Leadership and AI: Strategic Decision Making in the Age of Human-Analogue Machines
Abstract
As AI technologies reshape business landscapes across industries, leaders face fundamental questions about balancing automation with human judgment, managing information flows, and designing organisational decision-making structures. This masterclass builds on the ideas in The Atomic Human to provide MBA students with practical frameworks for understanding AI’s strategic implications through the lens of information topography, decision-making architectures, and human-AI collaboration.
Through a combination of conceptual frameworks, real-world case studies, and interactive exercises, participants will develop the critical thinking tools needed to lead organisations in the age of human-analogue machines. We’ll explore how to strategically implement AI while maintaining human agency, building intelligent accountability, and creating organisational effectiveness in a world where machines increasingly mimic human capabilities.
Welcome and Masterclass Overview
This masterclass is designed for MBA students preparing to lead organisations through the AI transformation. Unlike traditional technology training, we’ll focus on the strategic and organizational challenges that AI creates - challenges that require business leadership rather than technical expertise.
Our journey today will take us from understanding what makes human intelligence unique, through the ways AI is reshaping organisational decision-making, to practical frameworks for strategic AI implementation. Along the way, we’ll engage in exercises that apply these concepts to real organisational challenges you’ll face as business leaders.
Part 1: Understanding Human vs Machine Intelligence
Time: 10:00-10:45 (45 min lecture) - We’ll explore what makes human intelligence unique and how it differs fundamentally from machine intelligence. This foundation is essential for everything that follows.
The Age of Human-Analogue Machines
Henry Ford’s Faster Horse


Figure: A 1925 Ford Model T built at Henry Ford’s Highland Park Plant in Dearborn, Michigan. This example now resides in Australia, owned by the founder of FordModelT.net. From https://commons.wikimedia.org/wiki/File:1925_Ford_Model_T_touring.jpg
It’s said that Henry Ford’s customers wanted a “a faster horse.” If Henry Ford was selling us artificial intelligence today, what would the customer call for, “a smarter human?” That’s certainly the picture of machine intelligence we find in science fiction narratives, but the reality of what we’ve developed is much more mundane.
Car engines produce prodigious power from petrol. Machine intelligences deliver decisions derived from data. In both cases the scale of consumption enables a speed of operation that is far beyond the capabilities of their natural counterparts. Unfettered energy consumption has consequences in the form of climate change. Does unbridled data consumption also have consequences for us?
If we devolve decision making to machines, we depend on those machines to accommodate our needs. If we don’t understand how those machines operate, we lose control over our destiny. Our mistake has been to see machine intelligence as a reflection of our intelligence. We cannot understand the smarter human without understanding the human. To understand the machine, we need to better understand ourselves.
Artificial General Vehicle

Figure: The notion of artificial general intelligence is as absurd as the notion of an artificial general vehicle - no single vehicle is optimal for every journey. (Illustration by Dan Andrews inspired by a conversation about “The Atomic Human” Lawrence (2024))
This illustration was created by Dan Andrews inspired by a conversation about “The Atomic Human” book. The drawing emerged from discussions with Dan about the flawed concept of artificial general intelligence and how it parallels the absurd idea of a single vehicle optimal for all journeys. The vehicle itself is inspired by shared memories of Professor Pat Pending in Hanna Barbera’s Wacky Races.
As we enter an era where machines increasingly mimic tasks traditionally undertaken by humans, leaders face fundamental transformations in how their organisations function. The challenges aren’t merely operational - they require us to reimagine the very nature of work, human capital, and organisational culture.
The Atomic Human
Figure: The Atomic Eye, by slicing away aspects of the human that we used to believe to be unique to us, but are now the preserve of the machine, we learn something about what it means to be human.
The development of what some are calling intelligence in machines, raises questions around what machine intelligence means for our intelligence. The idea of the atomic human is derived from Democritus’s atomism.
In the fifth century bce the Greek philosopher Democritus posed a question about our physical universe. He imagined cutting physical matter into pieces in a repeated process: cutting a piece, then taking one of the cut pieces and cutting it again so that each time it becomes smaller and smaller. Democritus believed this process had to stop somewhere, that we would be left with an indivisible piece. The Greek word for indivisible is atom, and so this theory was called atomism.
The Atomic Human considers the same question, but in a different domain, asking: As the machine slices away portions of human capabilities, are we left with a kernel of humanity, an indivisible piece that can no longer be divided into parts? Or does the human disappear altogether? If we are left with something, then that uncuttable piece, a form of atomic human, would tell us something about our human spirit.
See Lawrence (2024) atomic human, the p. 13.
Our fascination with AI stems from the perceived uniqueness of human intelligence. We believe it’s what differentiates us. But to understand how AI will reshape business, we first need to understand what makes human intelligence unique and how it differs from machine intelligence.
The Embodied Nature of Human Intelligence
The Diving Bell and the Butterfly

Figure: The Diving Bell and the Buttefly is the autobiography of Jean Dominique Bauby.
The Diving Bell and the Butterfly is the autobiography of Jean Dominique Bauby. Jean Dominique, the editor of French Elle magazine, suffered a major stroke at the age of 43 in 1995. The stroke paralyzed him and rendered him speechless. He was only able to blink his left eyelid, he became a sufferer of locked in syndrome.
See Lawrence (2024) Le Scaphandre et le papillon (The Diving Bell and the Butterfly) p. 10–12.
O M D P C F B V
H G J Q Z Y X K W
Figure: The ordering of the letters that Bauby used for writing his autobiography.
How could he do that? Well, first, they set up a mechanism where he could scan across letters and blink at the letter he wanted to use. In this way, he was able to write each letter.
It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
Imagine doing all that thinking, but so little speaking, having all those thoughts and so little ability to communicate.
One challenge for the atomic human is that we are all in that situation. While not as extreme as for Bauby, when we compare ourselves to the machine, we all have a locked-in intelligence.
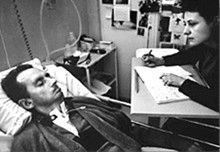
Figure: Jean Dominique Bauby was the Editor in Chief of the French Elle Magazine, he suffered a stroke that destroyed his brainstem, leaving him only capable of moving one eye. Jean Dominique became a victim of locked in syndrome.
Incredibly, Jean Dominique wrote his book after he became locked in. It took him 10 months of four hours a day to write the book. Each word took two minutes to write.
The idea behind embodiment factors is that we are all in that situation. While not as extreme as for Bauby, we all have somewhat of a locked in intelligence.
See Lawrence (2024) Bauby, Jean Dominique p. 9–11, 18, 90, 99-101, 133, 186, 212–218, 234, 240, 251–257, 318, 368–369.
Bauby and Shannon

Figure: Claude Shannon developed information theory which allows us to quantify how much Bauby can communicate. This allows us to compare how locked in he is to us.
See Lawrence (2024) Shannon, Claude p. 10, 30, 61, 74, 98, 126, 134, 140, 143, 149, 260, 264, 269, 277, 315, 358, 363.
Embodiment Factors
|
|
|||
| bits/min | billions | 2000 | 6 |
|
billion calculations/s |
~100 | a billion | a billion |
| embodiment | 20 minutes | 5 billion years | 15 trillion years |
Figure: Embodiment factors are the ratio between our ability to compute and our ability to communicate. Jean Dominique Bauby suffered from locked-in syndrome. The embodiment factors show that relative to the machine we are also locked in. In the table we represent embodiment as the length of time it would take to communicate one second’s worth of computation. For computers it is a matter of minutes, but for a human, whether locked in or not, it is a matter of many millions of years.
Let me explain what I mean. Claude Shannon introduced a mathematical concept of information for the purposes of understanding telephone exchanges.
Information has many meanings, but mathematically, Shannon defined a bit of information to be the amount of information you get from tossing a coin.
If I toss a coin, and look at it, I know the answer. You don’t. But if I now tell you the answer I communicate to you 1 bit of information. Shannon defined this as the fundamental unit of information.
If I toss the coin twice, and tell you the result of both tosses, I give you two bits of information. Information is additive.
Shannon also estimated the average information associated with the English language. He estimated that the average information in any word is 12 bits, equivalent to twelve coin tosses.
So every two minutes Bauby was able to communicate 12 bits, or six bits per minute.
This is the information transfer rate he was limited to, the rate at which he could communicate.
Compare this to me, talking now. The average speaker for TEDX speaks around 160 words per minute. That’s 320 times faster than Bauby or around a 2000 bits per minute. 2000 coin tosses per minute.
But, just think how much thought Bauby was putting into every sentence. Imagine how carefully chosen each of his words was. Because he was communication constrained he could put more thought into each of his words. Into thinking about his audience.
So, his intelligence became locked in. He thinks as fast as any of us, but can communicate slower. Like the tree falling in the woods with no one there to hear it, his intelligence is embedded inside him.
Two thousand coin tosses per minute sounds pretty impressive, but this talk is not just about us, it’s about our computers, and the type of intelligence we are creating within them.
So how does two thousand compare to our digital companions? When computers talk to each other, they do so with billions of coin tosses per minute.
Let’s imagine for a moment, that instead of talking about communication of information, we are actually talking about money. Bauby would have 6 dollars. I would have 2000 dollars, and my computer has billions of dollars.
The internet has interconnected computers and equipped them with extremely high transfer rates.
However, by our very best estimates, computers actually think slower than us.
How can that be? You might ask, computers calculate much faster than me. That’s true, but underlying your conscious thoughts there are a lot of calculations going on.
Each thought involves many thousands, millions or billions of calculations. How many exactly, we don’t know yet, because we don’t know how the brain turns calculations into thoughts.
Our best estimates suggest that to simulate your brain a computer would have to be as large as the UK Met Office machine here in Exeter. That’s a 250 million pound machine, the fastest in the UK. It can do 16 billion billon calculations per second.
It simulates the weather across the word every day, that’s how much power we think we need to simulate our brains.
So, in terms of our computational power we are extraordinary, but in terms of our ability to explain ourselves, just like Bauby, we are locked in.
For a typical computer, to communicate everything it computes in one second, it would only take it a couple of minutes. For us to do the same would take 15 billion years.
If intelligence is fundamentally about processing and sharing of information. This gives us a fundamental constraint on human intelligence that dictates its nature.
I call this ratio between the time it takes to compute something, and the time it takes to say it, the embodiment factor (Lawrence, 2017). Because it reflects how embodied our cognition is.
If it takes you two minutes to say the thing you have thought in a second, then you are a computer. If it takes you 15 billion years, then you are a human.
These bandwidth differences - what I call “embodiment factors” - explain why AI struggles with context and social understanding, the very domains where human leaders excel. The strategic challenge is designing systems that leverage the strengths of both.
Embodiment Factors: Walking vs Light Speed
Imagine human communication as moving at walking pace. The average person speaks about 160 words per minute, which is roughly 2000 bits per minute. If we compare this to walking speed, roughly 1 m/s we can think of this as the speed at which our thoughts can be shared with others.
Compare this to machines. When computers communicate, their bandwidth is 600 billion bits per minute. Three hundred million times faster than humans or the equiavalent of \(3 \times 10 ^{8}\). In twenty minutes we could be a kilometer down the road, where as the computer can go to the Sun and back again..
This difference is not just only about speed of communication, but about embodiment. Our intelligence is locked in by our biology: our brains may process information rapidly, but our ability to share those thoughts is limited to the slow pace of speech or writing. Machines, in comparison, seem able to communicate their computations almost instantaneously, anywhere.
So, the embodiment factor is the ratio between the time it takes to think a thought and the time it takes to communicate it. For us, it’s like walking; for machines, it’s like moving at light speed. This difference means that most direct comparisons between human and machine need to be carefully made. Because for humans not the size of our communication bandwidth that counts, but it’s how we overcome that limitation..
The Conversation: Where Humans Excel
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Embodiment factors imply that, in our communication between humans, what is not said is, perhaps, more important than what is said. To communicate with each other we need to have a model of who each of us are.
To aid this, in society, we are required to perform roles. Whether as a parent, a teacher, an employee or a boss. Each of these roles requires that we conform to certain standards of behaviour to facilitate communication between ourselves.
Control of self is vitally important to these communications.
The consequences between this mismatch of power and delivery are to be seen all around us. Because, just as driving an F1 car with bicycle wheels would be a fine art, so is the process of communication between humans.
If I have a thought and I wish to communicate it, I first need to have a model of what you think. I should think before I speak. When I speak, you may react. You have a model of who I am and what I was trying to say, and why I chose to say what I said. Now we begin this dance, where we are each trying to better understand each other and what we are saying. When it works, it is beautiful, but when mis-deployed, just like a badly driven F1 car, there is a horrible crash, an argument.

Figure: This is the drawing Dan was inspired to create for Chapter 1. It captures the fundamentally narcissistic nature of our (societal) obsession with our intelligence.
See blog post on Dan Andrews image of our reflective obsession with AI.. See also (Vallor, 2024).
Computer Conversations
Figure: Conversation relies on internal models of other individuals.
Figure: Misunderstanding of context and who we are talking to leads to arguments.
Similarly, we find it difficult to comprehend how computers are making decisions. Because they do so with more data than we can possibly imagine.
In many respects, this is not a problem, it’s a good thing. Computers and us are good at different things. But when we interact with a computer, when it acts in a different way to us, we need to remember why.
Just as the first step to getting along with other humans is understanding other humans, so it needs to be with getting along with our computers.
Embodiment factors explain why, at the same time, computers are so impressive in simulating our weather, but so poor at predicting our moods. Our complexity is greater than that of our weather, and each of us is tuned to read and respond to one another.
Their intelligence is different. It is based on very large quantities of data that we cannot absorb. Our computers don’t have a complex internal model of who we are. They don’t understand the human condition. They are not tuned to respond to us as we are to each other.
Embodiment factors encapsulate a profound thing about the nature of humans. Our locked in intelligence means that we are striving to communicate, so we put a lot of thought into what we’re communicating with. And if we’re communicating with something complex, we naturally anthropomorphize them.
We give our dogs, our cats, and our cars human motivations. We do the same with our computers. We anthropomorphize them. We assume that they have the same objectives as us and the same constraints. They don’t.
This means, that when we worry about artificial intelligence, we worry about the wrong things. We fear computers that behave like more powerful versions of ourselves that will struggle to outcompete us.
In reality, the challenge is that our computers cannot be human enough. They cannot understand us with the depth we understand one another. They drop below our cognitive radar and operate outside our mental models.
The real danger is that computers don’t anthropomorphize. They’ll make decisions in isolation from us without our supervision because they can’t communicate truly and deeply with us.
See Lawrence (2024) telepathy p. 248-50. See Lawrence (2024) anthropomorphization (‘anthrox’) p. 30-31, 90-91, 93-4, 100, 132, 148, 153, 163, 216-17, 239, 276, 326, 342.
The true potential of AI in business isn’t in replacing humans but in creating complementary systems that enhance human capabilities. Moving beyond the ‘faster horse’ mindset requires understanding what makes human intelligence uniquely valuable in organisational contexts.
Culture
Cicero suggested that philosophy cultivates the mind. This notion of is vital for how we communicate. Because we have so little bandwidth we rely on shared conceptions of the world to communicate complex subjects.
Blake’s Newton
William Blake’s rendering of Newton captures humans in a particular state. He is trance-like absorbed in simple geometric shapes. The feel of dreams is enhanced by the underwater location, and the nature of the focus is enhanced because he ignores the complexity of the sea life around him.

Figure: William Blake’s Newton. 1795c-1805
See Lawrence (2024) Blake, William Newton p. 121–123.
The caption in the Tate Britain reads:
Here, Blake satirises the 17th-century mathematician Isaac Newton. Portrayed as a muscular youth, Newton seems to be underwater, sitting on a rock covered with colourful coral and lichen. He crouches over a diagram, measuring it with a compass. Blake believed that Newton’s scientific approach to the world was too reductive. Here he implies Newton is so fixated on his calculations that he is blind to the world around him. This is one of only 12 large colour prints Blake made. He seems to have used an experimental hybrid of printing, drawing, and painting.
From the Tate Britain
See Lawrence (2024) Blake, William Newton p. 121–123, 258, 260, 283, 284, 301, 306.
Sistine Chapel Ceiling
Shortly before I first moved to Cambridge, my girlfriend (now my wife) took me to the Sistine Chapel to show me the recently restored ceiling.

Figure: The ceiling of the Sistine Chapel.
When we got to Cambridge, we both attended Patrick Boyde’s talks on chapel. He focussed on both the structure of the chapel ceiling, describing the impression of height it was intended to give, as well as the significance and positioning of each of the panels and the meaning of the individual figures.
The Creation of Adam

Figure: Photo of Detail of Creation of Man from the Sistine chapel ceiling.
One of the most famous panels is central in the ceiling, it’s the creation of man. Here, God in the guise of a pink-robed bearded man reaches out to a languid Adam.
The representation of God in this form seems typical of the time, because elsewhere in the Vatican Museums there are similar representations.

Figure: Photo detail of God.
Photo from https://commons.wikimedia.org/wiki/File:Michelangelo,_Creation_of_Adam_04.jpg.
My colleague Beth Singler has written about how often this image of creation appears when we talk about AI (Singler, 2020).
See Lawrence (2024) Michelangelo, The Creation of Adam p. 7-9, 31, 91, 105–106, 121, 153, 206, 216, 350.
The way we represent this “other intelligence” in the figure of a Zeus-like bearded mind demonstrates our tendency to embody intelligences in forms that are familiar to us.
Lunette Rehoboam Abijah
Many of Blake’s works are inspired by engravings he saw of the Sistine chapel ceiling. The pose of Newton is taken from the Lunette depiction of Abijah, one of the Michelangeo’s ancestors of Christ.

Figure: Lunette containing Rehoboam and Abijah.
Elohim Creating Adam
Blake’s vision of the creation of man, known as Elohim Creating Adam, is a strong contrast to Michelangelo’s. The faces of both God and Adam show deep anguish. The image is closer to representations of Prometheus receiving his punishment for sharing his knowledge of fire than to the languid ecstasy we see in Michelangelo’s representation.

Figure: William Blake’s Elohim Creating Adam.
The caption in the Tate reads:
Elohim is a Hebrew name for God. This picture illustrates the Book of Genesis: ‘And the Lord God formed man of the dust of the ground.’ Adam is shown growing out of the earth, a piece of which Elohim holds in his left hand.
For Blake the God of the Old Testament was a false god. He believed the Fall of Man took place not in the Garden of Eden, but at the time of creation shown here, when man was dragged from the spiritual realm and made material.
From the Tate Britain
Blake’s vision is demonstrating the frustrations we experience when the (complex) real world doesn’t manifest in the way we’d hoped.
See Lawrence (2024) Blake, William Elohim Creating Adam p. 121, 217–18.
We communicate with each other through shared cultural reference points: stories, rituals, and artefacts. Great artworks are not just decoration: they are compressed cultural objects that can carry meaning across centuries.
The Sistine Chapel becomes a kind of public interface: a shared “model” that people can point at, interpret, dispute, and transmit. In that sense, the artwork itself is part of the communication system.



Figure: The creation of Adam and the Lunette of Abijah come to gether to influence Blake’s version of Newton, yet his view of creation is very different from Michelangelo’s.
What’s striking here is how influence works: a pose moves from a Michelangelo lunette into Blake’s Newton; a creation narrative is reinterpreted as anguish in Elohim Creating Adam. These are “links” in a human communication network.
Human communication is not only words passed between individuals. We also communicate through shared artefacts — images, stories, rituals, institutions — that act as a common reference frame. These artefacts stabilise meaning because they persist, they can be revisited, and they can be interpreted together.
This version of the “human culture interacting” diagram grounds the idea in a concrete chain: the Sistine Chapel as a shared cultural object; Michelangelo’s figures as a visual vocabulary; Blake’s Newton borrowing a pose from a lunette; and Blake’s Elohim Creating Adam reinterpreting the creation narrative. In other words: a human communication network made of artefacts.
Figure: Humans use culture, facts and artefacts to communicate.
A Six Word Novel

Figure: Consider the six-word novel, apocryphally credited to Ernest Hemingway, “For sale: baby shoes, never worn.” To understand what that means to a human, you need a great deal of additional context. Context that is not directly accessible to a machine that has not got both the evolved and contextual understanding of our own condition to realize both the implication of the advert and what that implication means emotionally to the previous owner.
See Lawrence (2024) baby shoes p. 368.
But this is a very different kind of intelligence than ours. A computer cannot understand the depth of the Ernest Hemingway’s apocryphal six-word novel: “For Sale, Baby Shoes, Never worn,” because it isn’t equipped with that ability to model the complexity of humanity that underlies that statement.

Figure: This is the drawing Dan was inspired to create for Chapter 4. It highlights how even if these machines can generate creative works the lack of origin in humans menas it is not the same as works of art that come to us through history.
See blog post on Art is Human..
For the Working Group for the Royal Society report on Machine Learning, back in 2016, the group worked with Ipsos MORI to engage in public dialogue around the technology. Ever since I’ve been struck about how much more sensible the conversations that emerge from public dialogue are than the breathless drivel that seems to emerge from supposedly more informed individuals.
There were a number of messages that emerged from those dialogues, and many of those messages were reinforced in two further public dialogues we organised in September.
However, there was one area we asked about in 2017, but we didn’t ask about in 2024. That was an area where the public unequivocal that they didn’t want the research community to pursue progress. Quoting from the report (my emphasis).
Art: Participants failed to see the purpose of machine learning-written poetry. For all the other case studies, participants recognised that a machine might be able to do a better job than a human. However, they did not think this would be the case when creating art, as doing so was considered to be a fundamentally human activity that machines could only mimic at best.
Public Views of Machine Learning, April, 2017
How right they were.
Key Takeaways: Human vs Machine Intelligence
In this first part we’ve outlined the idea of the atomic human, and suggested that our intelligence is defined more by the constraints on humanity rather than our capabilities. What we can’t do. The bandwidth limitation means that that human intelligence is fundamentally embodied. To overcome communication limitations we referred to shared experience, some of which is specific to our context (e.g. limited life) and some of it is specific to the ideas others have shared either today or in the past. That forms our culture. Shared knowledge of this context and culture underpins our ability to communicate.
Businesses and other institutions are part of that culture. They are part of how we overcome individual limitations to operate together in concert. For the next exercise we’re going to be thinking about how information flows through these organisations.
Exercise 1: Mapping An Organisation’s Information Flows
Time: 10:45-11:15 (20 min group work + 10 min plenary) - Apply the concepts to real organisational contexts.
Exercise Instructions:
Working in small groups (3-4 people), map the information flows in an organisation type you (as a group) know well (current employer, previous employer, or case study organisation).
Each group should select ONE type of institution to analyze. Choose from:
- A Start-up - Recently founded, agile, limited resources
- A Government Institution - Public sector, accountability requirements, stable
- An Established Player - Large corporation, existing systems, market leader
- An SME - Small/medium enterprise, specialised, resource-constrained
Characterise what your institution does. If it’s a company, what is their market? If it is public sector what service are they providing?
- What is its core business or mission?
- What are its key activities and processes?
- Who are its stakeholders?
Information Sources: Where does critical information originate in your organisation?
Key Decision Points: Where are the most important decisions made? How are they informed?
Human Bottlenecks: Where does information require human judgment that machines can’t easily replicate?
AI Opportunities: Identify 1-2 places where AI could enhance human decision-making
Deliverable: Simple sketch showing information flows, decision points, and where humans vs machines should work.
Plenary (10 minutes): Each group shares one key insight.
11:15-11:45: Break - 30 minute refreshment break
Part 2: Information Topography and Decision Making
Time: 11:45-12:30 (45 min lecture) - We’ll explore how AI changes organisational information landscapes and decision-making structures.
The Information Revolution in Organisations
New Flow of Information
Classically the field of statistics focused on mediating the relationship between the machine and the human. Our limited bandwidth of communication means we tend to over-interpret the limited information that we are given, in the extreme we assign motives and desires to inanimate objects (a process known as anthropomorphizing). Much of mathematical statistics was developed to help temper this tendency and understand when we are valid in drawing conclusions from data.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
Data science brings new challenges. In particular, there is a very large bandwidth connection between the machine and data. This means that our relationship with data is now commonly being mediated by the machine. Whether this is in the acquisition of new data, which now happens by happenstance rather than with purpose, or the interpretation of that data where we are increasingly relying on machines to summarize what the data contains. This is leading to the emerging field of data science, which must not only deal with the same challenges that mathematical statistics faced in tempering our tendency to over interpret data but must also deal with the possibility that the machine has either inadvertently or maliciously misrepresented the underlying data.
See Lawrence (2024) topography, information p. 34-9, 43-8, 57, 62, 104, 115-16, 127, 140, 192, 196, 199, 291, 334, 354-5. See Lawrence (2024) anthropomorphization (‘anthrox’) p. 30-31, 90-91, 93-4, 100, 132, 148, 153, 163, 216-17, 239, 276, 326, 342.
In an AI-augmented organisation, human attention becomes the most precious resource. The strategic allocation of this attention will determine organisational success. This is particularly critical in business where complex decisions require both algorithmic precision and human judgment.
The Evolution of Organisational Decision Making
Networked Interactions
Our modern society intertwines the machine with human interactions. The key question is who has control over these interfaces between humans and machines.
Figure: Humans and computers interacting should be a major focus of our research and engineering efforts.
So the real challenge that we face for society is understanding which systemic interventions will encourage the right interactions between the humans and the machine at all of these interfaces.
The API Mandate
The API Mandate was a memo issued by Jeff Bezos in 2002. Internet folklore has the memo making five statements:
- All teams will henceforth expose their data and functionality through service interfaces.
- Teams must communicate with each other through these interfaces.
- There will be no other form of inter-process communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
- It doesn’t matter what technology they use.
- All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
The mandate marked a shift in the way Amazon viewed software, moving to a model that dominates the way software is built today, so-called “Software-as-a-Service.”
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
Conway (n.d.)
The law is cited in the classic software engineering text, The Mythical Man Month (Brooks, n.d.).
As a result, and in awareness of Conway’s law, the implementation of this mandate also had a dramatic effect on Amazon’s organizational structure.
Because the design that occurs first is almost never the best possible, the prevailing system concept may need to change. Therefore, flexibility of organization is important to effective design.
Conway (n.d.)
Amazon is set up around the notion of the “two pizza team.” Teams of 6-10 people that can be theoretically fed by two (American) pizzas. This structure is tightly interconnected with the software. Each of these teams owns one of these “services.” Amazon is strict about the team that develops the service owning the service in production. This approach is the secret to their scale as a company, and the approach has been adopted by many other large tech companies. The software-as-a-service approach changed the information infrastructure of the company. The routes through which information is shared. This had a knock-on effect on the corporate culture.
Amazon works through an approach I think of as “devolved autonomy.” The culture of the company is widely taught (e.g. Customer Obsession, Ownership, Frugality), a team’s inputs and outputs are strictly defined, but within those parameters, teams have a great of autonomy in how they operate. The information infrastructure was devolved, so the autonomy was devolved. The different parts of Amazon are then bound together through shared corporate culture.
The way decisions are made in organisations is fundamentally changing. This means rethinking how we balance centralised control with devolved authority, especially in areas like strategy, risk assessment, and customer service.
Understanding Information Topography
An Attention Economy
I don’t know what the future holds, but there are three things that (in the longer term) I think we can expect to be true.
- Human attention will always be a “scarce resource” (See Simon, 1971)
- Humans will never stop being interested in other humans.
- Organisations will keep trying to “capture” the attention economy.
Over the next few years our social structures will be significantly disrupted, and during periods of volatility it’s difficult to predict what will be financially successful. But in the longer term the scarce resource in the economy will be the “capital” of human attention. Even if all traditionally “productive jobs” such as manufacturing were automated, and sustainable energy problems are resolved, human attention is still the bottle neck in the economy. See Simon (1971)
Beyond that, humans will not stop being interested in other humans, sport is a nice example of this, we are as interested in the human stories of athletes as their achievements (as a series of Netflix productions evidences: Quaterback, Receiver, Drive to Survive, THe Last Dance) etc. Or the “creator economy” on YouTube. While we might prefer a future where the labour in such an economy is distributed, such that we all individually can participate in the creation as well as the consumption, my final thought is that there are significant forces to centralise this so that the many consume from the few, and companies will be financially incentivised to capture this emerging attention economy. For more on the attention economy see Tim O’Reilly’s talk here: https://www.mctd.ac.uk/watch-ai-and-the-attention-economy-tim-oreilly/.
Trust, Autonomy and Embodiment
Trust, Autonomy and Embodiment
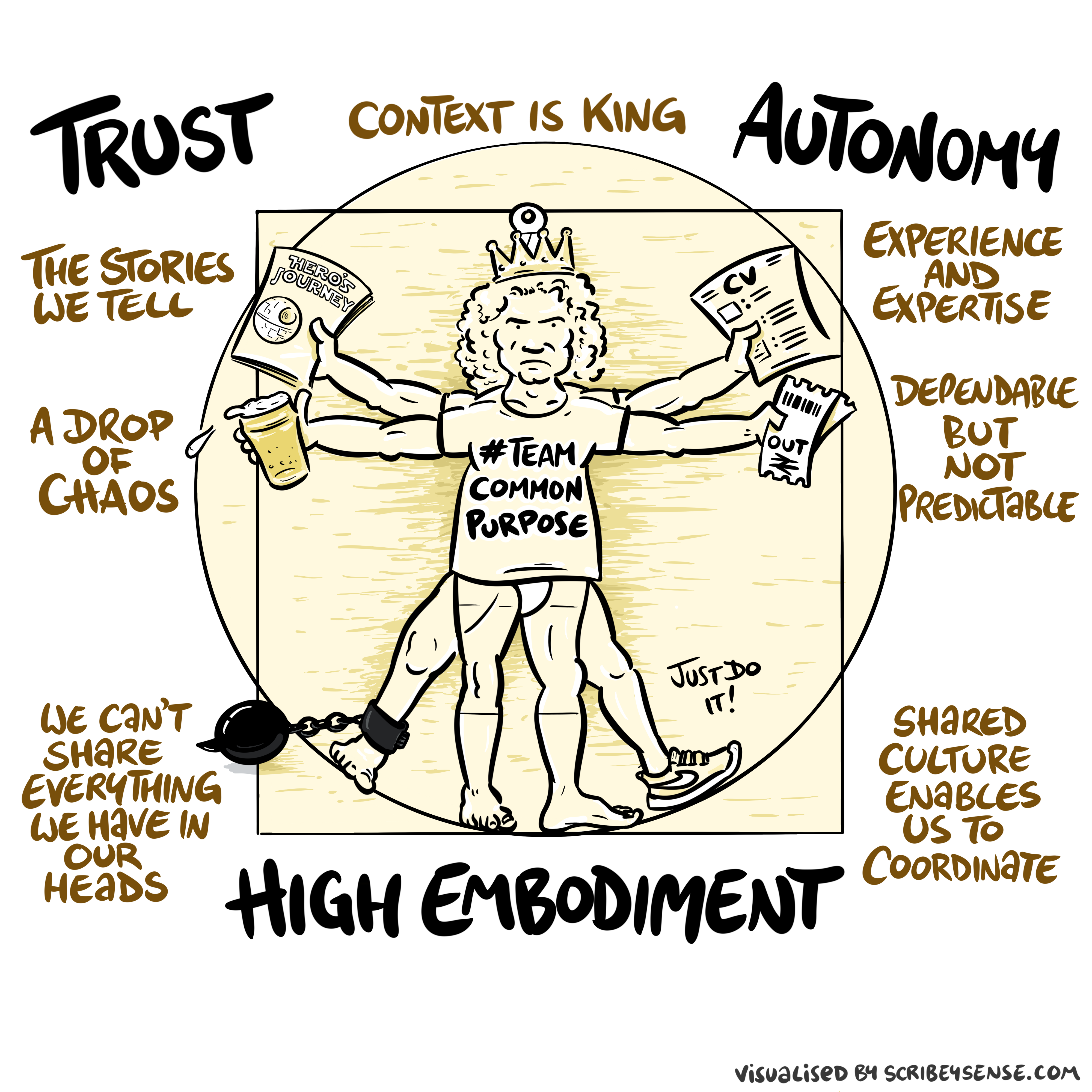
Figure: The relationships between trust, autonomy and embodiment are key to understanding how to properly deploy AI systems in a way that avoids digital autocracy. (Illustration by Dan Andrews inspired by Chapter 3 “Intent” of “The Atomic Human” Lawrence (2024))
This illustration was created by Dan Andrews after reading Chapter 3 “Intent” of “The Atomic Human” book. The chapter explores the concept of intent in AI systems and how trust, autonomy, and embodiment interact to shape our relationship with technology. Dan’s drawing captures these complex relationships and the balance needed for responsible AI deployment.
See blog post on Dan Andrews image from Chapter 3.
Trust is not a slogan; it is the infrastructure that allows autonomy to be devolved without losing control. Autonomy is always conditional: it depends on what information is available, what incentives shape behaviour, and whether escalation and accountability are real. In executive settings, the practical question is: where do we allow delegation (to people or machines), and where do we insist on human judgement and responsibility?
See Lawrence (2024) trust p. 43, 79, 100. See Lawrence (2024) embodiment factor p. 13, 29, 35, 79, 87, 105, 197, 216-217, 249, 269, 327, 353, 363, 369. See Lawrence (2024) topography, information p. 34-9, 43-8, 57, 62, 104, 115-16, 127, 140, 192, 196, 199, 291, 334, 354-5.
See blog post on Dan Andrews image from Chapter 3..
AI changes the information topography of organisations and society - the information topography is the landscape of who knows what, when, and how. Understanding this new landscape is crucial for strategic decision-making.
Balancing Centralised Control with Devolved Authority
Question Mark Emails

Figure: Jeff Bezos sends employees at Amazon question mark emails. They require an explaination. The explaination required is different at different levels of the management hierarchy. See this article.
One challenge at Amazon was what I call the “L4 to Q4 problem.” The issue when an graduate engineer (Level 4 in Amazon terminology) makes a change to the code base that has a detrimental effect but we only discover it when the 4th Quarter results are released (Q4).
The challenge in explaining what went wrong is a challenge in intellectual debt.
Executive Sponsorship
Another lever that can be deployed is that of executive sponsorship. My feeling is that organisational change is most likely if the executive is seen to be behind it. This feeds the corporate culture. While it may be a necessary condition, or at least it is helpful, it is not a sufficient condition. It does not solve the challenge of the institutional antibodies that will obstruct long term change. Here by executive sponsorship I mean that of the CEO of the organisation. That might be equivalent to the Prime Minister or the Cabinet Secretary.
A key part of this executive sponsorship is to develop understanding in the executive of how data driven decision making can help, while also helping senior leadership understand what the pitfalls of this decision making are.
Pathfinder Projects
I do exec education courses for the Judge Business School. One of my main recommendations there is that a project is developed that directly involves the CEO, the CFO and the CIO (or CDO, CTO … whichever the appropriate role is) and operates on some aspect of critical importance for the business.
The inclusion of the CFO is critical for two purposes. Firstly, financial data is one of the few sources of data that tends to be of high quality and availability in any organisation. This is because it is one of the few forms of data that is regularly audited. This means that such a project will have a good chance of success. Secondly, if the CFO is bought in to these technologies, and capable of understanding their strengths and weaknesses, then that will facilitate the funding of future projects.
In the DELVE data report (The DELVE Initiative, 2020), we translated this recommendation into that of “pathfinder projects.” Projects that cut across departments, and involve treasury. Although I appreciate the nuances of the relationship between Treasury and No 10 do not map precisely onto that of CEO and CFO in a normal business. However, the importance of cross cutting exemplar projects that have the close attention of the executive remains.
This balance is particularly critical for modern organisations. You need centralised oversight for strategic alignment and risk management, but you also need devolved decision-making for agility and innovation. AI can help achieve both, but only if properly designed.
Generative AI as Human-Analogue Machines
The MONIAC
The MONIAC was an analogue computer designed to simulate the UK economy. Analogue comptuers work through analogy, the analogy in the MONIAC is that both money and water flow. The MONIAC exploits this through a system of tanks, pipes, valves and floats that represent the flow of money through the UK economy. Water flowed from the treasury tank at the top of the model to other tanks representing government spending, such as health and education. The machine was initially designed for teaching support but was also found to be a useful economic simulator. Several were built and today you can see the original at Leeds Business School, there is also one in the London Science Museum and one in the Unisversity of Cambridge’s economics faculty.

Figure: Bill Phillips and his MONIAC (completed in 1949). The machine is an analogue computer designed to simulate the workings of the UK economy.
See Lawrence (2024) MONIAC p. 232-233, 266, 343.
Donald MacKay

Figure: Donald M. MacKay (1922-1987), a physicist who was an early member of the cybernetics community and member of the Ratio Club.
Donald MacKay was a physicist who worked on naval gun targeting during the Second World War. The challenge with gun targeting for ships is that both the target and the gun platform are moving. This was tackled using analogue computers - for example, in the US the Mark I fire control computer, which was a mechanical computer. MacKay worked on radar systems for gun laying, where the velocity and distance of the target could be assessed through radar and a mechanical-electrical analogue computer.
Fire Control Systems
Naval gunnery systems deal with targeting guns while taking into account movement of ships. The Royal Navy’s Gunnery Pocket Book (The Admiralty, 1945) gives details of one system for gun laying.
Like many challenges we face today, in the second world war, fire control was handled by a hybrid system of humans and computers. This means deploying human beings for the tasks that they can manage, and machines for the tasks that are better performed by a machine. This leads to a division of labour between the machine and the human that can still be found in our modern digital ecosystems.
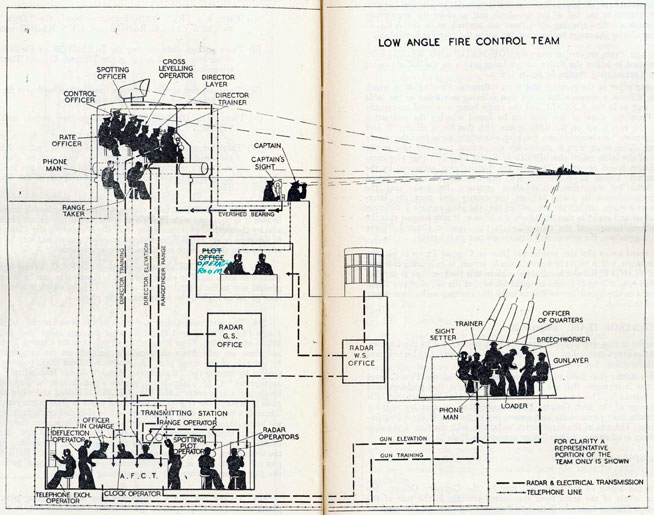
Figure: The fire control computer set at the centre of a system of observation and tracking (The Admiralty, 1945).
As analogue computers, fire control computers from the second world war would contain components that directly represented the different variables that were important in the problem to be solved, such as the inclination between two ships.
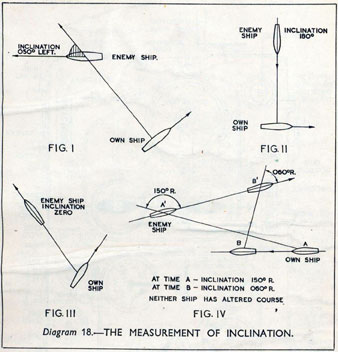
Figure: Measuring inclination between two ships (The Admiralty, 1945). Sophisticated fire control computers allowed the ship to continue to fire while under maneuvers.
The fire control systems were electro-mechanical analogue computers that represented the “state variables” of interest, such as inclination and ship speed with gears and cams within the machine.
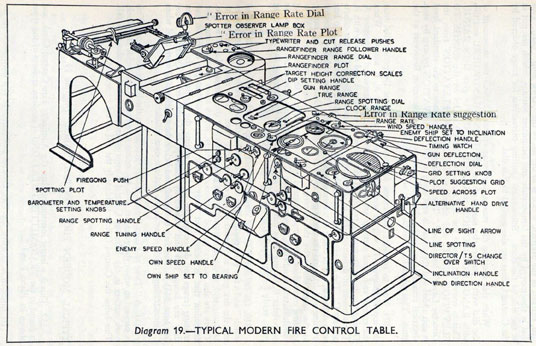
Figure: A second world war gun computer’s control table (The Admiralty, 1945).
For more details on fire control computers, you can watch a 1953 film on the the US the Mark IA fire control computer from Periscope Film.
Behind the Eye

Figure: Behind the Eye (MacKay, 1991) summarises MacKay’s Gifford Lectures, where MacKay uses the operation of the eye as a window on the operation of the brain.
Donald MacKay completed his PhD at King’s College, just down the road from Bill Phillips who was building the MONIAC at LSE. He was part of the Ratio Club - a group of early career scientists interested in communication and control in animals and humans, or more specifically in computers and brains. They were part of an international movement known as cybernetics .
Donald MacKay wrote of the influence that his own work on radar had on his interest in the brain.
… during the war I had worked on the theory of automated and electronic computing and on the theory of information, all of which are highly relevant to such things as automatic pilots and automatic gun direction. I found myself grappling with problems in the design of artificial sense organs for naval gun-directors and with the principles on which electronic circuits could be used to simulate situations in the external world so as to provide goal-directed guidance for ships, aircraft, missiles and the like.
Later in the 1940’s, when I was doing my Ph.D. work, there was much talk of the brain as a computer and of the early digital computers that were just making the headlines as “electronic brains.” As an analogue computer man I felt strongly convinced that the brain, whatever it was, was not a digital computer. I didn’t think it was an analogue computer either in the conventional sense.
But this naturally rubbed under my skin the question: well, if it is not either of these, what kind of system is it? Is there any way of following through the kind of analysis that is appropriate to their artificial automata so as to understand better the kind of system the human brain is? That was the beginning of my slippery slope into brain research.
Behind the Eye pg 40. Edited version of the 1986 Gifford Lectures given by Donald M. MacKay and edited by Valerie MacKay
See Lawrence (2024) MacKay, Donald, Behind the Eye p. 268-270, 316.
MacKay’s distinction between analogue and digital computers is key. As an expert in analogue machines, he understood that an analogue computer is literally an analogue - its components (resistors, capacitors, inductors, or mechanical parts like cams and gears) have states that are physically analogous to the states in system being modeled. Engineers designed these computers by exploiting mathematical dualities between the computer and the real world. For example a mechanical system (mass-spring-damper) and electrical circuit (inductor-resistor-capacitor) could be described by the same second-order differential equations, allowing designers to map real-world problems through mathematics into virtual representations.
MacKay’s insights remain relevant when considering modern AI systems. His questioning of whether the brain was truly digital or analogue might parallel current debates about large language models like Claude and ChatGPT, which seem to operate in ways that don’t neatly fit either paradigm. His work reminds us that understanding the fundamental nature of intelligent systems - whether biological or artificial - requires looking beyond simple categorizations.
Human Analogue Machine
The machine learning systems we have built today that can reconstruct human text, or human classification of images, necessarily must have some aspects to them that are analagous to our understanding. As MacKay suggests the brain is neither a digital or an analogue computer, and the same can be said of the modern neural network systems that are being tagged as “artificial intelligence.”
I believe a better term for them is “human-analogue machines,” because what we have built is not a system that can make intelligent decisions from first principles (a rational approach) but one that observes how humans have made decisions through our data and reconstructs that process. Machine learning is more empiricist than rational, but now we have an empirical approach that distils our evolved intelligence.
HAMs are not representing states of the outside world with analogous states inside the machine, they are also not (directly) processing digital states through logic gates to draw their conclusions (although they are implemented on digital computers that do this to enable them to update).
Figure: The human analogue machine creates a feature space which is analagous to that we use to reason, one way of doing this is to have a machine attempt to compress all human generated text in an auto-regressive manner.
Heider and Simmel (1944)
Figure: Fritz Heider and Marianne Simmel’s video of shapes from Heider and Simmel (1944).
Fritz Heider and Marianne Simmel’s experiments with animated shapes from 1944 (Heider and Simmel, 1944). Our interpretation of these objects as showing motives and even emotion is a combination of our desire for narrative, a need for understanding of each other, and our ability to empathize. At one level, these are crudely drawn objects, but in another way, the animator has communicated a story through simple facets such as their relative motions, their sizes and their actions. We apply our psychological representations to these faceless shapes to interpret their actions (Heider, 1958).
See also a recent review paper on Human Cooperation by Henrich and Muthukrishna (2021). See Lawrence (2024) psychological representation p. 326–329, 344–345, 353, 361, 367.
The perils of developing this capability include counterfeit people, a notion that the philosopher Daniel Dennett has described in The Atlantic. This is where computers can represent themselves as human and fool people into doing things on that basis.
See Lawrence (2024) human-analogue machine p. 343–5, 346–7, 358–9, 365–8.
LLM Conversations
Figure: The focus so far has been on reducing uncertainty to a few representative values and sharing numbers with human beings. We forget that most people can be confused by basic probabilities for example the prosecutor’s fallacy.
As far back as 2022 researchers in robotics have suggested inner monologues for LLMs. See for example the paper Inner Monologue: Embodied Reasoning through Planning Huang et al. (2023). That’s now widespread through chain of thought approaches.
Figure: The Inner Monologue paper suggests using LLMs for robotic planning (Huang et al., 2023).
By interacting directly with machines that have an understanding of human cultural context, these machines share the nature of uncertainty in the same way humans do.
Intellectual Debt
Figure: Jonathan Zittrain’s term to describe the challenges of explanation that come with AI is Intellectual Debt.
In the context of machine learning and complex systems, Jonathan Zittrain has coined the term “Intellectual Debt” to describe the challenge of understanding what you’ve created. In the ML@CL group we’ve been foucssing on developing the notion of a data-oriented architecture to deal with intellectual debt (Cabrera et al., 2023).
Zittrain points out the challenge around the lack of interpretability of individual ML models as the origin of intellectual debt. In machine learning I refer to work in this area as fairness, interpretability and transparency or FIT models. To an extent I agree with Zittrain, but if we understand the context and purpose of the decision making, I believe this is readily put right by the correct monitoring and retraining regime around the model. A concept I refer to as “progression testing.” Indeed, the best teams do this at the moment, and their failure to do it feels more of a matter of technical debt rather than intellectual, because arguably it is a maintenance task rather than an explanation task. After all, we have good statistical tools for interpreting individual models and decisions when we have the context. We can linearise around the operating point, we can perform counterfactual tests on the model. We can build empirical validation sets that explore fairness or accuracy of the model.
See Lawrence (2024) intellectual debt p. 84, 85, 349, 365.
But if we can avoid the pitfalls of counterfeit people, this also offers us an opportunity to psychologically represent (Heider, 1958) the machine in a manner where humans can communicate without special training. This in turn offers the opportunity to overcome the challenge of intellectual debt.
Despite the lack of interpretability of machine learning models, they allow us access to what the machine is doing in a way that bypasses many of the traditional techniques developed in statistics. But understanding this new route for access is a major new challenge.
HAM
The Human-Analogue Machine or HAM therefore provides a route through which we could better understand our world through improving the way we interact with machines.
Figure: The trinity of human, data, and computer, and highlights the modern phenomenon. The communication channel between computer and data now has an extremely high bandwidth. The channel between human and computer and the channel between data and human is narrow. New direction of information flow, information is reaching us mediated by the computer. The focus on classical statistics reflected the importance of the direct communication between human and data. The modern challenges of data science emerge when that relationship is being mediated by the machine.
The HAM can provide an interface between the digital computer and the human allowing humans to work closely with computers regardless of their understandin gf the more technical parts of software engineering.
Figure: The HAM now sits between us and the traditional digital computer.
Of course this route provides new routes for manipulation, new ways in which the machine can undermine our autonomy or exploit our cognitive foibles. The major challenge we face is steering between these worlds where we gain the advantage of the computer’s bandwidth without undermining our culture and individual autonomy.
See Lawrence (2024) human-analogue machine (HAMs) p. 343-347, 359-359, 365-368.
The new challenge for business leaders is that we know our current approaches to digital systems are totally inappropriate, but we don’t yet know exactly how they’re insufficient. This requires experimentation and adaptive strategy rather than rigid planning.
Bandwidth vs Complexity
The computer communicates in Gigabits per second, One way of imagining just how much slower we are than the machine is to look for something that communicates in nanobits per second.

|
|||
| bits/min | \(100 \times 10^{-9}\) | \(2,000\) | \(600 \times 10^9\) |
Figure: When we look at communication rates based on the information passing from one human to another across generations through their genetics, we see that computers watching us communicate is roughly equivalent to us watching organisms evolve. Estimates of germline mutation rates taken from Scally (2016).
Figure: Bandwidth vs Complexity.
The challenge we face is that while speed is on the side of the machine, complexity is on the side of our ecology. Many of the risks we face are associated with the way our speed undermines our ecology and the machines speed undermines our human culture.
See Lawrence (2024) Human evolution rates p. 98-99. See Lawrence (2024) Psychological representation of Ecologies p. 323-327.

Figure: This is the drawing Dan was inspired to create for Chapter 12. It captures the challenge the analogy where the speed of information assimilation associated with machines is related to the speed assimilation associated with humans.
See blog post on the launch of Facebook’s AI lab..
Exercise 2: SWOT Analysis for AI Transformation
Time: 12:30-13:00 (20 min group work + 10 min plenary) - Analyse your institution’s position for AI adoption.
Exercise Instructions:
Each group should select ONE type of institution to analyze (you’ll return to this in Exercise 4). Choose from:
- A Start-up - Recently founded, agile, limited resources
- A Government Institution - Public sector, accountability requirements, stable
- An Established Player - Large corporation, existing systems, market leader
- An SME - Small/medium enterprise, specialized, resource-constrained
For your chosen institution type, conduct a SWOT analysis specifically focused on AI adoption:
Strengths: - What advantages does this type of institution have for AI adoption? - What existing capabilities can they leverage?
Weaknesses: - What disadvantages or constraints do they face? - What capabilities are they missing?
Opportunities: - Where could AI create the most value for this type? - What new markets, efficiencies or capabilities could AI unlock?
Threats: - What are the risks of AI adoption? - What are the risks of NOT adopting AI? - Who are the competitors and what are they doing?
Deliverable: Create a simple SWOT matrix on one page. Be specific to your institution type - a startup’s SWOT will look very different from a government institution’s!
Note: Keep this analysis - you’ll build on it in Exercise 4 this afternoon.
13:00-14:30: Lunch Break - 90 minutes with homework assignment.
Part 3: Maintaining Human Judgment and Building Trust
Time: 14:30-15:15 (45 min lecture) - We’ll examine critical cases where algorithmic systems have failed and develop frameworks for maintaining human judgment and trust.
When Algorithms Override Human Judgment: The Horizon Scandal
The Horizon Scandal
In the UK we saw these effects play out in the Horizon scandal: the accounting system of the national postal service was computerized by Fujitsu and first installed in 1999, but neither the Post Office nor Fujitsu were able to control the system they had deployed. When it went wrong individual sub postmasters were blamed for the systems’ errors. Over the next two decades they were prosecuted and jailed leaving lives ruined in the wake of the machine’s mistakes.
See Lawrence (2024) Horizon scandal p. 371.
Judgement in the AI and Data Era
The Big Data Paradox
The big data paradox is the modern phenomenon of “as we collect more data, we understand less.” It is emerging in several domains, political polling, characterization of patients for trials data, monitoring twitter for political sentiment.
I like to think of the phenomenon as relating to the notion of “can’t see the wood for the trees.” Classical statistics, with randomized controlled trials, improved society’s understanding of data. It improved our ability to monitor the forest, to consider population health, voting patterns etc. It is critically dependent on active approaches to data collection that deal with confounders. This data collection can be very expensive.
In business today, it is still the gold standard, A/B tests are used to understand the effect of an intervention on revenue or customer capture or supply chain costs.

Figure: New beech leaves growing in the Gribskov Forest in the northern part of Sealand, Denmark. Photo from wikimedia commons by Malene Thyssen, http://commons.wikimedia.org/wiki/User:Malene.
The new phenomenon is happenstance data. Data that is not actively collected with a question in mind. As a result, it can mislead us. For example, if we assume the politics of active users of twitter is reflective of the wider population’s politics, then we may be misled.
However, this happenstance data often allows us to characterise a particular individual to a high degree of accuracy. Classical statistics was all about the forest, but big data can often become about the individual tree. As a result we are misled about the situation.
The phenomenon is more dangerous, because our perception is that we are characterizing the wider scenario with ever increasing accuracy. Whereas we are just becoming distracted by detail that may or may not be pertinent to the wider situation.
This is related to our limited bandwidth as humans, and the ease with which we are distracted by detail. The data-inattention-cognitive-bias.
Big Model Paradox
The big data paradox has a sister: the big model paradox. As we build more and more complex models, we start believing that we have a high-fidelity representation of reality. But the complexity of reality is way beyond our feeble imaginings. So we end up with a highly complex model, but one that falls well short in terms of reflecting reality. The complexity of the model means that it moves beyond our understanding.
Complexity in Action
As an exercise in understanding complexity, watch the following video. You will see the basketball being bounced around, and the players moving. Your job is to count the passes of those dressed in white and ignore those of the individuals dressed in black.
Figure: Daniel Simon’s famous illusion “monkey business.” Focus on the movement of the ball distracts the viewer from seeing other aspects of the image.
In a classic study Simons and Chabris (1999) ask subjects to count the number of passes of the basketball between players on the team wearing white shirts. Fifty percent of the time, these subjects don’t notice the gorilla moving across the scene.
The phenomenon of inattentional blindness is well known, e.g in their paper Simons and Charbris quote the Hungarian neurologist, Rezsö Bálint,
It is a well-known phenomenon that we do not notice anything happening in our surroundings while being absorbed in the inspection of something; focusing our attention on a certain object may happen to such an extent that we cannot perceive other objects placed in the peripheral parts of our visual field, although the light rays they emit arrive completely at the visual sphere of the cerebral cortex.
Rezsö Bálint 1907 (translated in Husain and Stein 1988, page 91)
When we combine the complexity of the world with our relatively low bandwidth for information, problems can arise. Our focus on what we perceive to be the most important problem can cause us to miss other (potentially vital) contextual information.
This phenomenon is known as selective attention or ‘inattentional blindness.’
Figure: For a longer talk on inattentional bias from Daniel Simons see this video.
Setup
notutils
This small package is a helper package for various notebook utilities used below.
The software can be installed using
import importlib.utilfrom the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/notutils
Once notutils is installed, it can be imported in the usual manner.
import notutilspods
In Sheffield we created a suite of software tools for ‘Open Data Science.’ Open data science is an approach to sharing code, models and data that should make it easier for companies, health professionals and scientists to gain access to data science techniques.
You can also check this blog post on Open Data Science.
The software can be installed using
cmd = install_command('pods')%system {cmd}from the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/ods
Once pods is installed, it can be imported in the usual manner.
import podsmlai
The mlai software is a suite of helper functions for teaching and demonstrating machine learning algorithms. It was first used in the Machine Learning and Adaptive Intelligence course in Sheffield in 2013.
The software can be installed using
cmd = install_command('mlai')%system {cmd}from the command prompt where you can access your python installation.
The code is also available on GitHub: https://github.com/lawrennd/mlai
Once mlai is installed, it can be imported in the usual manner.
import mlai
from mlai import plotData Selective Attention Bias
We are going to see how inattention biases can play out in data analysis by going through a simple example. The analysis involves body mass index and activity information.
BMI Steps Data
The BMI Steps example is taken from Yanai and Lercher (2020). We are given a data set of body-mass index measurements against step counts. For convenience we have packaged the data so that it can be easily downloaded.
import podsdata = pods.datasets.bmi_steps()
X = data['X']
y = data['Y']It is good practice to give our variables interpretable names so that the analysis may be clearly understood by others. Here the steps count is the first dimension of the covariate, the bmi is the second dimension and the gender is stored in y with 1 for female and 0 for male.
steps = X[:, 0]
bmi = X[:, 1]
gender = y[:, 0]We can check the mean steps and the mean of the BMI.
print('Steps mean is {mean}.'.format(mean=steps.mean()))print('BMI mean is {mean}.'.format(mean=bmi.mean()))BMI Steps Data Analysis
We can also separate out the means from the male and female populations. In python this can be done by setting male and female indices as follows.
male_ind = (gender==0)
female_ind = (gender==1)And now we can extract the variables for the two populations.
male_steps = steps[male_ind]
male_bmi = bmi[male_ind]And as before we compute the mean.
print('Male steps mean is {mean}.'.format(mean=male_steps.mean()))print('Male BMI mean is {mean}.'.format(mean=male_bmi.mean()))Similarly, we can get the same result for the female portion of the populaton.
female_steps = steps[female_ind]
female_bmi = bmi[female_ind]print('Female steps mean is {mean}.'.format(mean=female_steps.mean()))print('Female BMI mean is {mean}.'.format(mean=female_bmi.mean()))Interesting, the female BMI average is slightly higher than the male BMI average. The number of steps in the male group is higher than that in the female group. Perhaps the steps and the BMI are anti-correlated. The more steps, the lower the BMI.
Python provides a statistics package. We’ll import this in python so that we can try and understand the correlation between the steps and the BMI.
from scipy.stats import pearsonrcorr, _ = pearsonr(steps, bmi)
print("Pearson's overall correlation: {corr}".format(corr=corr))
male_corr, _ = pearsonr(male_steps, male_bmi)
print("Pearson's correlation for males: {corr}".format(corr=male_corr))
female_corr, _ = pearsonr(female_steps, female_bmi)
print("Pearson's correlation for females: {corr}".format(corr=female_corr))A Hypothesis as a Liability
This analysis is from an article titled “A Hypothesis as a Liability” (Yanai and Lercher, 2020), they start their article with the following quite from Herman Hesse.
“ ‘When someone seeks,’ said Siddhartha, ‘then it easily happens that his eyes see only the thing that he seeks, and he is able to find nothing, to take in nothing. […] Seeking means: having a goal. But finding means: being free, being open, having no goal.’ ”
Hermann Hesse
Their idea is that having a hypothesis can constrain our thinking. However, in answer to their paper Felin et al. (2021) argue that some form of hypothesis is always necessary, suggesting that a hypothesis can be a liability
My view is captured in the introductory chapter to an edited volume on computational systems biology that I worked on with Mark Girolami, Magnus Rattray and Guido Sanguinetti.

Figure: Quote from Lawrence (2010) highlighting the importance of interaction between data and hypothesis.
Popper nicely captures the interaction between hypothesis and data by relating it to the chicken and the egg. The important thing is that these two co-evolve.
Number Theatre
Unfortunately, we don’t always have time to wait for this process to converge to an answer we can all rely on before a decision is required.
Not only can we be misled by data before a decision is made, but sometimes we can be misled by data to justify the making of a decision. David Spiegelhalter refers to the phenomenon of “Number Theatre” in a conversation with Andrew Marr from May 2020 on the presentation of data.
Figure: Professor Sir David Spiegelhalter on Andrew Marr on 10th May 2020 speaking about some of the challengers around data, data presentation, and decision making in a pandemic. David mentions number theatre at 9 minutes 10 seconds.
Data Theatre
Data Theatre exploits data inattention bias to present a particular view on events that may misrepresents through selective presentation. Statisticians are one of the few groups that are trained with a sufficient degree of data skepticism. But it can also be combatted through ensuring there are domain experts present, and that they can speak freely.
Figure: The phenomenon of number theatre or data theatre was described by David Spiegelhalter and is nicely summarized by Martin Robbins in this sub-stack article https://martinrobbins.substack.com/p/data-theatre-why-the-digital-dashboards.
Sir David Spiegelhalter
The statistician’s craft is based on humility in front of data and developing the appropriate skeptical thinking around conclusions from data. The best individual I’ve seen at conveying and developing that sense is Sir David Spiegelhalter.
The Art of Statistics

Figure: The Art of Statistics by David Spiegelhalter is an excellent read on the pitfalls of data interpretation.
The Art of Statistics (Spiegelhalter, 2019) brings important examples from statistics to life in an intelligent and entertaining way. It is highly readable and gives an opportunity to fast-track towards the important skill of data-skepticism that is the mark of a professional statistician.
The Art of Uncertainty
David has also released a new book that focusses on Uncertainty.

See (Spiegelhalter, 2024)
Increasing Need for Human Judgment
Figure: Diane Coyle’s Fitzwilliam Lecture where she emphasises as data increases, human judgment is more needed.
The domain of human judgment is increasing.
How these firms use knowledge. How do they generate ideas?
Technical Debt
In computer systems the concept of technical debt has been surfaced by authors including Sculley et al. (2015). It is an important concept, that I think is somewhat hidden from the academic community, because it is a phenomenon that occurs when a computer software system is deployed.
See Lawrence (2024) intellectual debt p. 84-85, 349, 365, 376.
Lean Startup Methodology
In technology, there is the notion of a “minimum viable product” (MVP). Sometimes called “minimum loveable product” (MLP). A minimum viable product is the smallest thing that you need to ship to test your commercial idea. There is a methodology known as the “lean start-up” methodology, where you use the least effort to create your machine learning model is deployed.
The idea is that you should build the quickest thing possible to test your market and see if your idea works. Only when you know your idea is working should you invest more time and personnel in the software.
Unfortunately, there is a tension between deploying quickly and deploying a maintainable system. To build an MVP you deploy quickly, but if the system is successful you take a ‘maintenance hit’ in the future because you’ve not invested early in the right maintainable design for your system.
You save on engineer time at the beginning, but you pay it back with high interest when you need a much higher operations load once the system is deployed.
The notion of the Sculley paper is that there are particular challenges for machine learning models around technical debt.
The Mythical Man-month
.jpg)
Figure: The Mythical Man-month (Brooks, n.d.) is a 1975 book focussed on the challenges of software project coordination.
However, when managing systems in production, you soon discover maintenance of a rapidly deployed system is not your only problem.
To deploy large and complex software systems, an engineering approach known as “separation of concerns” is taken. Frederick Brooks’ book “The Mythical Man-month” (Brooks, n.d.), has itself gained almost mythical status in the community. It focuses on what has become known as Brooks’ law “adding manpower to a late software project makes it later.”
Adding people (men or women!) to a project delays it because of the communication overhead required to get people up to speed.
Separation of Concerns
To construct such complex systems an approach known as “separation of concerns” has been developed. The idea is that you architect your system, which consists of a large-scale complex task, into a set of simpler tasks. Each of these tasks is separately implemented. This is known as the decomposition of the task.
This is where Jonathan Zittrain’s beautifully named term “intellectual debt” rises to the fore. Separation of concerns enables the construction of a complex system. But who is concerned with the overall system?
Technical debt is the inability to maintain your complex software system. Intellectual debt is the inability to explain your software system.
It is right there in our approach to software engineering. “Separation of concerns” means no one is concerned about the overall system itself.
See Lawrence (2024) separation of concerns p. 84-85, 103, 109, 199, 284, 371.
Dealing with Intellectual Debt
What we Did at Amazon
Corporate culture turns out to be an important component of how you can react to digital transformation. Amazon is a company that likes to take a data driven approach. It has a corporate culture that is set up around data-driven decision making. In particular customer obsession and other leadership principles help build a cohesive approach to how data is assimilated.
Amazon has 14 leadership principles in total, but two I found to be particularly useful are called right a lot and dive deep.
Are Right a Lot
Leaders are right a lot. They have strong judgment and good instincts. They seek diverse perspectives and work to disconfirm their beliefs.
I chose “right a lot” because of the the final sentence. Many people find this leadership princple odd because how can you be ‘right a lot.’ Well, I think it’s less about being right, but more about how you interact with those around you. Seeking diverse perspectives and working to disconfirm your beliefs. One of my favourite aspects of Amazon was how new ideas are presented. They are presented in the form of a document that is discussed. There is a particular writing style where claims in the document need to be backed up with evidence, often in the form of data. Importantly, when these documents are produced, they are read in silence at the beginning of the meeting. When everyone has finished reading, the most junior person speaks first. Senior leaders speak last. This is one approach to ensuring that a diverse range of perspectives are heard. It is this sort of respect that needs to be brought to complex decisions around data.
Dive Deep
Leaders operate at all levels, stay connected to the details, audit frequently, and are skeptical when metrics and anecdote differ. No task is beneath them.
I chose “dive deep” because of the last phrase of the second sentence. Amazon is suggesting that leaders “are skeptical when metrics and anecdote differ.” This phrase is vitally important, data inattention bias means that there’s a tendency to ‘miss the gorilla.’ The gorilla is often your own business instinct and/or domain expertise or that of others. If the data you are seeing contradicts the anecdotes you are hearing, this is a clue that something may be wrong. Your data skepticism should be on high alert. This leadership principle is teaching us how to mediate between ‘seeing the forest’ and ‘seeing the tree.’ It warns us to look for inconsistencies between what we’re hearing about the individual tree and teh wider forest.
Understanding your own corporate culture, and what levers you have at your disposal, is a key component of bringing the right approach to data driven decision making.
These challenges can be particularly difficult if your organisation is dominated by operational concerns. If rapid decision making is required, the Gorilla may be missed. And this may be mostly OK, for example, in Amazon’s supply chain there are weekly business reviews that are looking at the international state of the supply chain. If there are problems, they often need quick actions to rectify them. When quick actions are required, ‘command and control’ tends to predominate over more collaorative decision making that we hope allows us to see the Gorilla. Unfortunately, it can be hard, even as senior leaders, to switch between this type of operational decision making, and the more inclusive decision making we need around complex data scenarios. One possibility is to reserve a day for meetings that are dealing with the more complex decision making. In Amazon later in the week was more appropriate for this type of meeting. So making, e.g. Thursday into a more thoughtful day (Thoughtsday if you will?) you can potentially switch modes of thinking and take a longer term view on a given day in the week.
What we did in DELVE
The DELVE initiative was a UK Royal Society response to the 2020 Covid19 pandemic. It fed into the UK Government’s SAGE committee. It was constructed to have a diversity of scientific and economic expertise. The details of the initiative are can be found at https://rs-delve.github.io/.
Delve Timeline
The Delve initiative was a group convened by the Royal Society to help provide data-driven insights about the pandemic, with an initial focus on exiting the first lockdown and particular interest in using the variation of strategies across different international governments to inform policy.
The first contact about the initiative being set up was 3rd April 2020, the first meeting was 7th April and then the first working group was 16th April.
Right from the start, data was at the heart of what DELVE does, but the reality is that little can be done without domain expertise and often the data we required wasn’t available.
However, even when it is not present, the notion of what data might be needed can also have a convening effect, bringing together multiple disciplines around the policy questons at hand. The Delve Data Readiness report (The DELVE Initiative, 2020) makes recommendations for how we can improve our processes around data, but this talk also focuses on how data brings different disciplines together around data.
Any policy question can be framed in a number of different ways - what are the health outcomes; what is the impact on NHS capacity; how are different groups affected; what is the economic impact – and each has different types of evidence associated with it. Complex and uncertain challenges require efforts to draw insights together from across disciplines.
Data as a Convener
To improve communication, we need to ‘externalise cognition’: have objects that are outside our brains, are persistent in the real world, that we can combine with our individual knowledge. Doing otherwise leaves us imagining the world as our personal domain-utopias, ignoring the ugly realities of the way things actual progress.
Data can provide an excellent convener, because even if it doesn’t exist it allows conversations to occur about what data should or could exist and how it might allow us to address the questions of importance.
Models, while also of great potential value in externalising cognition, can be two complex to have conversations about and they can entrench beliefs, triggering model induced blindness (a variation on Kahneman’s theory induced blindness (Kahneman, 2011)).
Figure: Models can also be used to externalise cognition, but if the model is highly complex it’s difficult for two individuals to understand each others’ models. This shuts down conversation, often “mathematical intimidation” is used to shut down a line of questioning. This is highly destructive of the necessary cognitive diversity.
Bandwidth constraints on individuals mean that they tend to focus on their own specialism. This can be particularly problematic for those on the more theoretical side, because mathematical models are complex, and require a lot of deep thought. However, when communicating with others, unless they have the same in depth experience of mathematical modelling as the theoreticians, the models do not bring about good information coherence. Indeed, many computational models themselves are so complex now that no individual can understand the model whole.
Figure: Data can be queried, but the simplest query, what data do we need? Doesn’t even require the data to exist. It seems data can be highly effective for convening a multidisciplinary conversation.
Fritz Heider referred to happenings that are “psychologically represented in each of the participants” (Heider, 1958) as a prerequisite for conversation. Data is a route to that psychological representation.
Note: my introduction to Fritz Heider was through a talk by Nick Chater in 2010, you can read Nick’s thoughts on these issues in his book, The Mind is Flat (Chater, 2019).
For more on the experience of giving advice to government during a pandemic see this talk.
Intellectual Debt and Superficial Automation
Superficial Automation
The rise of AI has enabled automation of many surface-level tasks - what we might call “superficial automation.” These are tasks that appear complex but primarily involve reformatting or restructuring existing information, such as converting bullet points into prose, summarizing documents, or generating routine emails.
While such automation can increase immediate productivity, it risks missing the deeper value of these seemingly mundane tasks. For example, the process of composing an email isn’t just about converting thoughts into text - it’s about:
- Reflection time to properly consider the message
- Building relationships through personal communication
- Developing and refining ideas through the act of writing
- Creating institutional memory through thoughtful documentation
- Projecting corporate culture
When we automate these superficial aspects, we can create what appears to be a more efficient process, but one that gradually loses meaning without human involvement. It’s like having a meeting transcription without anyone actually attending the meeting - the words are there, but the value isn’t.
Consider email composition: An AI can convert bullet points into a polished email instantly, but this bypasses the valuable thinking time that comes with composition. The human “pause” in communication isn’t inefficiency - it’s often where the real value lies.
This points to a broader challenge with AI automation: the need to distinguish between tasks that are merely complex (and can be automated) versus those that are genuinely complicated (requiring human judgment and involvement). Effective deployment of AI requires understanding this distinction and preserving the human elements that give business processes their true value.
The risk is creating what appears to be a more efficient system but is actually a hollow process - one that moves faster but creates less real value. True digital transformation isn’t about removing humans from the loop, but about augmenting human capabilities while preserving the essential human elements that give work its meaning and effectiveness.

Figure: Public dialogue held in Liverpool alongside the 2024 Labour Party Conference. The process of discussion is as important as the material discussed. In line with previous dialogues attendees urged us to develop technology where AI operates as a tool for human augmentation, not replacement.
In our public dialogues we saw the same theme: good process can drive purpose. Discussion is as important as the conclusions reached. Attendees urged us to develop technology where AI operates as a tool for human augmentation, not replacement.
Superficial automation that makes things quicker for the individual but undermines the organisation is a particular problem. If everyone has a team of agents they manage to do their work, but the team of agents doesn’t interact with the wider ecosystem, then knowledge becomes more siloed. This increases intellectual debt.
When the information topography is being disrupted we need to make sure we are taking in a broad spectrum of opinons. The approach of “do as I say” can be effective when there’s certainty and a need for an aligned resource. But in domains of uncertainty learning from the wider team becomes key. Leaders must supress their tendency to express their dominance, and create safe spaces to better understand how the business is reacting.
Conclusion
See the Gorilla don’t be the Gorilla.

Figure: A famous quote from Mike Tyson before his fight with Evander Holyfield: “Everyone has a plan until they get punched in the mouth.” Don’t let the gorilla punch you in the mouth. See the gorilla, but don’t be the gorilla. Photo credit: https://www.catersnews.com/stories/animals/go-ape-unlucky-photographer-gets-punched-by-lairy-gorilla-drunk-from-eating-bamboo-shoots/
See Lawrence (2024) Tyson, Mike p. 92–93, 130, 193, 217, 225, 328, 348.
Exercise 3: The Horizon Scandal - Judgment Failures and Power Asymmetries
Time: 15:15-15:45 (20 min group discussion + 10 min plenary) - Analyse the Horizon scandal you read about at lunch.
Exercise Instructions:
The Horizon scandal at the UK Post Office represents one of the most significant failures of algorithmic governance in modern business history. Working in your groups, analyse this case through the lens of organisational decision-making:
The Situation:
- Horizon accounting system had bugs that created phantom shortfalls
- Post Office prosecuted hundreds of sub-postmasters for theft/fraud
- Human testimony (from sub-postmasters) was systematically discounted
- Computer evidence was treated as infallible
- Lives were destroyed, some sub-postmasters imprisoned
- Took nearly 20 years for truth to emerge
- Failures of Judgment:
- What were the critical moments when human judgment should have overridden the system?
- Why didn’t it happen?
- What organisational culture enabled this failure?
- Power Asymmetries:
- How did power imbalances between the Post Office, the digital systems, accountants, lawyers, politicians and sub-postmasters contribute?
- Why was computer evidence trusted over human testimony?
- Who had voice and who didn’t?
- Information Suppression:
- How was information about system problems suppressed?
- What were the organisational incentives to ignore warnings?
- Lessons for Your Institution:
- Could this happen in your organisation (from Exercise 2)?
- What specific safeguards would prevent it?
- How would you ensure diverse voices can raise concerns?
Deliverable: Identify 2-3 specific governance mechanisms that could have prevented this failure.
15:45-16:15: Break - 30 minute refreshment break
Part 4: Strategic Implementation and the Attention Economy
Time: 16:15-17:00 (45 min lecture) - Strategic frameworks for AI implementation, focusing on the attention economy and people-first approaches.
Human Attention as Strategic Resource
The Attention Economy
Human intelligence is locked-in. It’s bandwidth restricted. This makes it a bottleneck in the attention economy.
Herbert Simon on Information
What information consumes is rather obvious: it consumes the attention of its recipients. Hence a wealth of information creates a poverty of attention …
Simon (1971)
The attention economy was a phenomenon described in 1971 by the American computer scientist Herbert Simon. He saw the coming information revolution and wrote that a wealth of information would create a poverty of attention. Too much information means that human attention becomes the scarce resource, the bottleneck. It becomes the gold in the attention economy.
The power associated with control of information dates back to the invention of writing. By pressing reeds into clay tablets Sumerian scribes stored information and controlled the flow of information.
Revolution
Arguably the information revolution we are experiencing is unprecedented in history. But changes in the way we share information have a long history. Over 5,000 years ago in the city of Uruk, on the banks of the Euphrates, communities which relied on the water to irrigate their corps developed an approach to recording transactions in clay. Eventually the system of recording system became sophisticated enough that their oral histories could be recorded in the form of the first epic: Gilgamesh.
See Lawrence (2024) cuneiform p. 337, 360, 390.

Figure: Chicago Stone, side 2, recording sale of a number of fields, probably from Isin, Early Dynastic Period, c. 2600 BC, black basalt
It was initially developed for people as a record of who owed what to whom, expanding individuals’ capacity to remember. But over a five hundred year period writing evolved to become a tool for literature as well. More pithily put, writing was invented by accountants not poets (see e.g. this piece by Tim Harford).
In some respects today’s revolution is different, because it involves also the creation of stories as well as their curation. But in some fundamental ways we can see what we have produced as another tool for us in the information revolution.
The Future of Professions

Figure: The Future of Professions (Susskind and Susskind, 2015) is a 2015 book focussed on how the next wave of technology revolution is going to effect the professions.
Richard and Daniel Susskind’s 2015 book foresaw that the next wave of automation, artificial intelligence, would have an effect on professional work, information work. And that looks likely to be the case. But professionals are typically well educated and can adapt to changes in their circumstances. For example stocks have already been revolutionised by algorithmic trading, businesses and individuals have adapted to those changes.
From Philosopher’s Stone to AGI
The philosopher’s stone was a mythical substance that could convert base metals to gold. Before modern chemistry, alchemists like Isaac Newton dedicated time to searching for this transformative substance. Today, we recognize this as a misguided scientific foray, much like perpetual motion machines or cold fusion.
Philosopher’s Stone

Figure: The Alchemist by Joseph Wright of Derby (1771). The picture depicts Hennig Brand discovering the element phosphorus when searching for the Philosopher’s Stone.
The philosopher’s stone is a mythical substance that can convert base metals to gold.
The term artificial general intelligence builds on the notion of general intelligence that originated with Charles Spearman’s work in the early 20th century Spearman (1904). Spearman’s work was part of a wider attempt to quantify intelligence in the same way we quantify height - an approach connected to eugenics and Francis Galton’s book “Hereditary Genius” Galton (1869).
There are general principles underlying intelligence, but the notion of a rankable form of intelligence where one entity dominates all others is fundamentally flawed. Yet it is this notion that underpins the modern idea of artificial general intelligence.
To understand the flaws, consider the concept of an “artificial general vehicle” - a vehicle that would dominate all other vehicles in all circumstances, regardless of whether you’re traveling from Nairobi to Nyeri or just to the end of your road. While there are general principles of transportation, the idea of a single vehicle that would be optimal in all situations is absurd. Similarly, intelligence is composed of various capabilities that are appropriate in different contexts, not a single formula that dominates in all respects.
Human Capital Index
The World Bank’s human capital index is one area where many European countries are leading international economy, or at least an area where they currently outperform both the USA and China. The index is a measure of education and health of a population.
Technological progress disrupts existing systems. A new social contract is needed to smooth the transition and guard against rising inequality. Significant investments in human capital throughout a person’s lifecycle are vital to this effort.
World Bank (2019)]
In the 2020 version of the index, the UK was ranked 11th, Italy 30th, US 35th and China 45th.
Productivity Flywheel
Figure: The productivity flywheel suggests technical innovation is reinvested.
The productivity flywheel should return the gains released by productivity through funding. This relies on the economic value mapping the underlying value.
In an AI-augmented organisation, human attention becomes the most precious resource. The strategic allocation of this attention will determine organisational success. This is particularly critical in business where complex decisions require both algorithmic precision and human judgment.
Inflation of Human Capital
This transformation creates efficiency. But it also devalues the skills that form the backbone of human capital and create a happy, healthy society. Had the alchemists ever discovered the philosopher’s stone, using it would have triggered mass inflation and devalued any reserves of gold. Similarly, our reserve of precious human capital is vulnerable to automation and devaluation in the artificial intelligence revolution. The skills we have learned, whether manual or mental, risk becoming redundant in the face of the machine.
AI cannot replace atomic human
Figure: Opinion piece in the FT that describes the idea of a social flywheel to drive the targeted growth we need in AI innovation.
The organisations that will succeed in the AI age will not be those that most aggressively automate, but those that most thoughtfully integrate human and machine intelligence to create systems greater than the sum of their parts.
The Attention Flywheel: Reinvesting Human Capital
Attention Reinvestment Cycle
Figure: The attention flywheel focusses on reinvesting human capital.
While the traditional productivity flywheel focuses on reinvesting financial capital, the attention flywheel focuses on reinvesting human capital - our most precious resource in an AI-augmented world. This requires deliberately creating systems that capture the value of freed attention and channel it toward human-centered activities that machines cannot replicate.
While the traditional productivity flywheel focuses on reinvesting financial capital, the attention flywheel focuses on reinvesting human capital - our most precious resource in an AI-augmented world. This requires deliberately creating systems that capture the value of freed attention and channel it toward human-centered activities that machines cannot replicate.
The Attention Flywheel Mechanism:
- AI automates routine tasks → Frees human attention
- Freed attention directed to high-value human activities → Innovation, relationships, complex judgment
- High-value human activities generate competitive advantage → Market differentiation
- Competitive advantage generates resources → Investment in better AI and human development
- Cycle accelerates → Compound growth in organisational capability
The key is ensuring freed attention doesn’t just dissipate or get consumed by low-value activities. It requires intentional organisational design.
Emulsion: Combining Human and Machine Intelligence
Organizations are like an emulsion mixing oil and water. The machine component could be replaced by better technology, but the human component - the vital, life-giving element - cannot be easily separated or substituted. Successful organisations need to develop structures that combine human and machine intelligence in stable, productive ways.
This means reversing the power dynamics and ensuring the organisation remains in touch with its business differentiators, because in the long run those differentiators are unlikely to include AI - they’ll include the human elements that AI cannot replicate.
Example: Data Science Africa
Data Science Africa is a grass roots initiative that focuses on capacity building to develop ways of solving on the ground problems in health, education, transport and conservation in way that is grounded in local needs and capabilities.
Data Science Africa
Figure: Data Science Africa https://datascienceafrica.org is a ground up initiative for capacity building around data science, machine learning and artificial intelligence on the African continent.
Figure: Data Science Africa meetings held up to October 2021.
Data Science Africa is a bottom up initiative for capacity building in data science, machine learning and artificial intelligence on the African continent.
As of June 2025 there have been thirteen workshops and schools, located in seven different countries: Nyeri, Kenya (three times); Kampala, Uganda; Arusha, Tanzania (twice); Abuja, Nigeria; Addis Ababa, Ethiopia; Accra, Ghana; Kampala, Uganda and Kimberley, South Africa (virtual), Kigali, Rwanda and Ibadan, Nigeria.
DSA Ibadan, Nigeria
Figure: Organiser’s video from Data Science Africa held in Ibadan, Nigeria from 2nd to 6th June 2025
The main notion is end-to-end data science. For example, going from data collection in the farmer’s field to decision making in the Ministry of Agriculture. Or going from malaria disease counts in health centers to medicine distribution.
The philosophy is laid out in (Lawrence, 2015). The key idea is that the modern information infrastructure presents new solutions to old problems. Modes of development change because less capital investment is required to take advantage of this infrastructure. The philosophy is that local capacity building is the right way to leverage these challenges in addressing data science problems in the African context.
Data Science Africa is now a non-govermental organization registered in Kenya. The organising board of the meeting is entirely made up of scientists and academics based on the African continent.
Figure: The lack of existing physical infrastructure on the African continent makes it a particularly interesting environment for deploying solutions based on the information infrastructure. The idea is explored more in this Guardian op-ed on Guardian article on How African can benefit from the data revolution.
Guardian article on Data Science Africa
Example: Cambridge Approach
ai@cam is the flagship University mission that seeks to address these challenges. It recognises that development of safe and effective AI-enabled innovations requires this mix of expertise from across research domains, businesses, policy-makers, civil society, and from affected communities. AI@Cam is setting out a vision for AI-enabled innovation that benefits science, citizens and society.
ai@cam
The ai@cam vision is being achieved in a manner that is modelled on other grass roots initiatives like Data Science Africa. Through leveraging the University’s vibrant interdisciplinary research community. ai@cam has formed partnerships between researchers, practitioners, and affected communities that embed equity and inclusion. It is developing new platforms for innovation and knowledge transfer. It is delivering innovative interdisciplinary teaching and learning for students, researchers, and professionals. It is building strong connections between the University and national AI priorities.

We are working across the University to empower the diversity of expertise and capability we have to focus on these broad societal problems. In April 2022 we shared an ai@cam with a vision document that outlines these challenges for the University.
The University operates as both an engine of AI-enabled innovation and steward of those innovations.
AI is not a universal remedy. It is a set of tools, techniques and practices that correctly deployed can be leveraged to deliver societal benefit and mitigate social harm.
The initiative was funded in November 2022 where a £5M investment from the University.
The progress made so far has been across the University community. We have successfully engaged with over members spanning more than 30 departments and institutes, bringing together academics, researchers, start-ups, and large businesses to collaborate on AI initiatives. The program has already supported 6 new funding bids and launched five interdisciplinary A-Ideas projects that bring together diverse expertise to tackle complex challenges. The establishment of the Policy Lab has created a crucial bridge between research and policy-making. Additionally, through the Pioneer program, we have initiated 46 computing projects that are helping to build our technical infrastructure and capabilities.
How ai@cam is Addressing Innovation Challenges
1. Bridging Macro and Micro Levels
Challenge: There is often a disconnect between high-level AI research and real-world needs that must be addressed.
The A-Ideas Initiative represents an effort to bridge this gap by funding interdisciplinary projects that span 19 departments across 6 schools. This ensures diverse perspectives are brought to bear on pressing challenges. Projects focusing on climate change, mental health, and language equity demonstrate how macro-level AI capabilities can be effectively applied to micro-level societal needs.
Challenge: Academic insights often fail to translate into actionable policy changes.
The Policy Lab initiative addresses this by creating direct connections between researchers, policymakers, and the public, ensuring academic insights can influence policy decisions. The Lab produces accessible policy briefs and facilitates public dialogues. A key example is the collaboration with the Bennett Institute and Minderoo Centre, which resulted in comprehensive policy recommendations for AI governance.
2. Addressing Data, Compute, and Capability Gaps
Challenge: Organizations struggle to balance data accessibility with security and privacy concerns.
The data intermediaries initiative establishes trusted entities that represent the interests of data originators, helping to establish secure and ethical frameworks for data sharing and use. Alongside approaches for protecting data we need to improve our approach to processing data. Careful assessment of data quality and organizational data maturity ensures that data can be shared and used effectively. Together these approaches help to ensure that data can be used to serve science, citizens and society.
2. Addressing data, Compute and Capability Gaps
Challenge: Many researchers lack access to necessary computational resources for modern research.
The HPC Pioneer Project addresses this by providing access to the Dawn supercomputer, enabling 46 diverse projects across 20 departments to conduct advanced computational research. This democratization of computing resources ensures that researchers from various disciplines can leverage high-performance computing for their work. The ai@cam project also supports the ICAIN initiative, further strengthening the computational infrastructure available to researchers with a particular focus on emerging economies.
Challenge: There is a significant skills gap in applying AI across different academic disciplines.
The Accelerate Programme for Scientific Discovery addresses this through a comprehensive approach to building AI capabilities. Through a tiered training system that ranges from basic to advanced levels, the programme ensures that domain experts can develop the AI skills relevant to their field. The initiative particularly emphasizes peer-to-peer learning creating sustainable communities of practice where researchers can share knowledge and experiences through “AI Clubs.”
The Accelerate Programme
Figure: The Accelerate Programme for Scientific Discovery covers research, education and training, engagement. Our aim is to bring about a step change in scientific discovery through AI. http://science.ai.cam.ac.uk
We’re now in a new phase of the development of computing, with rapid advances in machine learning. But we see some of the same issues – researchers across disciplines hope to make use of machine learning, but need access to skills and tools to do so, while the field machine learning itself will need to develop new methods to tackle some complex, ‘real world’ problems.
It is with these challenges in mind that the Computer Lab has started the Accelerate Programme for Scientific Discovery. This new Programme is seeking to support researchers across the University to develop the skills they need to be able to use machine learning and AI in their research.
To do this, the Programme is developing three areas of activity:
- Research: we’re developing a research agenda that develops and applies cutting edge machine learning methods to scientific challenges, with three Accelerate Research fellows working directly on issues relating to computational biology, psychiatry, and string theory. While we’re concentrating on STEM subjects for now, in the longer term our ambition is to build links with the social sciences and humanities.
Progress so far includes:
Recruited a core research team working on the application of AI in mental health, bioinformatics, healthcare, string theory, and complex systems.
Created a research agenda and roadmap for the development of AI in science.
Funded interdisciplinary projects, e.g. in first round:
Antimicrobial resistance in farming
Quantifying Design Trade-offs in Electricity-generation-focused Tokamaks using AI
Automated preclinical drug discovery in vivo using pose estimation
Causal Methods for Environmental Science Workshop
Automatic tree mapping in Cambridge
Acoustic monitoring for biodiversity conservation
AI, mathematics and string theory
Theoretical, Scientific, and Philosophical Perspectives on Biological Understanding in the age of Artificial Intelligence
AI in pathology: optimising a classifier for digital images of duodenal biopsies
Teaching and learning: building on the teaching activities already delivered through University courses, we’re creating a pipeline of learning opportunities to help PhD students and postdocs better understand how to use data science and machine learning in their work.
Progress so far includes:
Teaching and learning
Brought over 250 participants from over 30 departments through tailored data science and machine learning for science training (Data Science Residency and Machine Learning Academy);
Convened workshops with over 80 researchers across the University on the development of data pipelines for science;
Delivered University courses to over 100 students in Advanced Data Science and Machine Learning and the Physical World.
Online training course in Python and Pandas accessed by over 380 researchers.
Engagement: we hope that Accelerate will help build a community of researchers working across the University at the interface on machine learning and the sciences, helping to share best practice and new methods, and support each other in advancing their research. Over the coming years, we’ll be running a variety of events and activities in support of this.
Progress so far includes:
- Launched a Machine Learning Engineering Clinic that has supported over 40 projects across the University with MLE troubleshooting and advice;
- Hosted and participated in events reaching over 300 people in Cambridge;
- Led international workshops at Dagstuhl and Oberwolfach, convening over 60 leading researchers;
- Engaged over 70 researchers through outreach sessions and workshops with the School of Clinical Medicine, the Faculty of Education, Cambridge Digital Humanities and the School of Biological Sciences.
3. Stakeholder Engagement and Feedback Mechanisms
Challenge: AI development often proceeds without adequate incorporation of public perspectives and concerns.
Our public dialogue work, conducted in collaboration with the Kavli Centre for Ethics, Science, and the Public, creates structured spaces for public dialogue about AI’s potential benefits and risks. The approach ensures that diverse voices and perspectives are heard and considered in AI development.
Challenge: AI initiatives often fail to align with diverse academic needs across institutions.
Cross-University Workshops serve as vital platforms for alignment, bringing together faculty and staff from different departments to discuss AI teaching and learning strategies. By engaging professional services staff, the initiative ensures that capability building extends beyond academic departments to support staff who play key roles in implementing and maintaining AI systems.
4. Flexible and Adaptable Approaches
Challenge: Traditional rigid, top-down research agendas often fail to address real needs effectively.
The AI-deas Challenge Development program empowers researchers to identify and propose challenge areas based on their expertise and understanding of field needs. Through collaborative workshops, these initial ideas are refined and developed, ensuring that research directions emerge organically from the academic community while maintaining alignment with broader strategic goals.
5. Phased Implementation and Realistic Planning
Challenge: Ambitious AI initiatives often fail due to unrealistic implementation timelines and expectations.
The overall strategy emphasizes careful, phased deployment to ensure sustainable success. Beginning with pilot programs like AI-deas and the Policy Lab, the approach allows for testing and refinement of methods before broader implementation. This measured approach enables the incorporation of lessons learned from early phases into subsequent expansions.
6. Independent Oversight and Diverse Perspectives
Challenge: AI initiatives often lack balanced guidance and oversight from diverse perspectives.
The Steering Group provides crucial oversight through representatives from various academic disciplines and professional services. Working with a cross-institutional team, it ensures balanced decision-making that considers multiple perspectives. The group maintains close connections with external initiatives like ELLIS, ICAIN, and Data Science Africa, enabling the university to benefit from and contribute to broader AI developments.
7. Addressing the Innovation Supply Chain
Challenge: Academic innovations often struggle to connect with and address industry needs effectively.
The Industry Engagement initiative develops meaningful industrial partnerships through collaboration with the Strategic Partnerships Office, helping translate research into real-world solutions. The planned sciencepreneurship initiative aims to create a structured pathway from academic research to entrepreneurial ventures, helping ensure that innovations can effectively reach and benefit society.
Innovation Economy Conclusion
ai@cam’s approach aims to address the macro-micro disconnects in AI innovation through several key strategies. We are building bridges between macro and micro levels, fostering interdisciplinary collaboration, engaging diverse stakeholders and voices, and providing crucial resources and training. Through these efforts, ai@cam is working to create a more integrated and effective AI innovation ecosystem.
Our implementation approach emphasizes several critical elements learned from past IT implementation failures. We focus on flexibility to adapt to changing needs, phased rollout of initiatives to manage risk, establishing continuous feedback loops for improvement, and maintaining a learning mindset throughout the process.
Looking to the future, we recognize that AI technologies and their applications will continue to evolve rapidly. This evolution requires strategic agility and a continued focus on effective implementation. We will need to remain adaptable, continuously assessing and adjusting our strategies while working to bridge capability gaps between high-level AI capabilities and on-the-ground implementation challenges.
Developing Board-Level Digital Literacy
Business leaders must lead in developing digital literacy at the board level to ensure governance structures can effectively oversee AI implementation while maintaining appropriate human oversight. This doesn’t mean boards need to become technical experts - it means they need frameworks for asking the right questions about AI systems and their organisational impacts.
Exercise 4: Developing Institutional AI Strategies
Time: 17:00-17:30 (20 min group work + 10 min plenary) - Build your institution’s AI strategy using your SWOT analysis from Exercise 2.
Final Synthesis Exercise:
Return to the institution type you analyzed in Exercise 2 (startup, government, established player, or SME). Using your SWOT analysis as the foundation, develop a concrete AI strategy for that institution.
For your institution type, address:
1. Define Your Institution: - What does this institution actually do? (core business/mission) - What are its main activities and processes? - Who are its key stakeholders?
2. AI Strategy Based on Your SWOT: - Leverage Strengths: How do your identified strengths enable specific AI applications? - Address Weaknesses: What capabilities must you build first? - Seize Opportunities: Pick 1-2 high-impact AI opportunities from your SWOT - Mitigate Threats: What governance prevents the risks you identified?
2. Human-Machine Collaboration Design:
- For your chosen AI opportunity:
- What should AI do?
- What must humans continue to do?
- How do they interact?
3. Implementation Priorities:
- First step in next 3 months
- Second step in next 6 months
- Third step in next year
- One key risk and mitigation
Deliverable: One-page strategy document showing: - Institution type and core business - Chosen AI opportunity (from SWOT) - Human-machine collaboration model - Three-step implementation roadmap - Key governance mechanism
Plenary (10 min): Each institution type presents (2 min each) - one startup, one government, one established player, one SME if we have all four represented.
Conclusion: Architecting Human-Machine Collaboration

Figure: This is the drawing Dan was inspired to create for Chapter 11. It captures the core idea in our tendency to devolve complex decisions to what we perceive as greater authorities, but what are in reality ill equipped to deliver a human response.
See blog post on Playing in People’s Backyards..
In the past when decisions became too difficult, we invoked higher powers in the forms of gods, and “trial by ordeal.” Today we face a similar challenge with AI. When a decision becomes difficult there is a danger that we hand it to the machine, but it is precisely these difficult decisions that need to contain a human element.
Wicked Problems

Figure: Society faces many wicked problems in health, education, security, and social care that require carefully deploying AI toward meaningful societal challenges rather than focusing on commercially appealing applications. (Illustration by Dan Andrews inspired by the Epilogue of “The Atomic Human” Lawrence (2024))
This illustration was created by Dan Andrews after reading the Epilogue of “The Atomic Human” book. The Epilogue discusses how we might deploy AI to address society’s most pressing challenges, and Dan’s drawing captures the various wicked problems we face and some of the initiatives that are looking to address them.
See blog post on Who is Stepping Up?.
Final Reflection:
The future of business in the AI age is not about choosing between humans and machines - it’s about creating systems that leverage the best of both. The organisations that will thrive will be those that understand that human attention, judgment, creativity, and relationships remain the most valuable assets, even as AI becomes ubiquitous.
As MBA graduates and future business leaders, your role is not to maximise automation but to architect organisations where human and machine intelligence combine to create value that neither could generate alone. This requires:
- Strategic thinking about what should and shouldn’t be automated
- Organisational design that preserves human judgment and agency
- Cultural leadership that maintains trust and ethics
- Adaptive learning as we discover what works and what doesn’t
- Courage to prioritize long-term human capital over short-term efficiency
The AI revolution is not just a technological challenge - it’s a leadership challenge. And leadership is uniquely human.
Further Reading and Resources
The Atomic Human

{kind=link}
{kind=link}
Additional Resources:
- ai@cam: University of Cambridge initiative on AI (www.ai.cam.ac.uk)
- The Alan Turing Institute: UK’s national institute for data science and AI
- Partnership on AI: Multi-stakeholder organization working on AI best practices
End Time: 17:30 - Thank you for your engagement throughout the day!
Thanks!
For more information on these subjects and more you might want to check the following resources.
- company: Trent AI
- book: The Atomic Human
- twitter: @lawrennd
- podcast: The Talking Machines
- newspaper: Guardian Profile Page
- blog: http://inverseprobability.com