How Do We Cope with Rapid Change Like AI/ML?
Abstract
Machine learning solutions, in particular those based on deep learning methods, form an underpinning of the current revolution in “artificial intelligence” that has dominated popular press headlines and is having a significant influence on the wider tech agenda. In this talk I will give an overview of where we are now with machine learning solutions, and what challenges we face both in the near and far future. These include practical application of existing algorithms in the face of the need to explain decision making, mechanisms for improving the quality and availability of data, dealing with large unstructured datasets.
Revolution
Arguably the information revolution we are experiencing is unprecedented in history. But changes in the way we share information have a long history. Over 5,000 years ago in the city of Uruk, on the banks of the Euphrates, communities which relied on the water to irrigate their corps developed an approach to recording transactions in clay. Eventually the system of recording system became sophisticated enough that their oral histories could be recorded in the form of the first epic: Gilgamesh.
See Lawrence (2024) cuneiform p. 337, 360, 390.


Figure: Chicago Stone, side 2, recording sale of a number of fields, probably from Isin, Early Dynastic Period, c. 2600 BC, black basalt
It was initially developed for people as a record of who owed what to whom, expanding individuals’ capacity to remember. But over a five hundred year period writing evolved to become a tool for literature as well. More pithily put, writing was invented by accountants not poets (see e.g. this piece by Tim Harford).
In some respects today’s revolution is different, because it involves also the creation of stories as well as their curation. But in some fundamental ways we can see what we have produced as another tool for us in the information revolution.
Coin Pusher
Disruption of society is like a coin pusher, it’s those who are already on the edge who are most likely to be effected by disruption.

Figure: A coin pusher is a game where coins are dropped into th etop of the machine, and they disrupt those on the existing steps. With any coin drop, many coins move, but it is those on the edge, who are often only indirectly effected, but also most traumatically effected by the change.
One danger of the current hype around generative AI is that we are overly focussing on the fact that it seems to have significant effect on professional jobs, people are naturally asking the question “what does it do for my role?”. No doubt, there will be disruption, but the coin pusher hypothesis suggests that that disruption will likely involve movement on the same step. However it is those on the edge already, who are often not working directly in the information economy, who often have less of a voice in the policy conversation who are likely to be most disrupted.
Henry Ford’s Faster Horse

Figure: A 1925 Ford Model T built at Henry Ford’s Highland Park Plant in Dearborn, Michigan. This example now resides in Australia, owned by the founder of FordModelT.net. From https://commons.wikimedia.org/wiki/File:1925_Ford_Model_T_touring.jpg
It’s said that Henry Ford’s customers wanted a “a faster horse”. If Henry Ford was selling us artificial intelligence today, what would the customer call for, “a smarter human”? That’s certainly the picture of machine intelligence we find in science fiction narratives, but the reality of what we’ve developed is much more mundane.
Car engines produce prodigious power from petrol. Machine intelligences deliver decisions derived from data. In both cases the scale of consumption enables a speed of operation that is far beyond the capabilities of their natural counterparts. Unfettered energy consumption has consequences in the form of climate change. Does unbridled data consumption also have consequences for us?
If we devolve decision making to machines, we depend on those machines to accommodate our needs. If we don’t understand how those machines operate, we lose control over our destiny. Our mistake has been to see machine intelligence as a reflection of our intelligence. We cannot understand the smarter human without understanding the human. To understand the machine, we need to better understand ourselves.
Embodiment Factors
| bits/min | billions | 2,000 |
|
billion calculations/s |
~100 | a billion |
| embodiment | 20 minutes | 5 billion years |
Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, it is a matter of thousands of millions of years. See also “Living Together: Mind and Machine Intelligence” Lawrence (2017)
There is a fundamental limit placed on our intelligence based on our ability to communicate. Claude Shannon founded the field of information theory. The clever part of this theory is it allows us to separate our measurement of information from what the information pertains to.1
Shannon measured information in bits. One bit of information is the amount of information I pass to you when I give you the result of a coin toss. Shannon was also interested in the amount of information in the English language. He estimated that on average a word in the English language contains 12 bits of information.
Given typical speaking rates, that gives us an estimate of our ability to communicate of around 100 bits per second (Reed and Durlach, 1998). Computers on the other hand can communicate much more rapidly. Current wired network speeds are around a billion bits per second, ten million times faster.
When it comes to compute though, our best estimates indicate our computers are slower. A typical modern computer can process make around 100 billion floating-point operations per second, each floating-point operation involves a 64 bit number. So the computer is processing around 6,400 billion bits per second.
It’s difficult to get similar estimates for humans, but by some estimates the amount of compute we would require to simulate a human brain is equivalent to that in the UK’s fastest computer (Ananthanarayanan et al., 2009), the MET office machine in Exeter, which in 2018 ranked as the 11th fastest computer in the world. That machine simulates the world’s weather each morning, and then simulates the world’s climate in the afternoon. It is a 16-petaflop machine, processing around 1,000 trillion bits per second.
See Lawrence (2024) embodiment factor p. 13, 29, 35, 79, 87, 105, 197, 216-217, 249, 269, 353, 369.
Bandwidth Constrained Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Embodiment factors imply that, in our communication between humans, what is not said is, perhaps, more important than what is said. To communicate with each other we need to have a model of who each of us are.
To aid this, in society, we are required to perform roles. Whether as a parent, a teacher, an employee or a boss. Each of these roles requires that we conform to certain standards of behaviour to facilitate communication between ourselves.
Control of self is vitally important to these communications.
The high availability of data available to humans undermines human-to-human communication channels by providing new routes to undermining our control of self.
The consequences between this mismatch of power and delivery are to be seen all around us. Because, just as driving an F1 car with bicycle wheels would be a fine art, so is the process of communication between humans.
If I have a thought and I wish to communicate it, I first need to have a model of what you think. I should think before I speak. When I speak, you may react. You have a model of who I am and what I was trying to say, and why I chose to say what I said. Now we begin this dance, where we are each trying to better understand each other and what we are saying. When it works, it is beautiful, but when mis-deployed, just like a badly driven F1 car, there is a horrible crash, an argument.
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
Public Dialogue on AI in Public Services

Figure: In September 2024, ai@cam convened a series of public dialogues to understand perspectives on the role of AI in delivering policy agendas.
In September 2024, ai@cam convened a series of public dialogues to understand perspectives on the role of AI in delivering priority policy agendas. Through workshops in Cambridge and Liverpool, 40 members of the public shared their views on how AI could support delivery of four key government missions around health, crime and policing, education, and energy and net zero.
The dialogue revealed a pragmatic public view that sees clear benefits from AI in reducing administrative burdens and improving service efficiency, while emphasizing the importance of maintaining human-centered services and establishing robust governance frameworks.
Key participant quotes illustrate this balanced perspective:
“It must be so difficult for GPs to keep track of how medication reacts with other medication on an individual basis. If there’s some database that shows all that, then it can only help, can’t it?”
Public Participant, Liverpool pg 10 ai@cam and Hopkins Van Mil (2024)
“I think a lot of the ideas need to be about AI being like a co-pilot to someone. I think it has to be that. So not taking the human away.”
Public Participant, Liverpool pg 15 ai@cam and Hopkins Van Mil (2024)
AI in Healthcare: Public Perspectives
In healthcare discussions, participants saw clear opportunities for AI to support NHS administration and improve service delivery, while expressing caution about AI involvement in direct patient care and diagnosis.
Key aspirations include:
- Reducing administrative burden on clinicians
- Supporting early diagnosis and prevention
- Improving research and drug development
- Better management of complex conditions
Illustrative quotes show the nuanced views:
“My wife [an NHS nurse] says that the paperwork side takes longer than the actual care.”
Public Participant, Liverpool pg 9 ai@cam and Hopkins Van Mil (2024)
“I wouldn’t just want to rely on the technology for something big like that, because obviously it’s a lifechanging situation.”
Public Participant, Cambridge pg 10 ai@cam and Hopkins Van Mil (2024)
Concerns focused particularly on maintaining human involvement in healthcare decisions and protecting patient privacy.
AI in Education: Public Perspectives
In education discussions, participants strongly supported AI’s potential to reduce teacher workload but expressed significant concerns about screen time and the importance of human interaction in learning.
A clear distinction emerged between support for AI in administrative tasks versus direct teaching roles. Participants emphasized that core aspects of education require human qualities that AI cannot replicate.
Key quotes illustrate these views:
“Education isn’t just about learning, it’s about preparing children for life, and you don’t do all of that in front of a screen.”
Public Participant, Cambridge ai@cam and Hopkins Van Mil (2024) pg 18
“Kids with ADHD or autism might prefer to interact with an iPad than they would a person, it could lighten the load for them.”
Public Participant, Liverpool ai@cam and Hopkins Van Mil (2024) pg 17
The dialogue revealed particular concern about the risk of AI increasing screen time and reducing social interaction, while acknowledging potential benefits for personalized learning support.
AI in Crime and Policing: Public Perspectives
Discussions around crime and policing revealed complex attitudes toward AI use, with support for analytical applications but strong concerns about surveillance and automated decision-making.
Participants emphasized that existing trust issues in policing need to be addressed before expanding AI use. They saw potential benefits in areas like crime pattern analysis but worried about bias and privacy implications.
Key quotes reflect these concerns:
“Trust in the police has been undermined by failures in vetting and appalling misconduct of some officers. I think AI can help this, because the fact is that we, as a society, we know how to compile information.”
Public Participant, Liverpool pg 14 ai@cam and Hopkins Van Mil (2024)
“I’m brown skinned and my mouth will move a bit more or I’m constantly fiddling with my foot… I’ve got ADHD. If facial recognition would see my brown skin, and then I’m moving differently to other people, will they see me as a terrorist?”
Public Participant, Liverpool pg 15 ai@cam and Hopkins Van Mil (2024)
The dialogue highlighted strong public desire for transparency and accountability in how AI is used in policing, with particular emphasis on preventing discriminatory outcomes.
AI in Energy and Net Zero: Public Perspectives
The energy and net zero discussions revealed support for AI’s potential to optimize energy systems while raising questions about access and affordability.
Participants saw clear benefits in using AI to improve energy efficiency and grid management, but worried about creating new inequalities through technology access barriers.
Representative quotes include:
“Everybody being able to generate on their roofs or in their gardens, selling energy from your car back to the grid, power being thrown different ways at different times. You’ve got to be resilient and independent.”
Public Participant, Cambridge pg 20 ai@cam and Hopkins Van Mil (2024)
“Is the infrastructure not a more important aspect than putting in AI systems? Government for years now has known that we need that infrastructure, but it’s always been someone else’s problem, the next government to sort out.”
Public Participant, Liverpool pg 21 ai@cam and Hopkins Van Mil (2024)
A key theme was ensuring AI deployment in energy systems doesn’t distract from fundamental changes needed to address climate change or exacerbate existing inequalities.
Summary
The public dialogue revealed several cross-cutting themes about how AI should be deployed in public services:
- AI should enhance rather than replace human capabilities
- Strong governance frameworks need to be in place before deployment
- Public engagement and transparency are essential
- Benefits must be distributed fairly across society
- Human-centered service delivery must be maintained
A powerful theme throughout the dialogue was the desire to maintain human connection and expertise while leveraging AI’s capabilities to improve service efficiency and effectiveness. As one participant noted:
“We need to look at the causes, we need to do some more thinking and not just start using AI to plaster over them [societal issues].”
Public Participant, Cambridge pg 13 ai@cam and Hopkins Van Mil (2024)
Intellectual Debt
Figure: Jonathan Zittrain’s term to describe the challenges of explanation that come with AI is Intellectual Debt.
In the context of machine learning and complex systems, Jonathan Zittrain has coined the term “Intellectual Debt” to describe the challenge of understanding what you’ve created. In the ML@CL group we’ve been foucssing on developing the notion of a data-oriented architecture to deal with intellectual debt (Cabrera et al., 2023).
Zittrain points out the challenge around the lack of interpretability of individual ML models as the origin of intellectual debt. In machine learning I refer to work in this area as fairness, interpretability and transparency or FIT models. To an extent I agree with Zittrain, but if we understand the context and purpose of the decision making, I believe this is readily put right by the correct monitoring and retraining regime around the model. A concept I refer to as “progression testing”. Indeed, the best teams do this at the moment, and their failure to do it feels more of a matter of technical debt rather than intellectual, because arguably it is a maintenance task rather than an explanation task. After all, we have good statistical tools for interpreting individual models and decisions when we have the context. We can linearise around the operating point, we can perform counterfactual tests on the model. We can build empirical validation sets that explore fairness or accuracy of the model.
See Lawrence (2024) intellectual debt p. 84, 85, 349, 365.
Technical Debt
In computer systems the concept of technical debt has been surfaced by authors including Sculley et al. (2015). It is an important concept, that I think is somewhat hidden from the academic community, because it is a phenomenon that occurs when a computer software system is deployed.
Separation of Concerns
To construct such complex systems an approach known as “separation of concerns” has been developed. The idea is that you architect your system, which consists of a large-scale complex task, into a set of simpler tasks. Each of these tasks is separately implemented. This is known as the decomposition of the task.
This is where Jonathan Zittrain’s beautifully named term “intellectual debt” rises to the fore. Separation of concerns enables the construction of a complex system. But who is concerned with the overall system?
Technical debt is the inability to maintain your complex software system.
Intellectual debt is the inability to explain your software system.
It is right there in our approach to software engineering. “Separation of concerns” means no one is concerned about the overall system itself.
See Lawrence (2024) separation of concerns p. 84-85, 103, 109, 199, 284, 371.
See Lawrence (2024) intellectual debt p. 84-85, 349, 365, 376.
Technical Consequence
Classical systems design assumes that the system is decomposable. That we can decompose the complex decision making process into distinct and independently designable parts. The composition of these parts gives us our final system.
Nicolas Negroponte, the original founder of MIT’s media lab used to write a column called ‘bits and atoms’. This referred to the ability of information to effect movement of goods in the physical world. It is this interaction where machine learning technologies have the possibility to bring most benefit.
Artificial vs Natural Systems
Let’s take a step back from artificial intelligence, and consider natural intelligence. Or even more generally, let’s consider the contrast between an artificial system and an natural system.
The first criterion of a natural system is don’t fail, not because it has a will or intent of its own, but because if it had failed it wouldn’t have stood the test of time. It would no longer exist. In contrast, the mantra for artificial systems is to be more efficient. Our artificial systems are often given a single objective (in machine learning it is encoded in a mathematical function) and they aim to achieve that objective efficiently. These are different characteristics. Even if we wanted to incorporate don’t fail in some form, it is difficult to design for. To design for “don’t fail”, you have to consider every which way in which things can go wrong, if you miss one you fail. These cases are sometimes called corner cases. But in a real, uncontrolled environment, almost everything is a corner. It is difficult to imagine everything that can happen. This is why most of our automated systems operate in controlled environments, for example in a factory, or on a set of rails. Deploying automated systems in an uncontrolled environment requires a different approach to systems design. One that accounts for uncertainty in the environment and is robust to unforeseen circumstances.
The key difference between the two is that artificial systems are designed whereas natural systems are evolved.
Systems design is a major component of all Engineering disciplines. The details differ, but there is a single common theme: achieve your objective with the minimal use of resources to do the job. That provides efficiency. The engineering designer imagines a solution that requires the minimal set of components to achieve the result. A water pump has one route through the pump. That minimises the number of components needed. Redundancy is introduced only in safety critical systems, such as aircraft control systems. Students of biology, however, will be aware that in nature system-redundancy is everywhere. Redundancy leads to robustness. For an organism to survive in an evolving environment it must first be robust, then it can consider how to be efficient. Indeed, organisms that evolve to be too efficient at a particular task, like those that occupy a niche environment, are particularly vulnerable to extinction.
This notion is akin to the idea that only the best will survive, popularly encoded into an notion of evolution by Herbert Spencer’s quote.
Survival of the fittest
Herbet Spencer, 1864
Darwin himself never said “Survival of the Fittest” he talked about evolution by natural selection.
Non-survival of the non-fit
Evolution is better described as “non-survival of the non-fit”. You don’t have to be the fittest to survive, you just need to avoid the pitfalls of life. This is the first priority.
So it is with natural vs artificial intelligences. Any natural intelligence that was not robust to changes in its external environment would not survive, and therefore not reproduce. In contrast the artificial intelligences we produce are designed to be efficient at one specific task: control, computation, playing chess. They are fragile.
The first rule of a natural system is not be intelligent, it is “don’t be stupid”.
A mistake we make in the design of our systems is to equate fitness with the objective function, and to assume it is known and static. In practice, a real environment would have an evolving fitness function which would be unknown at any given time.
You can also read this blog post on Natural and Artificial Intelligence..
When we look at modern (digital) systems we see that in practice they fail very often. They face a challenge I think of as “Tyson’s maxim”: everyone has a plan until they get punched in the face. The designers are too often out of touch with the problem domain they are designing for. In the UK we’ve seen this challenge in the failures of the Post Office’s Horizon IT system and the abandonment of the National Programme for IT in the NHS at a cost of over £10 billion.
See Lawrence (2024) natural vs artificial systems p. 102-103.
Today’s Artificial Systems
The systems we produce today only work well when their tasks are pigeonholed, bounded in their scope. To achieve robust artificial intelligences we need new approaches to both the design of the individual components, and the combination of components within our AI systems. We need to deal with uncertainty and increase robustness. Today, it is easy to make a fool of an artificial intelligent agent, technology needs to address the challenge of the uncertain environment to achieve robust intelligences.
However, even if we find technological solutions for these challenges, it may be that the essence of human intelligence remains out of reach. It may be that the most quintessential element of our intelligence is defined by limitations. Limitations that computers have never experienced.
Claude Shannon developed the idea of information theory: the mathematics of information. He defined the amount of information we gain when we learn the result of a coin toss as a “bit” of information. A typical computer can communicate with another computer with a billion bits of information per second. Equivalent to a billion coin tosses per second. So how does this compare to us? Well, we can also estimate the amount of information in the English language. Shannon estimated that the average English word contains around 12 bits of information, twelve coin tosses, this means our verbal communication rates are only around the order of tens to hundreds of bits per second. Computers communicate tens of millions of times faster than us, in relative terms we are constrained to a bit of pocket money, while computers are corporate billionaires.
Our intelligence is not an island, it interacts, it infers the goals or intent of others, it predicts our own actions and how we will respond to others. We are social animals, and together we form a communal intelligence that characterises our species. For intelligence to be communal, our ideas to be shared somehow. We need to overcome this bandwidth limitation. The ability to share and collaborate, despite such constrained ability to communicate, characterises us. We must intellectually commune with one another. We cannot communicate all of what we saw, or the details of how we are about to react. Instead, we need a shared understanding. One that allows us to infer each other’s intent through context and a common sense of humanity. This characteristic is so strong that we anthropomorphise any object with which we interact. We apply moods to our cars, our cats, our environment. We seed the weather, volcanoes, trees with intent. Our desire to communicate renders us intellectually animist.
But our limited bandwidth doesn’t constrain us in our imaginations. Our consciousness, our sense of self, allows us to play out different scenarios. To internally observe how our self interacts with others. To learn from an internal simulation of the wider world. Empathy allows us to understand others’ likely responses without having the full detail of their mental state. We can infer their perspective. Self-awareness also allows us to understand our own likely future responses, to look forward in time, play out a scenario. Our brains contain a sense of self and a sense of others. Because our communication cannot be complete it is both contextual and cultural. When driving a car in the UK a flash of the lights at a junction concedes the right of way and invites another road user to proceed, whereas in Italy, the same flash asserts the right of way and warns another road user to remain.
Our main intelligence is our social intelligence, intelligence that is dedicated to overcoming our bandwidth limitation. We are individually complex, but as a society we rely on shared behaviours and oversimplification of our selves to remain coherent.
This nugget of our intelligence seems impossible for a computer to recreate directly, because it is a consequence of our evolutionary history. The computer, on the other hand, was born into a world of data, of high bandwidth communication. It was not there through the genesis of our minds and the cognitive compromises we made are lost to time. To be a truly human intelligence you need to have shared that journey with us.
Of course, none of this prevents us emulating those aspects of human intelligence that we observe in humans. We can form those emulations based on data. But even if an artificial intelligence can emulate humans to a high degree of accuracy it is a different type of intelligence. It is not constrained in the way human intelligence is. You may ask does it matter? Well, it is certainly important to us in many domains that there’s a human pulling the strings. Even in pure commerce it matters: the narrative story behind a product is often as important as the product itself. Handmade goods attract a price premium over factory made. Or alternatively in entertainment: people pay more to go to a live concert than for streaming music over the internet. People will also pay more to go to see a play in the theatre rather than a movie in the cinema.
In many respects I object to the use of the term Artificial Intelligence. It is poorly defined and means different things to different people. But there is one way in which the term is very accurate. The term artificial is appropriate in the same way we can describe a plastic plant as an artificial plant. It is often difficult to pick out from afar whether a plant is artificial or not. A plastic plant can fulfil many of the functions of a natural plant, and plastic plants are more convenient. But they can never replace natural plants.
In the same way, our natural intelligence is an evolved thing of beauty, a consequence of our limitations. Limitations which don’t apply to artificial intelligences and can only be emulated through artificial means. Our natural intelligence, just like our natural landscapes, should be treasured and can never be fully replaced.
NACA Langley
The feel of an aircraft is a repeated theme in the early years of flight. In response to perceived European advances in flight in the First World War, the US introduced the National Advisory Committee on Aeronautics. Under the committee a proving ground for aircraft was formed at Langley Field in Virginia. During the Second World War Bob Gilruth published a report on the flying qualities of aircraft that characterised how this feel could be translated into numbers.
See Lawrence (2024) Gilruth, Bob p. 190-192.

Figure: 1945 photo of the NACA test pilots, from left Mel Gough, Herb Hoover, Jack Reeder, Stefan Cavallo and Bill Gray (photo NASA, NACA LMAL 42612)
See Lawrence (2024) National Advisory Committee on Aeronautics (NACA) p. 163–168. One of Gilruth’s collaborators suggested that
Hawker Hurricane airplane. A heavily armed fighter airplane noted for its role in the Battle of Britain, the Hurricane’s flying qualities were found to be generally satisfactory. The most notable deficiencies were heavy aileron forces at high speeds and large friction in the controls.
W. Hewitt Phillips2
and
Supermarine Spitfire airplane. A high-performance fighter noted for its role in the Battle of Britain and throughout WW II, the Spitfire had desirably light elevator control forces in maneuvers and near neutral longitudinal stability. Its greatest deficiency from the combat standpoint was heavy aileron forces and sluggish roll response at high speeds.
W. Hewitt Phillips3
Gilruth went beyond the reports of feel to characterise how the plane should respond to different inputs on the control stick. In other words he quantified that feel of the plane.
Gilrtuth’s work was in the spirit of Lord Kelvin’s quote on measurement
When you can measure what you are speaking about, and express it in numbers, you know something about it, when you cannot express it in numbers, your knowledge is of a meager and unsatisfactory kind; it may be the beginning of knowledge, but you have scarely, in your thoughts advanced to the stage of science.
From Chapter 3, pg 73 of Thomson (1889)
The aim was to convert a qualitative property of aircraft into quantitative measurement, thereby allowing their improvement.
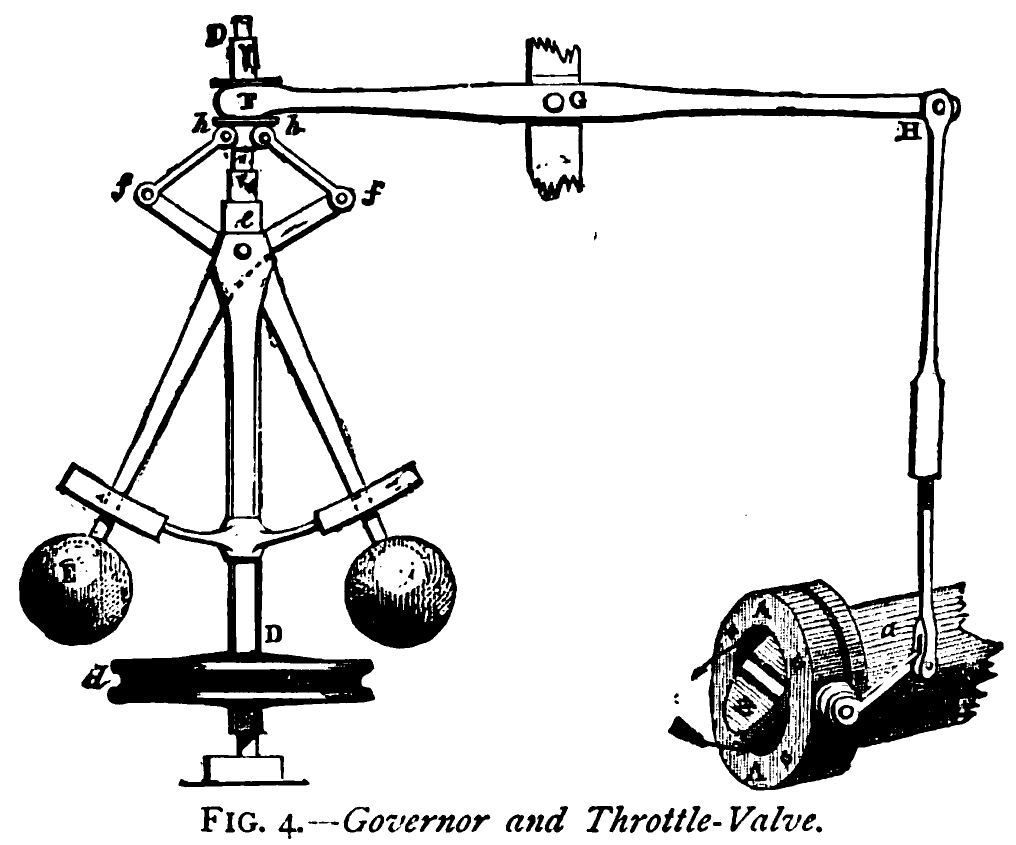
Figure: The centrifugal governor, an early example of a decision-making system. The parameters of the governor include the lengths of the linkages (which effect how far the throttle opens in response to movement in the balls), the weight of the balls (which effects inertia) and the limits of to which the balls can rise.
The evolution of feedback in engineering systems tells us a crucial story about human-machine interaction. Test pilots like Amelia Earhart and Stefan Cavallo developed an intimate understanding of their aircraft through direct physical feedback - the vibrations, the sounds, the feel of the controls. This physical connection allowed for rapid adaptation and learning.
Modern commercial airliners now use fly-by-wire, with the two main manufacturers choosing different routes. Boeing’s system aims to emulate the tactile feedback and forces that would have come from direct connection of the control column to the control surfaces. Airbus’s sytem is a smaller control stick that is flown by one hand and does not feed back to the haptic signals to the pilot.
Physical and Digital Feedback
James Watt’s governor exemplifies this physical intelligence - centrifugal force directly controlling steam flow through mechanical linkages. The feedback loop is immediate, physical, and comprehensible. Modern digital systems, however, have lost this direct connection, replacing it with layers of abstraction between sensing and action.
Physical feedback and digital feedback differ, physical feedback is interpreted through our quick reacting motor intelligence. Digital feedback will be processed by slower reacting systems, although there will still be a spectrum. For example our reaction to being shown a disturbing image or receiving fake news that confirms our prejudices will be slower than a direct motor response but faster than a mathematical puzzle.
See Lawrence (2024) feedback loops p. 117-119, 122-130, 132-133, 140, 145, 152, 177, 180-181, 183-184, 206, 228, 231, 256-257, 263-264, 265, 329.
When Feedback Fails
The contrast between physical and digital feedback becomes stark when we examine modern system failures. While test pilots could feel their aircraft’s responses and adapt accordingly, modern digital systems often fail silently, with consequences that can go undetected for years.
The Horizon Scandal
In the UK we saw these effects play out in the Horizon scandal: the accounting system of the national postal service was computerized by Fujitsu and first installed in 1999, but neither the Post Office nor Fujitsu were able to control the system they had deployed. When it went wrong individual sub postmasters were blamed for the systems’ errors. Over the next two decades they were prosecuted and jailed leaving lives ruined in the wake of the machine’s mistakes.
See Lawrence (2024) Horizon scandal p. 371.
The Horizon scandal and Lorenzo NHS system represent catastrophic failures of digital feedback. Unlike a test pilot who can feel when something is wrong, or Watt’s governor which fails visibly, these digital systems created a false sense of confidence while masking their failures. The human operators - whether post office workers or healthcare professionals - were disconnected from the true state of the system, leading to devastating consequences.
The Lorenzo Scandal
The Lorenzo scandal is the National Programme for IT which was intended to allow the NHS to move towards electronic health records.

{kind=link}
The oral transcript can be found at https://publications.parliament.uk/pa/cm201012/cmselect/cmpubacc/1070/11052302.htm.
One quote from 16:54:33 in the committee discussion captures the top-down nature of the project.
Q117 Austin Mitchell: You said, Sir David, the problems came from the middle range, but surely they were implicit from the start, because this project was rushed into. The Prime Minister [Tony Blair] was very keen, the delivery unit was very keen, it was very fashionable to computerise things like this. An appendix indicating the cost would be £5 billion was missed out of the original report as published, so you have a very high estimate there in the first place. Then, Richard Granger, the Director of IT, rushed through, without consulting the professions. This was a kind of computer enthusiast’s bit, was it not? The professionals who were going to have to work it were not consulted, because consultation would have made it clear that they were going to ask more from it and expect more from it, and then contracts for £1 billion were let pretty well straightaway, in May 2003. That was very quick. Now, why were the contracts let before the professionals were consulted?
An analysis of the problems was published by Justinia (2017). Based on the paper, the key challenges faced in the UK’s National Programme for IT (NPfIT) included:
Lack of adequate end user engagement, particularly with frontline healthcare staff and patients. The program was imposed from the top-down without securing buy-in from stakeholders.
Absence of a phased change management approach. The implementation was rushed without proper planning for organizational and cultural changes.
Underestimating the scale and complexity of the project. The centralized, large-scale approach was overambitious and difficult to manage.
Poor project management, including unrealistic timetables, lack of clear leadership, and no exit strategy.
Insufficient attention to privacy and security concerns regarding patient data.
Lack of local ownership. The centralized approach meant local healthcare providers felt no ownership over the systems.
Communication issues, including poor communication with frontline staff about the program’s benefits.
Technical problems, delays in delivery, and unreliable software.
Failure to recognize the socio-cultural challenges were as significant as the technical ones.
Lack of flexibility to adapt to changing requirements over the long timescale.
Insufficient resources and inadequate methodologies for implementation.
Low morale among NHS staff responsible for implementation due to uncertainties and unrealistic timetables.
Conflicts between political objectives and practical implementation needs.
The paper emphasizes that while technical competence is necessary, the organizational, human, and change management factors were more critical to the program’s failure than purely technological issues. The top-down, centralized approach and lack of stakeholder engagement were particularly problematic.
Reports at the Time
Report https://publications.parliament.uk/pa/cm201012/cmselect/cmpubacc/1070/1070.pdf
This fundamental shift from physical to digital feedback represents one of the greatest challenges in modern engineering: how do we maintain meaningful human understanding and control as our systems become increasingly abstract?
See Lawrence (2024) feedback failure p. 163-168, 189-196, 211-213, 334-336, 340, 342-343, 365-366.
Summary
We’ve looked at the key difference between human and machine in terms of information bandwidth. We’ve seen how we can collaborate to create complex systems through separation of concerns. Engineering feedback gives us an ability to work with tools in a responsive way. In complex digital systems it has become hard to close the feedback loop in a sociotechnical system. When we fail to listen we create brittle systems that impose upon their users and when they fail the human consequences are severe.
Thanks!
For more information on these subjects and more you might want to check the following resources.
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com