Harnessing Data Science for Africa’s Socio-Economic Development
Henry Ford’s Faster Horse


Figure: A 1925 Ford Model T built at Henry Ford’s Highland Park Plant in Dearborn, Michigan. This example now resides in Australia, owned by the founder of FordModelT.net. From https://commons.wikimedia.org/wiki/File:1925_Ford_Model_T_touring.jpg
{kind=link}
It’s said that Henry Ford’s customers wanted a “a faster horse”. If Henry Ford was selling us artificial intelligence today, what would the customer call for, “a smarter human”? That’s certainly the picture of machine intelligence we find in science fiction narratives, but the reality of what we’ve developed is much more mundane.
Car engines produce prodigious power from petrol. Machine intelligences deliver decisions derived from data. In both cases the scale of consumption enables a speed of operation that is far beyond the capabilities of their natural counterparts. Unfettered energy consumption has consequences in the form of climate change. Does unbridled data consumption also have consequences for us?
If we devolve decision making to machines, we depend on those machines to accommodate our needs. If we don’t understand how those machines operate, we lose control over our destiny. Our mistake has been to see machine intelligence as a reflection of our intelligence. We cannot understand the smarter human without understanding the human. To understand the machine, we need to better understand ourselves.
In Greek mythology, Panacea was the goddess of the universal remedy. One consequence of the pervasive potential of AI is that it is positioned, like Panacea, as the purveyor of a universal solution. Whether it is overcoming industry’s productivity challenges, or as a salve for strained public sector services, or a remedy for pressing global challenges in sustainable development, AI is presented as an elixir to resolve society’s problems.
In practice, translation of AI technology into practical benefit is not simple. Moreover, a growing body of evidence shows that risks and benefits from AI innovations are unevenly distributed across society.
When carelessly deployed, AI risks exacerbating existing social and economic inequalities.
Evolved Relationship with Information
The high bandwidth of computers has resulted in a close relationship between the computer and data. Large amounts of information can flow between the two. The degree to which the computer is mediating our relationship with data means that we should consider it an intermediary.
Originally our low bandwidth relationship with data was affected by two characteristics. Firstly, our tendency to over-interpret driven by our need to extract as much knowledge from our low bandwidth information channel as possible. Secondly, by our improved understanding of the domain of mathematical statistics and how our cognitive biases can mislead us.
With this new set up there is a potential for assimilating far more information via the computer, but the computer can present this to us in various ways. If its motives are not aligned with ours then it can misrepresent the information. This needn’t be nefarious it can be simply because of the computer pursuing a different objective from us. For example, if the computer is aiming to maximize our interaction time that may be a different objective from ours which may be to summarize information in a representative manner in the shortest possible length of time.
For example, for me, it was a common experience to pick up my telephone with the intention of checking when my next appointment was, but to soon find myself distracted by another application on the phone and end up reading something on the internet. By the time I’d finished reading, I would often have forgotten the reason I picked up my phone in the first place.
There are great benefits to be had from the huge amount of information we can unlock from this evolved relationship between us and data. In biology, large scale data sharing has been driven by a revolution in genomic, transcriptomic and epigenomic measurement. The improved inferences that can be drawn through summarizing data by computer have fundamentally changed the nature of biological science, now this phenomenon is also influencing us in our daily lives as data measured by happenstance is increasingly used to characterize us.
Better mediation of this flow requires a better understanding of human-computer interaction. This in turn involves understanding our own intelligence better, what its cognitive biases are and how these might mislead us.
For further thoughts see Guardian article on marketing in the internet era from 2015.
You can also check my blog post on System Zero. This was also written in 2015.
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
With new capabilities becoming available through very large generational AI models, we can imagine different interfaces with that information, but the potential for manipulation is if anything even greater.
Figure: New capabilities in language generation offer the tantalising possibility for a better interface between the machine and it’s understanding of data but characterising that communication channel remains a major challenge.
Revolution
Arguably the information revolution we are experiencing is unprecedented in history. But changes in the way we share information have a long history. Over 5,000 years ago in the city of Uruk, on the banks of the Euphrates, communities which relied on the water to irrigate their corps developed an approach to recording transactions in clay. Eventually the system of recording system became sophisticated enough that their oral histories could be recorded in the form of the first epic: Gilgamesh.

Figure: Chicago Stone, side 2, recording sale of a number of fields, probably from Isin, Early Dynastic Period, c. 2600 BC, black basalt
It was initially develoepd for people as a recordd of who owed what to whom, expanding individuals’ capacity to remember. But over a five hundred year period writing evolved to become a tool for literature as well. More pithily put, writing was invented by accountants not poets (see e.g. this piece by Tim Harford has highlighted.
In some respects today’s revolution is different, because it involves also the creation of stories as well as their curation. But in some fundamental ways we can see what we have produced as another tool for us in the information revolution.
The Future of Professions

Figure: The Future of Professions (Susskind and Susskind, 2015) is a 2015 book focussed on how the next wave of technology revolution is going to effect the professions.
A question, to what extent do these challenges vary for the African continent? Many of the skills that we are considering will be undermined by ChatGPT aand equivalent technologies are actually skills that are lacking on the continent, so does this provide an opportunity for DSA?
There is potential for both explicit and implicit discrimination on the basis of race, religion, sexuality or health status. All of these are prohibited under European law but can pass unawares or be implicit.
The GDPR is the General Data Protection Regulation, but a better name for it would simply be Good Data Practice Rules. It covers how to deal with discrimination which has a consequential effect on the individual. For example, entrance to university, access to loans or insurance. But the new phenomenon is dealing with a series of inconsequential decisions that taken together have a consequential effect.

Figure: A woman tends her house in a village in Uganda.
Statistics as a community is also focused on the single consequential effect of an analysis (efficacy of drugs, or distribution of Mosquito nets). Associated with happenstance data is happenstance decision making.
These algorithms behind these decisions are developed in a particular context. The so-called Silicon Valley bubble. But they are deployed across the world. To address this, a key challenge is capacity building in contexts which are remote from the Western norm.
Coin Pusher
Disruption of society is like a coin pusher, it’s those who are already on the edge who are most likely to be effected by disruption.

Figure: A coin pusher is a game where coins are dropped into th etop of the machine, and they disrupt those on the existing steps. With any coin drop, many coins move, but it is those on the edge, who are often only indirectly effected, but also most traumatically effected by the change.
One danger of the current hype around ChatGPT is that we are overly focussing on the fact that it seems to have significant effect on professional jobs, people are naturally asking the question “what does it do for my role?”. No doubt, there will be disruption, but the coin pusher hypothesis suggests that that disruption will likely involve movement on the same step. However it is those on the edge already, who are often not working directly in the information economy, who often have less of a voice in the policy conversation who are likely to be most disrupted.
Royal Society Report

Figure: The Royal Society report on Machine Learning was released on 25th April 2017
A useful reference for state of the art in machine learning is the UK Royal Society Report, Machine Learning: Power and Promise of Computers that Learn by Example.
Public Research

Figure: The Royal Society comissioned public research from Mori as part of the machine learning review.

Figure: One of the questions focussed on machine learning applications.

Figure: The public were broadly supportive of a range of application areas.

Figure: But they failed to see the point in AI’s that could produce poetry.
Mercutio
It’s ironic that despite the public focus on transport, health, cities, crime and their confusion as to why we might want AI to do art, one area where significant progress has been made is on AIs that can create literature.
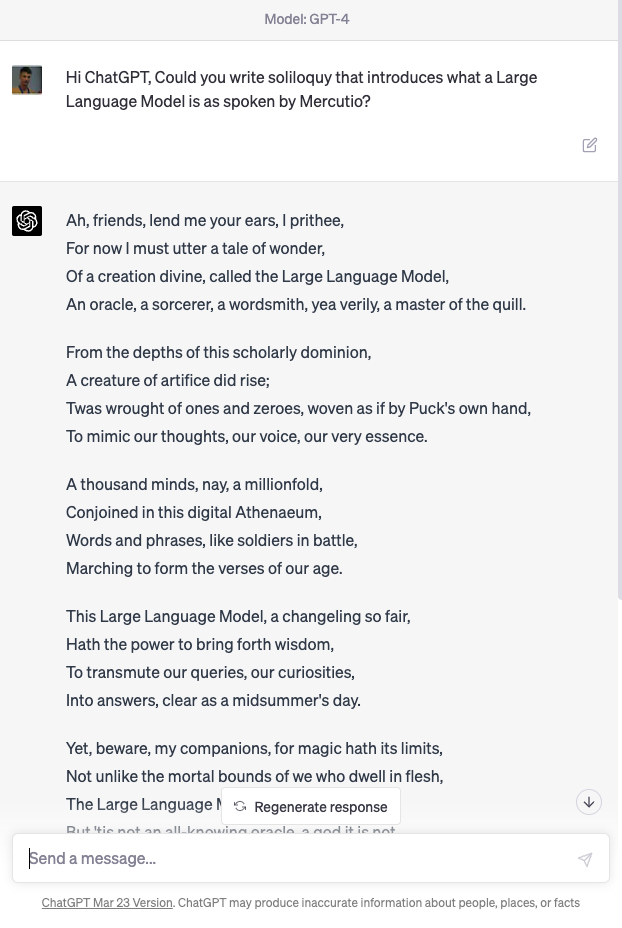
Figure: Despite the public’s desire to see challenges in health, finance, transport, crime solved by machine learning and their skepticism around poetry, one of the problems we have solved seems to be poetry.
User: Hi ChatGPT, Could you write soliloquy that introduces what a Large Language Model is as spoken by Mercutio?
Machine: Ah, friends, lend me your ears, I prithee, For now I must utter a tale of wonder, Of a creation divine, called the Large Language Model, An oracle, a sorcerer, a wordsmith, yea verily, a master of the quill.
From the depths of this scholarly dominion, A creature of artifice did rise; Twas wrought of ones and zeroes, woven as if by Puck’s own hand, To mimic our thoughts, our voice, our very essence.
A thousand minds, nay, a millionfold, Conjoined in this digital Athenaeum, Words and phrases, like soldiers in battle, Marching to form the verses of our age.
This Large Language Model, a changeling so fair, Hath the power to bring forth wisdom, To transmute our queries, our curiosities, Into answers, clear as a midsummer’s day.
Yet, beware, my companions, for magic hath its limits, Not unlike the mortal bounds of we who dwell in flesh, The Large Language Model hath its strengths, But ’tis not an all-knowing oracle, a god it is not.
As Mercutio, your humble servant, doth stand before thee, I marvel at the art and science that hath brought forth this wondrous creation, This Large Language Model, a testament to man’s yearning, To comprehend the world and make meaning of the great tapestry of existence.
In faith, dear friends, let us embrace the magic and beauty of this digital bard, And mayhaps, by its grace, we shall glean some wisdom, As we wander together, hand in hand, Through this boundless realm of knowledge and wonder.
ChatGPT transcript, 14th April 2023.
\(p\)-Fairness and \(n\)-Fairness
Figure: We seem to have two different aspects to fairness, which in practice can be in tension.
We’ve outlined \(n\)-fairness and \(p\)-fairness. By \(n\)-fairness we mean the sort of considerations that are associated with substantive equality of opportunity vs formal equality of opportunity. Formal equality of community is related to \(p\)-fairness. This is sometimes called procedural fairness and we might think of it as a performative form of fairness. It’s about clarity of rules, for example as applied in sport. \(n\)-Fairness is more nuanced. It’s a reflection of society’s normative judgment about how individuals may have been disadvantaged, e.g. due to their upbringing.
The important point here is that these forms of fairness are in tension. Good procedural fairness needs to be clear and understandable. It should be clear to everyone what the rules are, they shouldn’t be obscured by jargon or overly subtle concepts. \(p\)-Fairness should not be easily undermined by adversaries, it should be difficult to “cheat” good \(p\)-fairness. However, \(n\)-fairness requires nuance, understanding of the human condition, where we came from and how different individuals in our society have been advantaged or disadvantaged in their upbringing and their access to opportunity.
Pure \(n\)-fairness and pure \(p\)-fairness both have the feeling of dystopias. In practice, any decision making system needs to balance the two. The correct point of operation will depend on the context of the decision. Consider fair rules of a game of football, against fair distribution of social benefit. It is unlikely that there is ever an objectively correct balance between the two for any given context. Different individuals will favour \(p\) vs \(n\) according to their personal values.
Given the tension between the two forms of fairness, with \(p\) fairness requiring simple rules that are understandable by all, and \(n\) fairness requiring nuance and subtlety, how do we resolve this tension in practice?
Normally in human systems, significant decisions involve trained professionals. For example, judges, or accountants or doctors.
Training a professional involves lifting their “reflexive” response to a situation with “reflective” thinking about the consequences of their decision that rely not just on the professional’s expertise, but also their knowledge of what it is to be a human.
This marvellous resolution exploits the fact that while humans are increadibly complicated nuanced entities, other humans have an intuitive ability to understand their motivations and values. So the human is a complex entity that seems simple to other humans.
A Question of Trust
In Baroness Onora O’Neill’s Reeith Lectures from 2002, she raises the challenge of trust. There are many aspects to her arcuments, but one of the key points she makes is that we cannot trust without the notion of duty. O’Neill is bemoaning the substitution of duty with process. The idea is that processes and transparency are supposed to hold us to account by measuring outcomes. But these processes themselves overwhelm decision makers and undermine their professional duty to deliver the right outcome.

Figure: A Question of Trust by Onora O’Neil which examines the nature of trust and its role in society.
Again Univesities are to treat each applicant fairly on the basis of ability and promise, but they are supposed also to admit a socially more representative intake.
There’s no guarantee that the process meets the target.
Onora O’Neill A Question of Trust: Called to Account Reith Lectures 2002 O’Neill (2002)]
O’Neill is speaking in 2002, in the early days of the internet and before social media. Much of her thoughts are even more relevant for today than they were when she spoke. This is because the increased availability of information and machine driven decision-making makes the mistaken premise, that process is an adequate substitute for duty, more apparently plausible. But this undermines what O’Neill calls “intelligent accountability”, which is not accounting by the numbers, but through professional education and institutional safeguards.
NACA Langley

Figure: 1945 photo of the NACA test pilots, from left Mel Gough, Herb Hoover, Jack Reeder, Stefan Cavallo and Bill Gray (photo NASA, NACA LMAL 42612)
The NACA Langley Field proving ground tested US aircraft. Bob Gilruth worked on the flying qualities of aircraft. One of his collaborators suggested that
Hawker Hurricane airplane. A heavily armed fighter airplane noted for its role in the Battle of Britain, the Hurricane’s flying qualities were found to be generally satisfactory. The most notable deficiencies were heavy aileron forces at high speeds and large friction in the controls.
W. Hewitt Phillips1
and
Supermarine Spitfire airplane. A high-performance fighter noted for its role in the Battle of Britain and throughout WW II, the Spitfire had desirably light elevator control forces in maneuvers and near neutral longitudinal stability. Its greatest deficiency from the combat standpoint was heavy aileron forces and sluggish roll response at high speeds.
W. Hewitt Phillips2
Gilruth went beyond the reports of feel to characterise how the plane should respond to different inputs on the control stick. In other words he quantified that feel of the plane.
AI Proving Grounds
We need mechanisms to rapidly understand the capabilities of these new tools, what is the potential of the technology, and what are the pitfalls? With this in mind we can build a societal AI capability that means understanding is pervasive.
Innovating to serve science and society requires a pipeline of interventions. As well as advances in the technical capabilities of AI technologies, engineering knowhow is required to safely deploy and monitor those solutions in practice. Regulatory frameworks need to adapt to ensure trustworthy use of these technologies. Aligning technology development with public interests demands effective stakeholder engagement to bring diverse voices and expertise into technology design.
Building this pipeline will take coordination across research, engineering, policy and practice. It also requires action to address the digital divides that influence who benefits from AI advances. These include digital divides within the socioeconomic strata that need to be overcome – AI must not exacerbate existing equalities or create new ones. In addressing these challenges, we can be hindered by divides that exist between traditional academic disciplines. We need to develop common understanding of the problems and a shared knowledge of possible solutions.
Making AI equitable
Data Science Africa
Figure: Data Science Africa http://datascienceafrica.org is a ground up initiative for capacity building around data science, machine learning and artificial intelligence on the African continent.
Figure: Data Science Africa meetings held up to October 2021.
Data Science Africa is a bottom up initiative for capacity building in data science, machine learning and artificial intelligence on the African continent.
As of May 2023 there have been eleven workshops and schools, located in seven different countries: Nyeri, Kenya (twice); Kampala, Uganda; Arusha, Tanzania; Abuja, Nigeria; Addis Ababa, Ethiopia; Accra, Ghana; Kampala, Uganda and Kimberley, South Africa (virtual), and in Kigali, Rwanda.
The main notion is end-to-end data science. For example, going from data collection in the farmer’s field to decision making in the Ministry of Agriculture. Or going from malaria disease counts in health centers to medicine distribution.
The philosophy is laid out in (Lawrence, 2015). The key idea is that the modern information infrastructure presents new solutions to old problems. Modes of development change because less capital investment is required to take advantage of this infrastructure. The philosophy is that local capacity building is the right way to leverage these challenges in addressing data science problems in the African context.
Data Science Africa is now a non-govermental organization registered in Kenya. The organising board of the meeting is entirely made up of scientists and academics based on the African continent.

Figure: The lack of existing physical infrastructure on the African continent makes it a particularly interesting environment for deploying solutions based on the information infrastructure. The idea is explored more in this Guardian op-ed on Guardian article on How African can benefit from the data revolution.
Guardian article on Data Science Africa
Thanks!
For more information on these subjects and more you might want to check the following resources.
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com