consider fair rules of a game of football, against fair distribution of social benefit. It is unlikely that there is ever an objectively correct balance between the two for any given context. Different individuals will favour \(p\) vs \(n\) according to their personal values.
Given the tension between the two forms of fairness, with \(p\) fairness requiring simple rules that are understandable by all, and \(n\) fairness requiring nuance and subtlety, how do we resolve this tension in practice?
Normally in human systems, significant decisions involve trained professionals. For example, judges, or accountants or doctors.
Training a professional involves lifting their “reflexive” response to a situation with “reflective” thinking about the consequences of their decision that rely not just on the professional’s expertise, but also their knowledge of what it is to be a human.
This marvellous resolution exploits the fact that while humans are increadibly complicated nuanced entities, other humans have an intuitive ability to understand their motivations and values. So the human is a complex entity that seems simple to other humans.
Reflexive and Reflective Intelligence
Another distinction I find helpful when thinking about intelligence is the difference between reflexive actions and reflective actions. We are much more aware of our reflections, but most actions we take are reflexive. And this can lead to an underestimate of the importance of our reflexive actions.
\[\text{reflect} \Longleftrightarrow \text{reflex}\]
It is our reflective capabilities that distinguish us from so many lower forms of intelligence. And it is also in reflective thinking that we can contextualise and justify our actions.
Reflective actions require longer timescales to deploy, often when we are in the moment it is the reflexive thinking that takes over. Naturally our biases about the world can enter in either our reflective or reflexive thinking, but biases associated with reflexive thinking are likely to be those we are unaware of.
This interaction between reflexive and reflective, where our reflective-self can place us within a wider cultural context, would seem key to better human decision making. If the reflexive-self can learn from the reflective-self to make better decisions, or if we have mechanisms of doubt that allow our reflective-self to intervene when our reflexive-decisions have consequences, then our reflexive thinking can be “lifted” to better reflect the results of our actions.
\[\text{reflect} \Longleftrightarrow \text{reflex}\]
The Great AI Fallacy
There is a lot of variation in the use of the term artificial intelligence. I’m sometimes asked to define it, but depending on whether you’re speaking to a member of the public, a fellow machine learning researcher, or someone from the business community, the sense of the term differs.
However, underlying its use I’ve detected one disturbing trend. A trend I’m beginining to think of as “The Great AI Fallacy.”
The fallacy is associated with an implicit promise that is embedded in many statements about Artificial Intelligence. Artificial Intelligence, as it currently exists, is merely a form of automated decision making. The implicit promise of Artificial Intelligence is that it will be the first wave of automation where the machine adapts to the human, rather than the human adapting to the machine.
How else can we explain the suspension of sensible business judgment that is accompanying the hype surrounding AI?
This fallacy is particularly pernicious because there are serious benefits to society in deploying this new wave of data-driven automated decision making. But the AI Fallacy is causing us to suspend our calibrated skepticism that is needed to deploy these systems safely and efficiently.
The problem is compounded because many of the techniques that we’re speaking of were originally developed in academic laboratories in isolation from real-world deployment.

Figure: We seem to have fallen for a perspective on AI that suggests it will adapt to our schedule, rather in the manner of a 1930s manservant.
In large part, these challenges associated with AI are because AI has no understanding of the human condition. But there’s also a problem that we don’t have an intuitive understanding of AI and how it is working.
The marvellous resolution does not apply to machine driven decisions, because we don’t have an intuitive understanding of what motivates the machine.
The consequence is that the AI, driven by it’s detailed knowledge of who we are, arising from its access to large quantities of our data, can undermine the delicate balance of our decision-making, and replace our objectives with it’s own simplistic ideas of how things should be.
So, what are the resolutions for this problem? At Cambridge we are focussed on three different interventions.
The first example is empowering those who want to use AI through education and tool development. The Accelerate Programme for Scientific Discovery, sponsored by Schmidt Futures, focusses on empowering scientists and other domains across the University with the tools and understanding they need to make use of AI in practice.
The Accelerate Programme
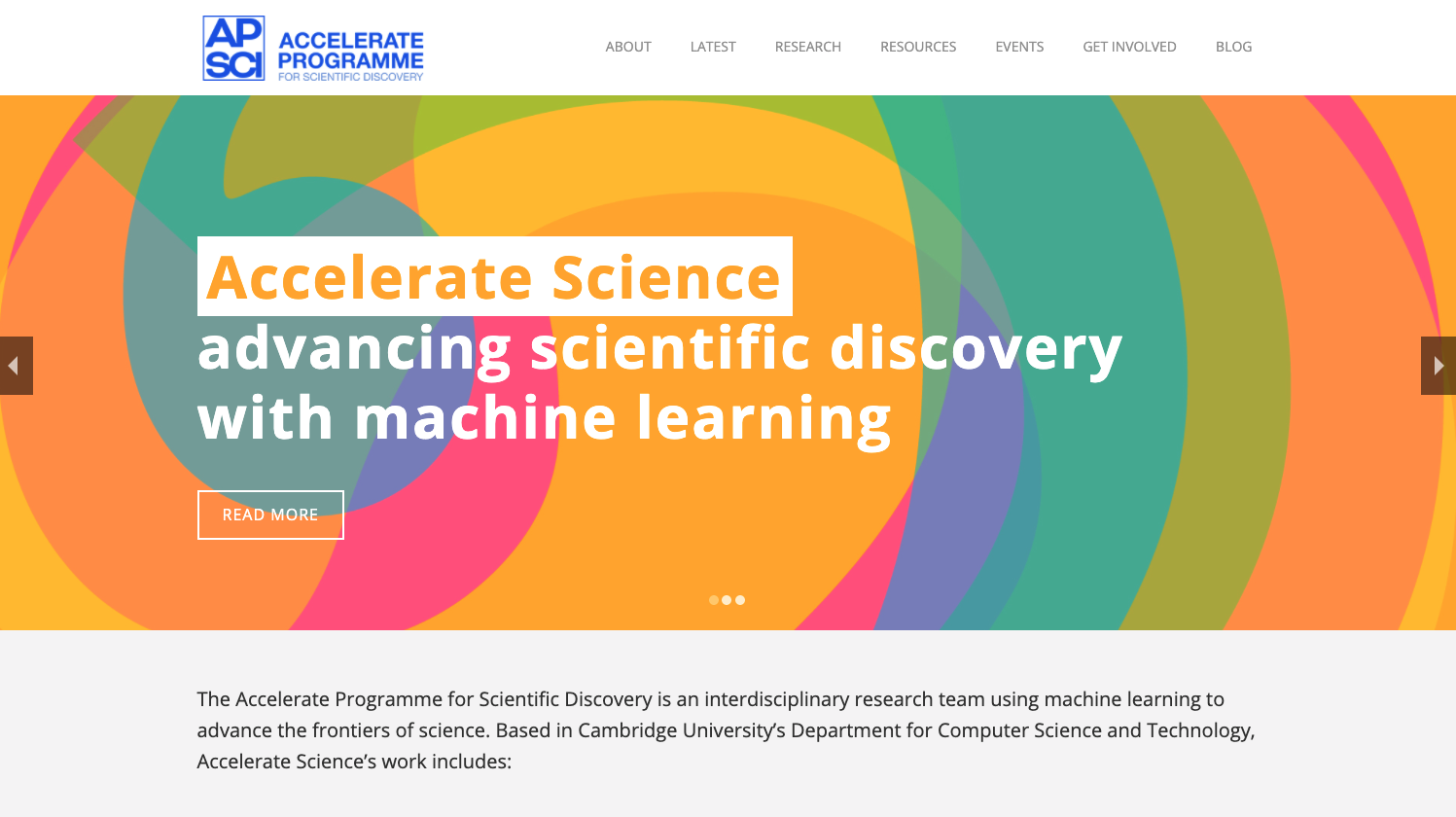
Figure: The Accelerate Programme for Scientific Discovery covers research, education and training, engagement. Our aim is to bring about a step change in scientific discovery through AI. http://acceleratescience.github.io
We’re now in a new phase of the development of computing, with rapid advances in machine learning. But we see some of the same issues – researchers across disciplines hope to make use of machine learning, but need access to skills and tools to do so, while the field machine learning itself will need to develop new methods to tackle some complex, ‘real world’ problems.
It is with these challenges in mind that the Computer Lab has started the Accelerate Programme for Scientific Discovery. This new Programme is seeking to support researchers across the University to develop the skills they need to be able to use machine learning and AI in their research.
To do this, the Programme is developing three areas of activity:
Research: we’re developing a research agenda that develops and applies cutting edge machine learning methods to scientific challenges, with three Accelerate Research fellows working directly on issues relating to computational biology, psychiatry, and string theory. While we’re concentrating on STEM subjects for now, in the longer term our ambition is to build links with the social sciences and humanities.
Teaching and learning: building on the teaching activities already delivered through University courses, we’re creating a pipeline of learning opportunities to help PhD students and postdocs better understand how to use data science and machine learning in their work. Our programme with Spark is one element of this, and we’ll be announcing further activities soon.
Engagement: we hope that Accelerate will help build a community of researchers working across the University at the interface on machine learning and the sciences, helping to share best practice and new methods, and support each other in advancing their research. Over the coming years, we’ll be running a variety of events and activities in support of this, and would welcome your ideas about what might be most useful.
Sarah Morgan is one of our fellows, she’ll tell us about how she makes use of the machine’s capabilities in improving understanding and diagnostics of schizophrenia.
Other examples of this form of work include our collaboration with Data Science Africa, which focusses on empowering individuals with solutions for solving challenges that emerge in the African context.
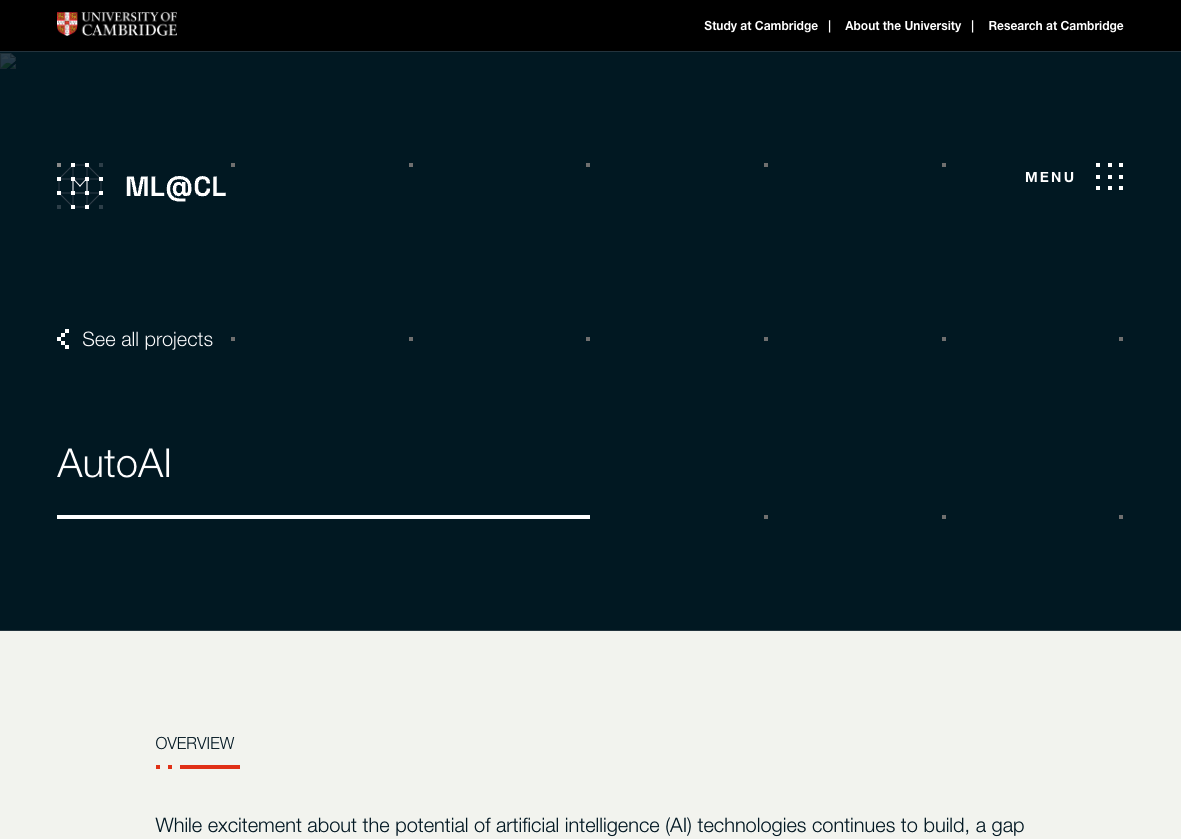
Figure: Address challenges in the way that complex software systems involving machine learning components are constructed to deal with the challenge of Intellectual Debt.
Challenge
It used to be true that computers only did what we programmed them to do, but today AI systems are learning from our data. This introduces new problems in how these systems respond to their environment.
We need to better monitor how data is influencing decision making and take corrective action as required.
Aim
Our aim is to scale our ability to deploy safe and reliable AI solutions. Our technical approach is to do this through data-oriented software engineering practices and deep system emulation. We will do this through a significant extension of the notion of Automated ML (AutoML) to Automated AI (AutoAI), this relies on a shift from Bayesian Optimisation to Bayesian System Optimisation. The project will develop a toolkit for automating the deployment, maintenance and monitoring of artificial intelligence systems.
Turing AI Fellowship
From December 2019 I begin a Senior AI Fellowship at the Turing Institute funded by the Office for AI to investigate the consequences of deploying complex AI systems.
The notion relates from the “Promise of AI”: it promises to be the first generation of automation technology that will adapt to us, rather than us adapting to it. The premise of the project is that this promise will remain unfulfilled with current approaches to systems design and deployment.
A second intervention is dealing with the complexity of the software systems that underpin modern AI solutions. Even if two individuals, say African masters students, who are technically capable and have an interesting idea, deploy their idea. One challenge they face is the operational load in maintaining and explaining their software systems. The challenge of maintaining is known as intellectual debt (Sculley et al., 2015), the problem of explaining is known as intellectual debt.
The AutoAI project, sponsored by an ATI Senior AI Fellowship addresses this challenge.

Figure: The Data Trusts Initiative (http://datatrusts.uk) hosts blog posts helping build understanding of data trusts and supports research and pilot projects.
The third intervention goes direct to the source of the machine’s power. What we are seeing is an emergent digital oligarchy based on the power that comes with aggregation of data. Data Trusts are form of data intermediary designed to reutrn the power associated with this data accumulation to the originators of the data, that is us.
{
Personal Data Trusts
The machine learning solutions we are dependent on to drive automated decision making are dependent on data. But with regard to personal data there are important issues of privacy. Data sharing brings benefits, but also exposes our digital selves. From the use of social media data for targeted advertising to influence us, to the use of genetic data to identify criminals, or natural family members. Control of our virtual selves maps on to control of our actual selves.
The fuedal system that is implied by current data protection legislation has signficant power asymmetries at its heart, in that the data controller has a duty of care over the data subject, but the data subject may only discover failings in that duty of care when it’s too late. Data controllers also may have conflicting motivations, and often their primary motivation is not towards the data-subject, but that is a consideration in their wider agenda.
Personal Data Trusts (Delacroix and Lawrence, 2018; Edwards, 2004; Lawrence, 2016) are a potential solution to this problem. Inspired by land societies that formed in the 19th century to bring democratic representation to the growing middle classes. A land society was a mutual organisation where resources were pooled for the common good.
A Personal Data Trust would be a legal entity where the trustees responsibility was entirely to the members of the trust. So the motivation of the data-controllers is aligned only with the data-subjects. How data is handled would be subject to the terms under which the trust was convened. The success of an individual trust would be contingent on it satisfying its members with appropriate balancing of individual privacy with the benefits of data sharing.
Formation of Data Trusts became the number one recommendation of the Hall-Presenti report on AI, but unfortunately, the term was confounded with more general approaches to data sharing that don’t necessarily involve fiduciary responsibilities or personal data rights. It seems clear that we need to better characterise the data sharing landscape as well as propose mechanisms for tackling specific issues in data sharing.
It feels important to have a diversity of approaches, and yet it feels important that any individual trust would be large enough to be taken seriously in representing the views of its members in wider negotiations.
{kind=link}

Figure: Data Trusts were the first recommendation of the Hall-Presenti Report. Unfortunately, since then the role of data trusts vs other data sharing mechanisms in the UK has been somewhat confused.
See Guardian articles on Guardian article on Digital Oligarchies and Guardian article on Information Feudalism.
Data Trusts Initiative
The Data Trusts Initiative, funded by the Patrick J. McGovern Foundation is supporting three pilot projects that consider how bottom-up empowerment can redress the imbalance associated with the digital oligarchy.
Figure: The Data Trusts Initiative (http://datatrusts.uk) hosts blog posts helping build understanding of data trusts and supports research and pilot projects.
Figure: AI@Cam is a Flagship Programme that supports AI research across the University.
Finally, we are working across the University to empower the diversity ofexpertise and capability we have to focus on these broad societal problems. We will shortly be launching AI@Cam, with a landscaping document, outlining these challenges and exploring different strategies the University has to address them.
Conclusions
Our particular constraints, in terms of our bandwidth, means that our intelligence is embodied, but AI is not embodied. We tend to anthropomorphasise other intelligences, and we view other humans as simple, despite their complexities and nuanced intelligence.
When it comes to consequential decision making, there are two properties we might like it to have. The \(p\) properties consider clarity of decision making procedure, and the \(n\) properties consider the nuance of the decision making. These properties are in tension.
The marvelous resolution of these tensions that humans have evolved relies on the fact that despite the fact that other humans are complex and nuanced, we relate to one another. This means that we can have simple decision making processes that exhibit nuance through human intervention. The machine can’t emulate this as they operate in ways that are very different to humans and difficult for us to relate to.
Where interactions with AI are ocurring, we tend to be the tool of the AI, because it can exploit us through our data. We need to correct this, and change the situation where we are in control of the AI.
We’ve briefly reviewed three interventions at the University of Cambridge which focus on
- The Accelerate Programme: Working with domain experts to improve the design and use of AI systems.
- AutoAI: Developing better technologies for the control, explanation and maintenance of AI systems.
- Data Trusts Initiative: piloting data intermediaries that give users back control of their data.
Finally, we introduced the AI@Cam intiative to encourage interdisciplinary debate about these issues building on the University’s strengths across all these areas.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com
References
the challenge of understanding what information pertains to is known as knowledge representation.↩︎